损失
查找支持向量机(SVM)分类器的分类错误金宝app
描述
L=损失(svmmodel.,TBL.,responsevarname.)svmmodel.)对表中的预测器数据进行分类TBL.与真正的课程标签相比tbl.responsevarname..
损失标准化类概率tbl.responsevarname.到之前的概率fitcsvm.用于培训,储存在事先的性质svmmodel..
分类损失(L)是一种概括或重新替代的质量度量。其解释取决于损失函数和加权方案,但一般来说,更好的分类器产生更小的分类损失值。
例子
输入参数
更多关于
分类损失
分类损失功能测量分类模型的预测不准确性。当您在许多模型之间比较相同类型的损耗时,较低的损耗表示更好的预测模型。
考虑以下情景。
L是加权平均分类损失。
N是样本量。
对于二进制分类:
YJ是观察到的类标签。软件将其代码为-1或1,表示负类或正类(或第一个或第二类
类名财产分别。F(XJ)是观察的正级分类评分(行)J预测数据X.
MJ=YJF(XJ)是分类观察的分类分数J进入对应的类YJMJ表明正确的分类,并没有为平均损失贡献。负值MJ表示不正确的分类,并对平均损失显着贡献。
对于支持多字符分类的算法(即,金宝appK≥3):
YJ*是一个矢量K- 1零,1个位置与真实的,观察类相对应YJ.例如,如果第二个观察的真正类是第三个阶级和K= 4那么Y2.*= [0 0 1 0]′.类的顺序对应于订单
类名输入模型的属性。F(XJ)是长度K课程的传染媒介观察的J预测数据X.分数的顺序对应于类中的类的顺序
类名输入模型的属性。MJ=YJ*′F(XJ).所以,MJ标量分类得分是模型预测真实的观察类。
观察权重J是WJ.软件将观测权重标准化,使其总和为相应的先验类别概率。软件还将先验概率标准化,使其总和为1。因此,
鉴于此方案,下表介绍了通过使用您可以指定的支持损耗功能金宝app'lockfun'名称-值对参数。
| 损失功能 | 价值损失义务 |
方程 |
|---|---|---|
| 二项式偏差 | “偏差” |
|
| 小数点被错误分类 | 'classiferror' |
是与得分最大的类对应的类标签。我{·是指标功能。 |
| 交叉熵损失 | 'forrorentropy' |
加权交叉熵损失是
哪里重量 将标准化为总和N而不是1。 |
| 指数损失 | '指数' |
|
| 铰链损失 | '合页' |
|
| 罗吉特损失 | “罗吉特” |
|
| 最小预期错误分类费用 | “mincost” |
该软件使用此过程计算加权最小预期的分类成本进行观察J= 1,......,N.
最小预期错误分类成本损失的加权平均值是
如果使用默认成本矩阵(其要素值为0表示正确分类,1表示不正确分类),则 |
| 二次损失 | '二次' |
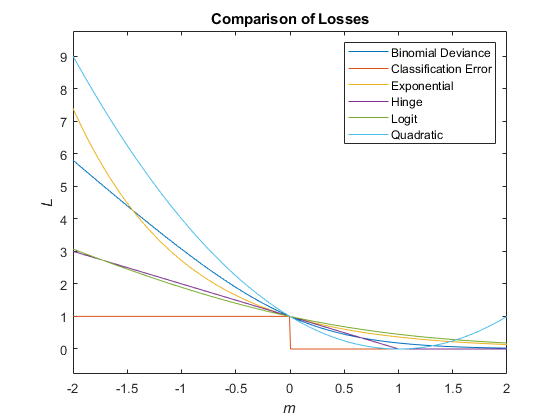
该图比较了损耗功能(除了'forrorentropy'和“mincost”)超过分数M一个观察。某些功能被归一化以通过点(0,1)。
参考
[1] Hastie,T.,R. Tibshirani和J. Friedman。统计学习的要素,第二版。斯普林格,纽约,2008年。
扩展能力
您还可以从以下列表中选择一个网站:
