损失
神经网络分类器的分类损失
描述
L.=损失(Mdl那Tbl那ResponseVarName)Mdl使用表中的预测数据Tbl的类标签ResponseVarName表变量。
L.默认情况下,作为表示分类错误的标量值返回。
L.=损失(___那名称,价值)
例子
神经网络的测试集分类误差
计算神经网络分类器的测试集分类误差。
加载患者数据集。从数据集创建一个表。每一行对应一个病人,每一列对应一个诊断变量。使用吸烟者变量作为响应变量,其余变量作为预测变量。
加载患者TBL =表(舒张,收缩,性别,身高,体重,年龄,吸烟者);
将数据分为培训集tblTrain和一个测试集TBLTEST.通过使用分层的抵抗层分区。该软件为测试数据集保留大约30%的观察值,并将其余的观察值用于训练数据集。
rng(“默认值”)分区再现性的%c = cvpartition(资源描述。抽烟,“坚持”, 0.30);trainingIndices =培训(c);testIndices =测试(c);tblTrain =(资源(trainingIndices:);tblTest =(资源(testIndices:);
使用训练集训练神经网络分类器。指定吸烟者列的tblTrain作为响应变量。指定以标准化数值预测值。
mdl = fitcnet(tbltrain,“吸烟者”那...“标准化”,真正的);
计算测试集分类错误。分类错误是神经网络分类器的默认损失类型。
测试仪错误=损失(Mdl、tblTest、,“吸烟者”)
testerror = 0.0671.
testAccuracy = 1 - TestError
testAccuracy = 0.9329
神经网络模型正确地分类了大约93%的测试集观测值。
选择要包含在神经网络分类器中的特征
通过比较测试集分类边距、边、错误和预测来执行特征选择。将使用所有预测器训练的模型的测试集度量与仅使用预测器子集训练的模型的测试集度量进行比较。
加载示例文件fisheriris.csv,其中包含虹膜数据,包括萼片长度、萼片宽度、花瓣长度、花瓣宽度和物种类型。将文件读入表格。
fishertable = readtable (“fisheriris.csv”);
将数据分为培训集三弦和一个测试集testTbl通过使用分层的抵抗层分区。该软件为测试数据集保留大约30%的观察值,并将其余的观察值用于训练数据集。
rng(“默认值”) c = cvpartition(钓鱼台。物种,“坚持”,0.3); trainTbl=fishertable(培训(c),:);testTbl=fishertable(测试(c),:);
使用训练集中的所有预测器训练一个神经网络分类器,并使用除此之外的所有预测器训练另一个分类器瓣宽.对于两种模型,请指定物种作为响应变量,并标准化预测器。
allMdl=fitcnet(列车),“物种”那“标准化”,对);子TMDL=设备网(列车),“种~ SepalLength + SepalWidth + PetalLength”那...“标准化”,真正的);
计算两个模型的测试集分类边距。由于测试集仅包含45个观察值,因此使用条形图显示边距。
对于每个观察,分类裕度是真实类的分类分数与虚假类的最大分数之间的差异。由于神经网络分类器返回分类分数,这是后验概率的分类,因为接近1的边缘值表示自信的分类和负边距值表示错误分类。
平铺布局(2,1)%顶轴ax₁= nexttile;allMargins =利润率(allMdl testTbl);栏(ax₁,allMargins)包含(ax₁“观察”)ylabel(ax1,“利润”)标题(ax₁,“所有预测因素”)%底部轴ax2 = nexttile;subsetMargins =利润率(subsetMdl testTbl);栏(ax2 subsetMargins)包含(ax2,“观察”)ylabel(ax2,“利润”)标题(ax2,“预测因子子集”)

比较两个模型的测试集分类边缘或分类边缘的平均值。
allEdge=edge(所有MDL、测试TBL)
allEdge = 0.8198
子集合= Edge(Subsetmdl,testtbl)
子集= 0.9556.
基于测试集分类边界和边缘,在预测子集中训练的模型似乎优于在所有预测子上训练的模型。
比较两种模型的测试集分类误差。
allError=损失(allMdl,testTbl);allAccuracy=1-allError
平均精度=0.9111
subseterror =损失(subsetmdl,testtbl);subsetAccuracy = 1-auberroror
subsetAccuracy = 0.9778
同样,仅使用预测因子子集训练的模型似乎比使用所有预测因子训练的模型性能更好。
使用混淆矩阵可视化测试集分类结果。
allLabels=predict(allMdl,testTbl);figure confusionchart(testTbl.Species,allLabels)标题(“所有预测因素”)

subsetLabels=预测(subsetMdl,testTbl);图2:混淆图(测试物种、亚热带)标题(“预测因子子集”)

使用所有预测器训练的模型会错误分类四个测试集观测值。使用预测器子集训练的模型只会错误分类一个测试集观测值。
给定两个模型的测试集性能,考虑使用使用所有预测器训练的模型,除了瓣宽.
输入参数
更多关于
分类损失
分类损失函数测量分类模型的预测不准确性。当你在许多模型中比较同一类型的损失时,损失越低表明预测模型越好。
考虑以下场景。
L.是加权平均分类损失。
N是样本大小。
对于二进制分类:
yj是观察到的类标签。软件将其编码为–1或1,表示负类或正类(或中的第一类或第二类)
Classnames.财产),分别。F(Xj)是观察的正类分类分数(row)j预测数据的X.
mj=yjF(Xj)是分类观察的分类分数j进入对应的课程yj.正值mj表示正确的分类,对平均损失贡献不大。的负值mj指出错误的分类,并对平均损失有很大的贡献。
对于支持多类分类的算法(即,金宝appK.≥ 3.):
yj*是一个向量K.–1个零,1位于与真实观察等级对应的位置yj.例如,如果第二个观察的真正类是第三类和K.= 4, 然后y2*= [0 0 1 0]'.类的顺序对应于
Classnames.输入模型的属性。F(Xj)为长度K.用于观察的班级分数向量j预测数据的X.分数的顺序与课程的顺序一致
Classnames.输入模型的属性。mj=yj*'F(Xj)。因此,mj是模型对真实的、观察到的类所预测的标量分类分数。
观察的重量j是W.j.该软件将观察权重标准化,使得它们总和到相应的先前类概率。该软件还规范化了现有概率,因此它们总和为1.因此,
在这种情况下,下表描述了支持的损失函数,您可以使用金宝app“LossFun”名称值对参数。
| 损失函数 | 的价值失意 |
方程式 |
|---|---|---|
| 二项式偏差 | 'binodeviance' |
|
| 十进制误分类率 | “classiferror” |
是与具有最大分数的类对应的类标签。一世{·}是指示器功能。 |
| 交叉熵损失 | “交叉熵” |
加权交叉熵损失是
的权重 被标准化为总和N而不是1。 |
| 指数损失 | “指数” |
|
| 铰链损耗 | “铰链” |
|
| Logit损失 | 'logit' |
|
| 最小预期误分类成本 | 'Mincost' |
软件使用此程序计算加权最小预期分类成本,用于观察j= 1,…,N.
最小预期误分类成本损失的加权平均值为
如果使用默认成本矩阵(其元素值为0对于正确分类和1个不正确的分类),则 |
| 二次损失 | “二次” |
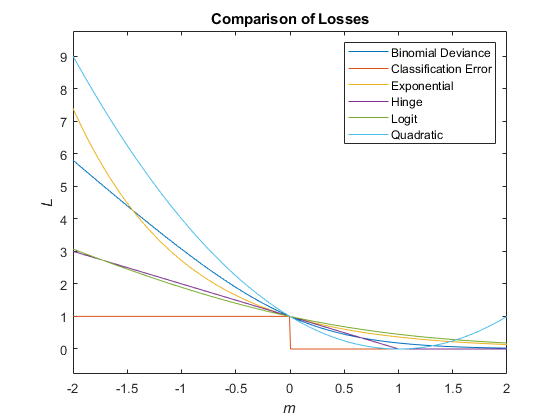
该图比较了损耗函数(除“交叉熵”和'Mincost'超过分数m对于一个观测值,一些函数被归一化以通过点(0,1)。
您还可以从以下列表中选择网站:
