合奏正规化gydF4y2Ba
正则化是在不降低预测性能的情况下为集成选择更少弱学习器的过程。目前,您可以正则化回归集合。(您还可以在非集成上下文中正则化判别分析分类器;看到gydF4y2Ba正则化判别分析分类器gydF4y2Ba.)gydF4y2Ba
的gydF4y2Ba规范gydF4y2Ba方法寻找一组最优的学习器权重gydF4y2BaαgydF4y2BatgydF4y2Ba,减少gydF4y2Ba
在这里gydF4y2Ba
λgydF4y2Ba≥0gydF4y2Ba是您提供的参数,称为套索参数。gydF4y2Ba
hgydF4y2BatgydF4y2Ba整体中弱学习者是否受到训练gydF4y2BaNgydF4y2Ba带有预测因子的观察gydF4y2BaxgydF4y2BangydF4y2Ba、响应gydF4y2BaygydF4y2BangydF4y2Ba,和权重gydF4y2BawgydF4y2BangydF4y2Ba.gydF4y2Ba
ggydF4y2Ba(gydF4y2BafgydF4y2Ba,gydF4y2BaygydF4y2Ba) = (gydF4y2BafgydF4y2Ba- - - - - -gydF4y2BaygydF4y2Ba)gydF4y2Ba2gydF4y2Ba是误差的平方。gydF4y2Ba
集合在相同的(gydF4y2BaxgydF4y2BangydF4y2Ba,gydF4y2BaygydF4y2BangydF4y2Ba,gydF4y2BawgydF4y2BangydF4y2Ba)数据用于训练,因此gydF4y2Ba
是集合替换误差。误差用均方误差(MSE)来测量。gydF4y2Ba
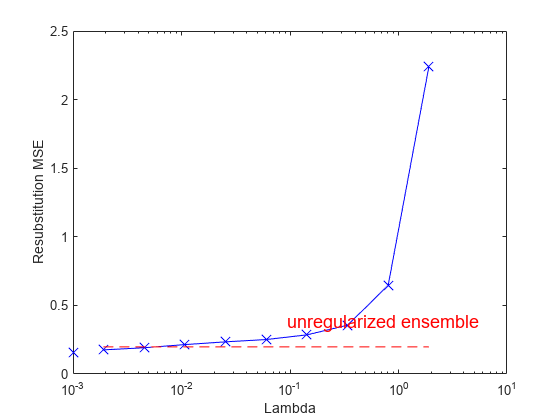
如果你使用gydF4y2BaλgydF4y2Ba= 0gydF4y2Ba,gydF4y2Ba规范gydF4y2Ba通过最小化再替换MSE,找到弱学习器权值。合奏团往往训练过度。换句话说,再替换误差通常小于真正的泛化误差。通过使再替换误差更小,您可能会使集成精度更差,而不是提高它。另一方面,正的值gydF4y2BaλgydF4y2Ba推的大小gydF4y2BaαgydF4y2BatgydF4y2Ba系数为0。这通常会改善泛化误差。当然,如果你愿意的话gydF4y2BaλgydF4y2Ba太大,所有的最优系数都是0,集合没有任何精度。通常你可以找到一个最佳的范围gydF4y2BaλgydF4y2Ba其中正则化集合的精度优于或与未正则化的完整集合相当。gydF4y2Ba
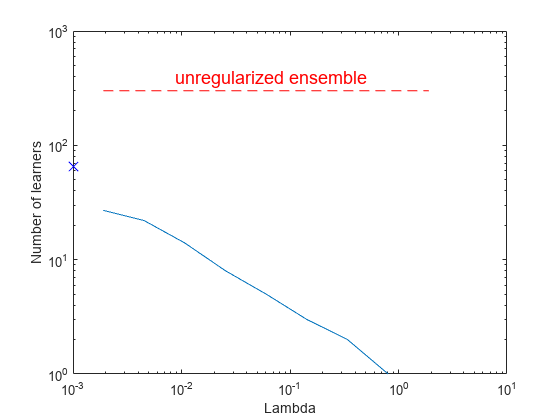
套索正则化的一个很好的特点是它能够将优化系数精确地驱动到0。如果一个学习者的体重gydF4y2BaαgydF4y2BatgydF4y2Ba为0时,该学习器可以从正则集合中排除。最后,你得到了一个精度更高、学习者更少的集合。gydF4y2Ba
正则化回归集合gydF4y2Ba
本例使用数据根据汽车的许多属性来预测汽车的保险风险。gydF4y2Ba
加载gydF4y2Ba进口- 85gydF4y2Ba数据导入MATLAB工作空间。gydF4y2Ba
负载gydF4y2Ba进口- 85gydF4y2Ba;gydF4y2Ba
查看数据的描述以找到分类变量和预测器名称。gydF4y2Ba
描述gydF4y2Ba
描述=gydF4y2Ba9x79字符数组gydF4y2Ba“1985 Auto Imports Database from UCI repository”“http://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.names”变量已经重新排序,将数值变量(在UCI站点上称为“连续”)放在左边,将分类值放在右边。具体来说,变量1:16是:符号,归一化损失,' '轴距,长度,宽度,高度,约束重量,发动机尺寸,内径,冲程,' '压缩比,马力,峰值转速,城市mpg,公路mpg,和价格。变量17:26是:制造,燃料类型,吸气,门数,车身样式,驱动轮,发动机位置,发动机类型,气缸数,燃料系统gydF4y2Ba
这个过程的目标是从其他预测因子中预测“符号”,即数据中的第一个变量。“symboling”是一个整数gydF4y2Ba3gydF4y2Ba(好的保险风险)到gydF4y2Ba3.gydF4y2Ba(不良保险风险)。您可以使用分类集合来预测这种风险,而不是使用回归集合。当您要在回归和分类之间做出选择时,您应该先尝试回归。gydF4y2Ba
为集成拟合准备数据。gydF4y2Ba
Y = x (:,1);X(:,1) = [];VarNames = {gydF4y2Ba“normalized-losses”gydF4y2Ba的轴距gydF4y2Ba“长度”gydF4y2Ba“宽度”gydF4y2Ba“高度”gydF4y2Ba...gydF4y2Ba整备质量的gydF4y2Ba发动机的大小的gydF4y2Ba“生”gydF4y2Ba“中风”gydF4y2Ba的压缩比gydF4y2Ba...gydF4y2Ba“马力”gydF4y2Ba“peak-rpm”gydF4y2Ba“city-mpg”gydF4y2Ba“highway-mpg”gydF4y2Ba“价格”gydF4y2Ba“使”gydF4y2Ba...gydF4y2Ba“可燃物类型”gydF4y2Ba“愿望”gydF4y2Ba“num-of-doors”gydF4y2Ba“身体作风”gydF4y2Ba驱动轮的gydF4y2Ba...gydF4y2Ba“引擎位置”gydF4y2Ba发动机型号的gydF4y2Ba“num-of-cylinders”gydF4y2Ba“燃油系统”gydF4y2Ba};Catidx = 16:25;gydF4y2Ba%指标的分类预测gydF4y2Ba
使用300棵树从数据创建一个回归集成。gydF4y2Ba
ls = fitrensemble(X,Y,gydF4y2Ba“方法”gydF4y2Ba,gydF4y2Ba“LSBoost”gydF4y2Ba,gydF4y2Ba“NumLearningCycles”gydF4y2Ba, 300,gydF4y2Ba...gydF4y2Ba“LearnRate”gydF4y2Ba, 0.1,gydF4y2Ba“PredictorNames”gydF4y2BaVarNames,gydF4y2Ba...gydF4y2Ba“ResponseName”gydF4y2Ba,gydF4y2Ba“象征”gydF4y2Ba,gydF4y2Ba“CategoricalPredictors”gydF4y2Bacatidx)gydF4y2Ba
ls = RegressionEnsemble PredictorNames: {1x25 cell} ResponseName: 'Symboling' CategoricalPredictors: [16 17 18 19 20 21 22 23 24 25] ResponseTransform: 'none' NumObservations: 205 NumTrained: 300 Method: 'LSBoost' LearnerNames: {'Tree'} reasonforterminate: '完成所要求的训练周期数后正常终止。'FitInfo: [300x1 double] FitInfoDescription: {2x1 cell}正则化:[]属性,方法gydF4y2Ba
最后一句,gydF4y2Ba正则化gydF4y2Ba,为空([])。要正则化集合,必须使用gydF4y2Ba规范gydF4y2Ba方法。gydF4y2Ba
CV = crossval(ls,gydF4y2Ba“KFold”gydF4y2Ba5);图;情节(kfoldLoss(简历,gydF4y2Ba“模式”gydF4y2Ba,gydF4y2Ba“累积”gydF4y2Ba));包含(gydF4y2Ba“树的数量”gydF4y2Ba);ylabel (gydF4y2Ba“旨在MSE”gydF4y2Ba);ylim (0.2 [2])gydF4y2Ba
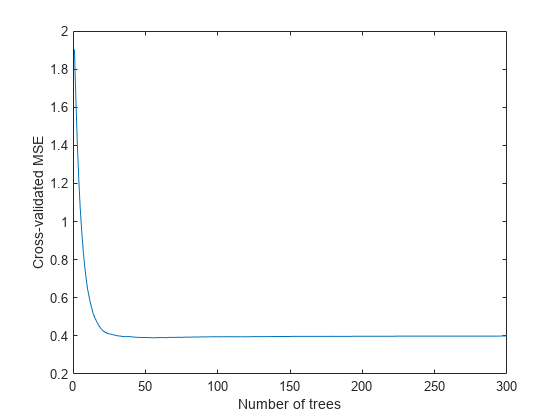
看起来你可以从一个较小的组合中获得满意的表现,也许一个包含50到100棵树的组合。gydF4y2Ba
调用gydF4y2Ba规范gydF4y2Ba方法尝试查找可以从集成中删除的树。默认情况下,gydF4y2Ba规范gydF4y2Ba检查套索的10个值(gydF4y2BaλgydF4y2Ba)参数以指数方式间隔。gydF4y2Ba
Ls =正则化(Ls)gydF4y2Ba
ls = RegressionEnsemble PredictorNames: {1x25 cell} ResponseName: 'Symboling' CategoricalPredictors: [16 17 18 19 20 21 22 23 24 25] ResponseTransform: 'none' NumObservations: 205 NumTrained: 300 Method: 'LSBoost' LearnerNames: {'Tree'} reasonforterminate: '完成所要求的训练周期数后正常终止。'FitInfo: [300x1 double] FitInfoDescription: {2x1 cell}正则化:[1x1 struct]属性,方法gydF4y2Ba
的gydF4y2Ba正则化gydF4y2Ba属性不再为空。gydF4y2Ba
根据套索参数绘制重置换均方误差(MSE)和非零权重的学习器数量。分别绘制点的值gydF4y2Ba= 0gydF4y2Ba.使用对数刻度,因为的值gydF4y2BaλgydF4y2Ba是指数间隔的。gydF4y2Ba
图;semilogx (ls.Regularization.Lambda ls.Regularization.ResubstitutionMSE,gydF4y2Ba...gydF4y2Ba“bx - - - - - -”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10);线([1 e - 3 1 e - 3]、[ls.Regularization.ResubstitutionMSE (1)gydF4y2Ba...gydF4y2Bals.Regularization.ResubstitutionMSE (1)),gydF4y2Ba...gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“x”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba);r0 = resubLoss(ls);线([ls.Regularization.Lambda (2) ls.Regularization.Lambda(结束),gydF4y2Ba...gydF4y2Ba(r0 r0),gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“——”gydF4y2Ba);包含(gydF4y2Ba“λ”gydF4y2Ba);ylabel (gydF4y2Ba“Resubstitution MSE”gydF4y2Ba);注释(gydF4y2Ba“文本框”gydF4y2Ba,[0.5 0.22 0.5 0.05],gydF4y2Ba“字符串”gydF4y2Ba,gydF4y2Ba“unregularized乐团”gydF4y2Ba,gydF4y2Ba...gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“字形大小”gydF4y2Ba14岁的gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“没有”gydF4y2Ba);gydF4y2Ba
图;重对数(ls.Regularization.Lambda总和(ls.Regularization.TrainedWeights > 0, 1));线((1 e - 3 1 e - 3),gydF4y2Ba...gydF4y2Ba[总和(ls.Regularization.TrainedWeights (: 1) > 0)gydF4y2Ba...gydF4y2Basum (ls.Regularization.TrainedWeights (: 1) > 0)),gydF4y2Ba...gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“x”gydF4y2Ba,gydF4y2Ba“markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba);线([ls.Regularization.Lambda (2) ls.Regularization.Lambda(结束),gydF4y2Ba...gydF4y2Ba(ls。NTrained ls.NTrained],...gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“——”gydF4y2Ba);包含(gydF4y2Ba“λ”gydF4y2Ba);ylabel (gydF4y2Ba“学习人数”gydF4y2Ba);注释(gydF4y2Ba“文本框”gydF4y2Ba,[0.3 0.8 0.5 0.05],gydF4y2Ba“字符串”gydF4y2Ba,gydF4y2Ba“unregularized乐团”gydF4y2Ba,gydF4y2Ba...gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“字形大小”gydF4y2Ba14岁的gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“没有”gydF4y2Ba);gydF4y2Ba
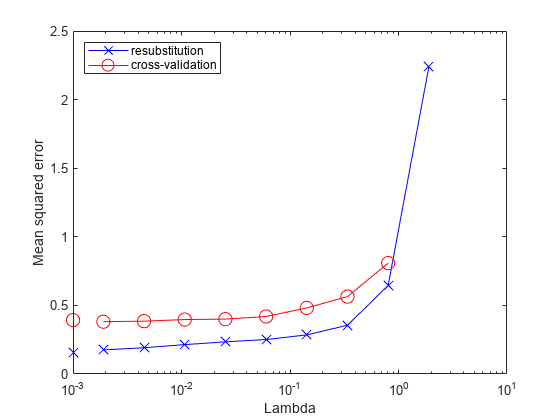
再置换MSE值可能过于乐观。以获得更可靠的误差估计值与各种值的关联gydF4y2BaλgydF4y2Ba,交叉验证集成使用gydF4y2BacvshrinkgydF4y2Ba.绘制由此产生的交叉验证损失(MSE)和相对的学习者数量gydF4y2BaλgydF4y2Ba.gydF4y2Ba
rng (0,gydF4y2Ba“旋风”gydF4y2Ba)gydF4y2Ba再现率%gydF4y2Ba[mse,nlearn] = cvshrink(ls,gydF4y2Ba“λ”gydF4y2Bals.Regularization.Lambda,gydF4y2Ba“KFold”gydF4y2Ba5);gydF4y2Ba
警告:一些折叠没有任何训练过的弱学习器。gydF4y2Ba
图;semilogx (ls.Regularization.Lambda ls.Regularization.ResubstitutionMSE,gydF4y2Ba...gydF4y2Ba“bx - - - - - -”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10);持有gydF4y2Ba在gydF4y2Ba;semilogx (ls.Regularization.Lambda、mse、gydF4y2Ba“ro - - - - - -”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10);持有gydF4y2Ba从gydF4y2Ba;包含(gydF4y2Ba“λ”gydF4y2Ba);ylabel (gydF4y2Ba“均方误差”gydF4y2Ba);传奇(gydF4y2Ba“resubstitution”gydF4y2Ba,gydF4y2Ba交叉验证的gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba);线([1 e - 3 1 e - 3]、[ls.Regularization.ResubstitutionMSE (1)gydF4y2Ba...gydF4y2Bals.Regularization.ResubstitutionMSE (1)),gydF4y2Ba...gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“x”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba,gydF4y2Ba“HandleVisibility”gydF4y2Ba,gydF4y2Ba“关闭”gydF4y2Ba);Line ([1e-3 1e-3],[mse(1) mse(1)],gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“o”gydF4y2Ba,gydF4y2Ba...gydF4y2Ba“Markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“——”gydF4y2Ba,gydF4y2Ba“HandleVisibility”gydF4y2Ba,gydF4y2Ba“关闭”gydF4y2Ba);gydF4y2Ba
图;重对数(ls.Regularization.Lambda总和(ls.Regularization.TrainedWeights > 0, 1));持有;gydF4y2Ba
目前的地块gydF4y2Ba
重对数(ls.Regularization.Lambda nlearn,gydF4y2Ba“r——”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba;包含(gydF4y2Ba“λ”gydF4y2Ba);ylabel (gydF4y2Ba“学习人数”gydF4y2Ba);传奇(gydF4y2Ba“resubstitution”gydF4y2Ba,gydF4y2Ba交叉验证的gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“不”gydF4y2Ba);线((1 e - 3 1 e - 3),gydF4y2Ba...gydF4y2Ba[总和(ls.Regularization.TrainedWeights (: 1) > 0)gydF4y2Ba...gydF4y2Basum (ls.Regularization.TrainedWeights (: 1) > 0)),gydF4y2Ba...gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“x”gydF4y2Ba,gydF4y2Ba“Markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba,gydF4y2Ba“HandleVisibility”gydF4y2Ba,gydF4y2Ba“关闭”gydF4y2Ba);Line ([1e-3 1e-3],[nlearn(1) nlearn(1)],gydF4y2Ba“标记”gydF4y2Ba,gydF4y2Ba“o”gydF4y2Ba,gydF4y2Ba...gydF4y2Ba“Markersize”gydF4y2Ba10gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“r”gydF4y2Ba,gydF4y2Ba“线型”gydF4y2Ba,gydF4y2Ba“——”gydF4y2Ba,gydF4y2Ba“HandleVisibility”gydF4y2Ba,gydF4y2Ba“关闭”gydF4y2Ba);gydF4y2Ba
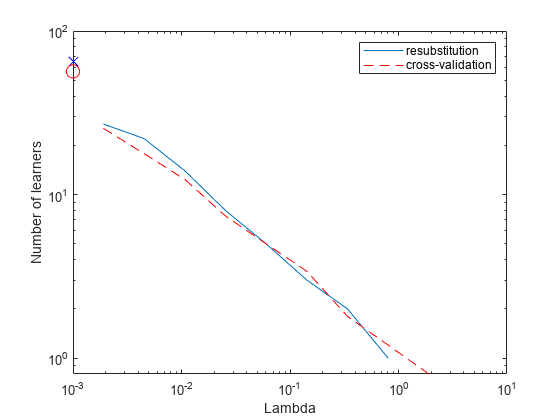
检查交叉验证的误差表明,交叉验证的MSE几乎是平坦的gydF4y2BaλgydF4y2Ba超过了一点gydF4y2Ba1)依照gydF4y2Ba.gydF4y2Ba
检查gydF4y2Bals.Regularization.LambdagydF4y2Ba找到在平坦区域(最多超过gydF4y2Ba1)依照gydF4y2Ba).gydF4y2Ba
jj = 1:长度(ls. regulalizing . lambda);[jj; ls.Regularization.Lambda]gydF4y2Ba
ans =gydF4y2Ba2×10gydF4y2Ba1.0000 2.0000 3.0000 4.0000 5.0000 6.0000 7.0000 8.0000 9.0000 10.0000 0 0.0019 0.0045 0.0107 0.0254 0.0602 0.1428 0.3387 0.8033 1.9048gydF4y2Ba
元素gydF4y2Ba5gydF4y2Ba的gydF4y2Bals.Regularization.LambdagydF4y2Ba是有价值的gydF4y2Ba0.0254gydF4y2Ba,是平坦范围内最大的。gydF4y2Ba
控件减少集成大小gydF4y2Ba缩小gydF4y2Ba方法。gydF4y2Ba缩小gydF4y2Ba返回不包含训练数据的紧凑集合。通过交叉验证,估计了新的紧凑集成的泛化误差gydF4y2Bamse (5)gydF4y2Ba.gydF4y2Ba
CMP =收缩(ls,gydF4y2Ba“weightcolumn”gydF4y2Ba5)gydF4y2Ba
cmp = CompactRegressionEnsemble PredictorNames: {1x25 cell} ResponseName: 'Symboling' CategoricalPredictors: [16 17 18 19 20 21 22 23 24 25] ResponseTransform: 'none' NumTrained: 8 Properties, MethodsgydF4y2Ba
新建筑群中的树木数量明显减少,从300英寸gydF4y2BalsgydF4y2Ba.gydF4y2Ba
比较合奏团的规模。gydF4y2Ba
Sz (1) = whos(gydF4y2Bacmp的gydF4y2Ba);Sz (2) = whos(gydF4y2Ba“ls”gydF4y2Ba);(深圳(1)。字节深圳(2).bytes]gydF4y2Ba
ans =gydF4y2Ba1×2gydF4y2Ba91209 3227100gydF4y2Ba
减小后的集合的大小是原来集合的一小部分。注意,集成的大小可能因操作系统而异。gydF4y2Ba
将简化集合的MSE与原始集合的MSE进行比较。gydF4y2Ba
图;情节(kfoldLoss(简历,gydF4y2Ba“模式”gydF4y2Ba,gydF4y2Ba“累积”gydF4y2Ba));持有gydF4y2Ba在gydF4y2Ba情节(cmp.NTrained mse (5),gydF4y2Ba“罗”gydF4y2Ba,gydF4y2Ba“MarkerSize”gydF4y2Ba10);包含(gydF4y2Ba“树的数量”gydF4y2Ba);ylabel (gydF4y2Ba“旨在MSE”gydF4y2Ba);传奇(gydF4y2Ba“unregularized乐团”gydF4y2Ba,gydF4y2Ba“正规化合奏”gydF4y2Ba,gydF4y2Ba...gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“不”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba
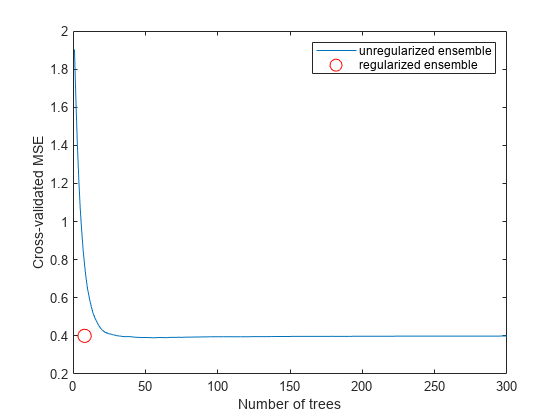
减少的集合在使用更少的树的情况下,降低了损失。gydF4y2Ba
另请参阅gydF4y2Ba
fitrensemblegydF4y2Ba|gydF4y2Ba规范gydF4y2Ba|gydF4y2BakfoldLossgydF4y2Ba|gydF4y2BacvshrinkgydF4y2Ba|gydF4y2Ba缩小gydF4y2Ba|gydF4y2BaresubLossgydF4y2Ba|gydF4y2BacrossvalgydF4y2Ba
相关的话题gydF4y2Ba
选择网站gydF4y2Ba
选择一个网站,在可用的地方获得翻译的内容,并查看当地的活动和优惠。根据您所在的位置,我们建议您选择:gydF4y2Ba.gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba您也可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
