分布的情节
分布的情节通过将数据的经验分布与特定分布的理论值进行比较,直观地评估样本数据的分布。使用分布图和更正式的假设检验来确定样本数据是否来自特定的分布。要了解假说检验,请看假设检验.
统计和机器学习工具箱™提供了多种分布块选项:
正态概率图
使用正态概率图来评估数据是否来自正态分布。许多统计过程都假设一个潜在的分布是正态分布。正态概率图可以为证明这一假设提供一些保证,或者为假设存在的问题提供警告。正态性分析通常结合正态概率图和正态性假设检验。
本例从均值为10、标准差为1的正态分布生成25个随机数的数据样本,并创建数据的正态概率图。
rng (“默认”);重复性的%x = normrnd(10 1[25日1]);normplot (x)
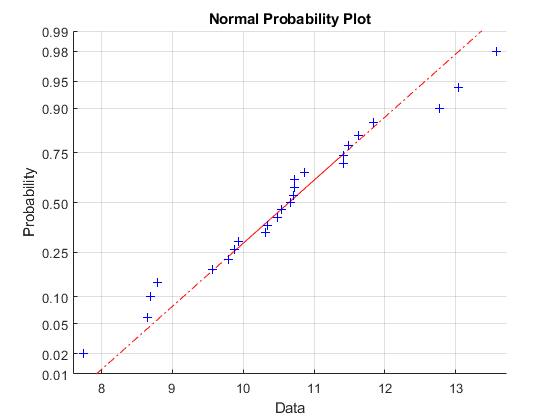
加号表示经验概率与数据中每个点的数据值的关系。实线连接数据中的第25和75个百分点,虚线将其延伸到数据的末尾。的y-AXIS值是从零到1的概率,但刻度不是线性的。刻度线之间的距离y-轴匹配正态分布的分位数之间的距离。分位数靠近中位数(第50个百分位数),并在远离中位数时对称地展开。
在正态概率图中,如果所有数据点都落在直线附近,则正态假设是合理的。否则,正常的假设是不合理的。例如,下面从平均为10的指数分布中生成100个随机数的数据样本,并创建数据的正态概率图。
X = EXPRND(10,100,1);normplot (x)
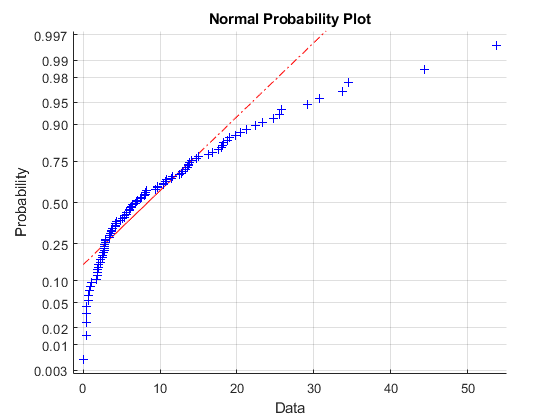
情节是强有力的证据表明潜在的分布不正常。
概率情节
概率图,就像正态概率图一样,只是按特定分布缩放的经验cdf图。的y-AXIS值是从零到1的概率,但刻度不是线性的。刻度线之间的距离是分布量之间的距离。在图中,在数据中的第一和第三个四分位数之间绘制一条线。如果数据靠近该行,则可以合理地选择分发作为数据的模型。分配分析通常将概率图与特定分布的假设检验结合起来。
创建威布尔概率图
生成样本数据并创建概率图。
生成样本数据。样例x1包含具有缩放参数的Weibull分布的500个随机数A = 3.和形状参数B = 3..样例x2包含500个带有尺度参数的瑞利分布的随机数B = 3..
rng (“默认”);重复性的%x1 = wblrnd(3 3[1] 500年);x2 = raylrnd(3[1] 500年);
创建一个概率图来评估数据是否x1和x2来自威布尔分布。
图probplot('weibull', (x1, x2)))传说(“威布尔样本”,'瑞利样品',“位置”,“最佳”)
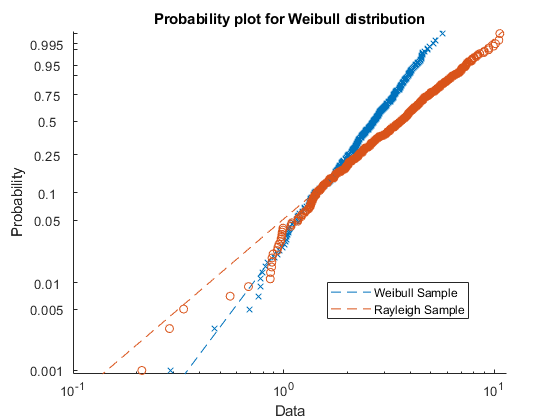
概率图显示数据x1来自威布尔分布,而数据中的数据x2才不是。
或者,您可以使用WBLPLOT.创建威布尔概率绘图。
Quantile-Quantile情节
使用定量位定量(Q-Q)图来确定两个样本是否来自同一分销系列。Q-Q图是从每个样品计算的量级的散点图,在第一和第三个四分位数之间绘制的线。如果数据落在该线附近,则假设两个样本来自相同的分布是合理的。该方法对于任一分布的位置和比例的变化是鲁棒的。
方法创建分位数图qqplot函数。
以下示例生成包含具有不同参数值的泊松分布的随机数的两个数据样本,并创建定量位定量绘图。数据in.x是来自均值为10的泊松分布,而y是来自均值为5的泊松分布。
X = Poissrnd(10,[50,1]);Y = Poissrnd(5,[100,1]);qqplot(x,y)
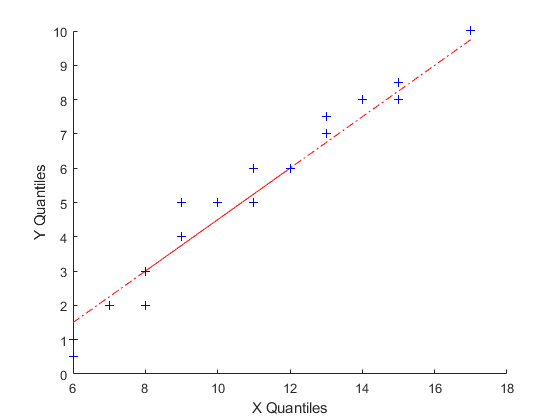
即使参数和样本尺寸是不同的,近似线性关系也表明两个样本可能来自相同的分布族。与正常概率图一样,假设试验可以为这种假设提供额外的理由。然而,对于依赖于来自相同分布的两个样本的统计程序,线性定位量绘制通常足够。
下面的示例展示了底层发行版不相同时会发生什么。在这里,x包含从具有平均5和标准偏差1的正态分布生成的100个随机数,同时y包含100个由威布尔分布生成的随机数,其比例参数为2,形状参数为0.5。
x = normrnd(5,1,[100,1]);Y = WBLRND(2,0.5,[100,1]);qqplot(x,y)
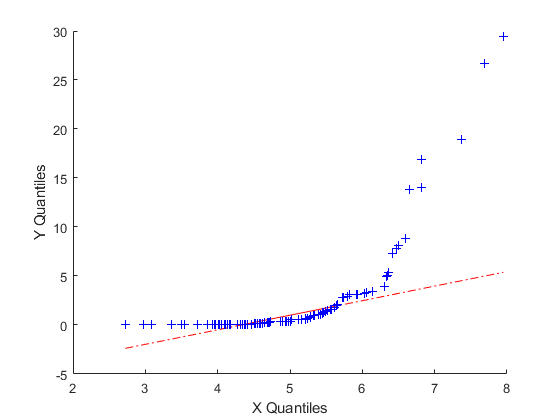
该图表明这些样品显然不是来自同一分配家庭的。
累积分布图
一个经验累积分布函数(cdf)图显示了小于或等于每一个的数据所占的比例x价值,作为的函数x.磅秤y设在是线性的;特别的是,它没有被缩放到任何特定的分布。经验cdf图用于比较数据cdfs和特定分布的cdfs。
要创建一个经验的cdf图,使用cdfplot功能或者ecdf.函数。
比较实证CDF到理论CDF
绘制一个样本数据集的经验cdf,并将其与样本数据集的基本分布的理论cdf进行比较。在实践中,理论上的cdf是未知的。
从位置参数为0,尺度参数为3的极值分布生成随机样本数据集。
rng (“默认”)重复性的%Y = EVRND(0,3,100,1);
绘制样本数据集的经验CDF和同一图中的理论CDF。
cdfplot (y)在x = linspace(min(y),max(y));plot(x,evcdf(x,0,3))图例(“经验提供”,'理论CDF',“位置”,“最佳”) 抓住离开
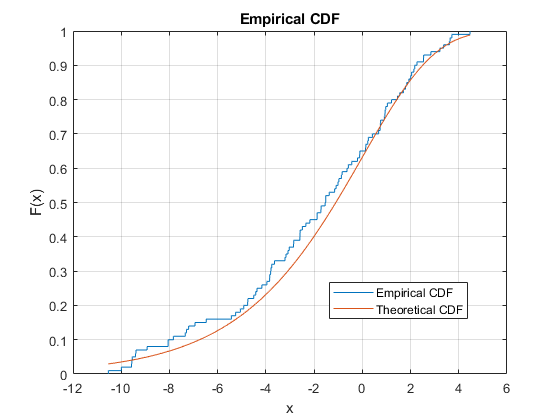
该图显示了经验CDF与理论CDF之间的相似性。
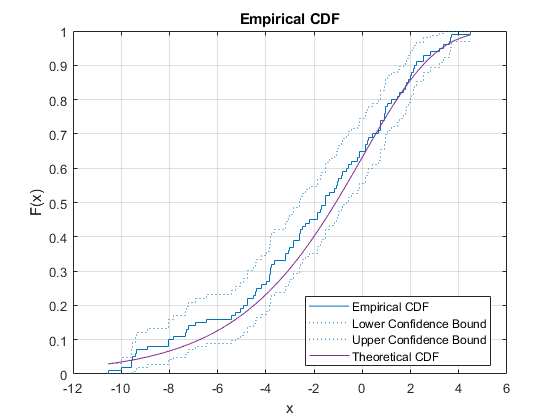
或者,您可以使用ecdf.函数。的ecdf.函数还绘制了用Greenwood公式估计的95%置信区间。有关详细信息,请参见格林伍德的公式.
ecdf (y,'界限',“上”) 抓住在绘图(x,evcdf(x,0,3))网格在标题(“经验提供”)传说(“经验提供”,“低信心绑定”,“上信心绑定”,'理论CDF',“位置”,“最佳”) 抓住离开
另请参阅
cdfplot|ecdf.|normplot.|probplot.|qqplot|WBLPLOT.
相关的话题
您还可以从以下列表中选择一个网站:
