再预测
类别:分类树
预测分类树的再替换标签
语法
标签=重新预测(树)
[标签,后]=重新预测(树)
[标签,后,节点]=重新预测(树)
[标签,后,节点,cnum]=重新预测(树)
[标签,…]=重新预测(树、名称、值)
描述
标签=重新预测(树)树对数据进行预测tree.X.标签这是我们的预测吗树根据以下数据:菲茨特里用于创建树.
[返回的节点号标签,后面的,节点]=重新预测(树)树对于重新替换的数据。
输入参数
输出参数
|
反应 如果 |
|
类的后验概率矩阵或数组 如果 如果 |
|
节点数 如果 如果 |
|
班级编号是 如果 如果 |
例子
计算错误分类观察的数量
查找分类树的Fisher iris数据的误分类总数。
负载鱼腥草tree=fitctree(MEA,物种);Ypredict=resubPredict(tree);%预测Ysame=strcmp(预测,种类);%当==sum(~Ysame)%有多少是不同的?
ans=3
比较每个子树的样本后验概率
加载Fisher的iris数据集。将数据划分为训练(50%)
负载鱼腥草
使用“所有花瓣测量”生长分类树。
Mdl=fitctree(MEA(:,3:4),物种);n=尺寸(平均值,1);%样本量K=numel(Mdl.ClassNames);%班级数
查看分类树。
视图(Mdl,“模式”,“图形”);
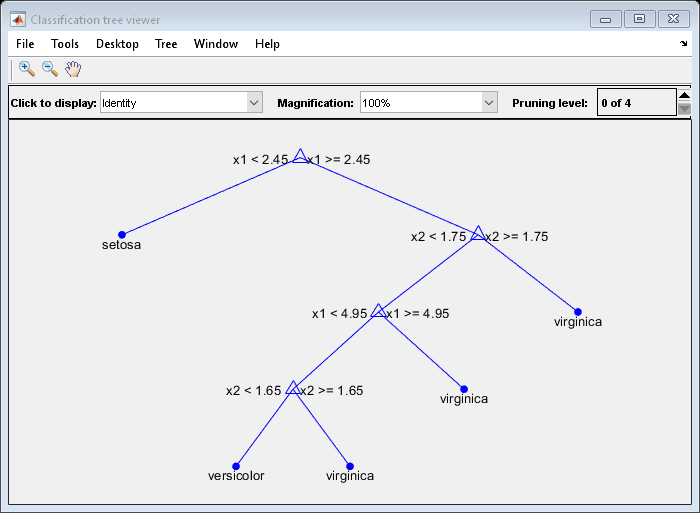
分类树有四个修剪级别。级别0是完整的未运行树(如图所示)。级别4只是根节点(即,没有拆分)。
使用修剪为1级和3级的子树估计每个类别的后验概率。
[~,后]=再预测(Mdl,“子树”,[1 3]);
后面的是一个N-借-K-后验概率的by-2数组后面的对应于观察,列对应于有序的类Mdl.ClassNames,页面对应于修剪级别。
使用每个子树显示iris 125的类后验概率。
后部(125,:,:)
ans=ans(:,:,1)=0.0217 0.9783 ans(:,:,2)=0.5000 0.5000
决策树桩(第2页,共页)后面的)无法预测iris 125是花色还是弗吉尼亚色。
更多关于
后验概率
节点处分类的后验概率是导致该节点具有该分类的训练序列的数量除以导致该节点的训练序列的数量。
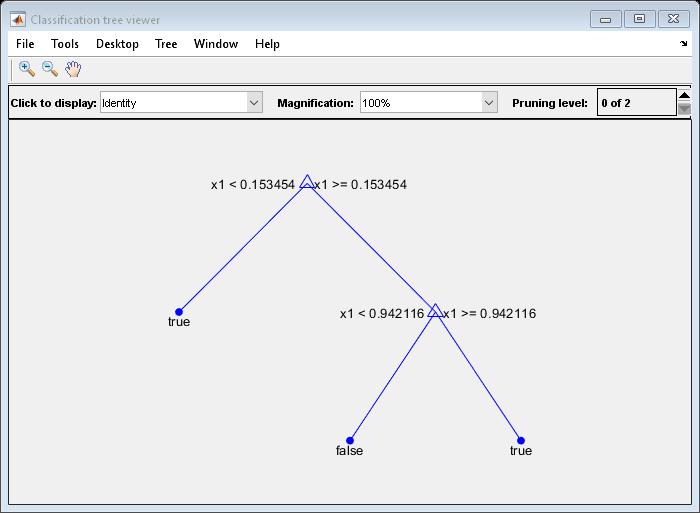
例如,考虑对预测器进行分类。X像符合事实的什么时候X<0.15或X>0.95和X否则就错了。
生成100个随机点并对其进行分类:
rng(0)%为了再现性X=兰特(100,1);Y=(绝对值X-.55)>0.4);tree=fitctree(X,Y);视图(树、,“模式”,“图形”)
修剪树木:
树1=修剪(树,“水平”,1);视图(树1,“模式”,“图形”)
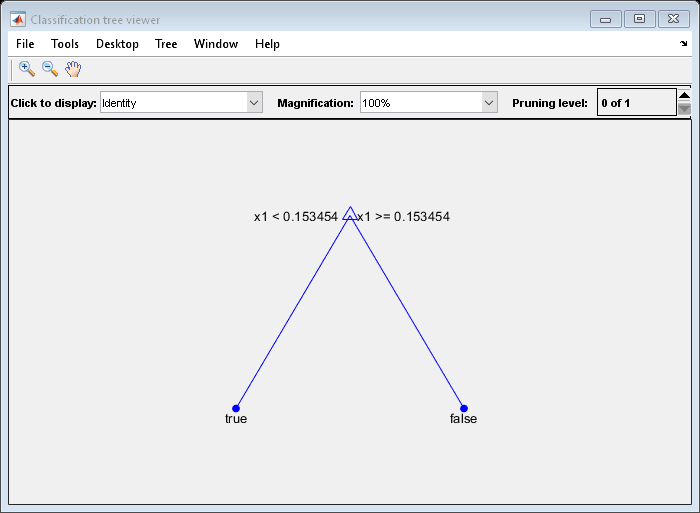
修剪后的树将小于0.15的观测值正确分类为
符合事实的.它还将.15和.94之间的观测值正确分类为错误的.但是,它错误地将大于.94的观测值分类为错误的因此,大于.15的观察值的得分应为.05/.85=.06符合事实的,大约为.8/.85=.94错误的.计算前10行的预测分数
X:[~,得分]=预测(树1,X(1:10));[分数X(1:10,:)]
ans=10×30.9059 0.0941 0.8147 0.9059 0.0941 0.9058 0 1.0000 0.1270 0.9059 0.0941 0.9134 0.9059 0.0941 0.6324 0 1.0000 0.0975 0.9059 0.0941 0.2785 0.9059 0.0941 0.5469 0.9059 0.0941 0.9575 0.9059 0.0941 0.9649事实上,所有的价值
X小于0.15的(最右边的列)的关联分数(左边和中间的列)为0和1.,而X有关联的分数0.94和0.06.


扩展能力
您还可以从以下列表中选择网站:
