主要内容
数据探索性分析
此示例显示如何使用描述性统计来探索数据的分发。
生成示例数据。
生成包含随机生成的样本数据的向量。
RNG.默认重复性的%x = [rangrnd(4,1,100),NORMRND(6,0.5,1,200)];
绘制直方图。
绘制具有正常密度合适的样本数据的直方图。这提供了样本数据的可视化比较和适合数据的正态分布。
histfit(x)
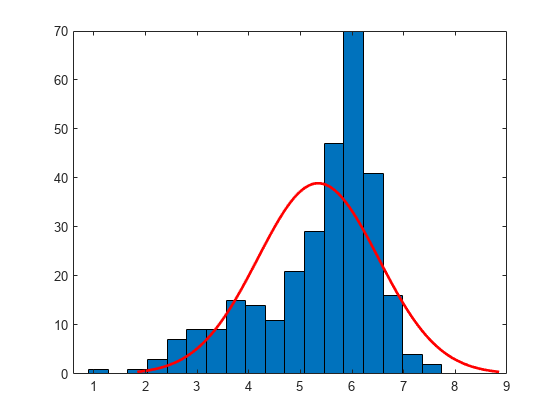
数据的分布似乎保持偏好。正常分布看起来不太适合此示例数据。
获得正常的概率图。
获得正常的概率图。此绘图提供了另一种方式来直观地将样本数据与适配给数据的正常分布。
probplot('普通的',X)
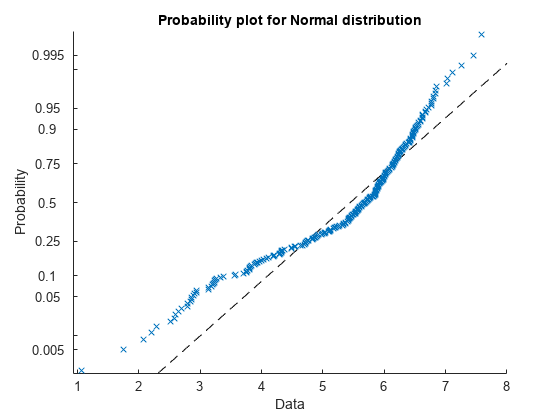
概率曲线还显示数据与正常性的偏差。
计算定量。
计算样本数据的分量。
p = 0:0.25:1;y = smianile(x,p);z = [p; y]
z =2×50 0.2500 0.5000 0.7500 1.0000 1.0557 4.7375 5.6872 6.1526 7.5784
创建一个盒子图以可视化统计信息。
boxplot(x)
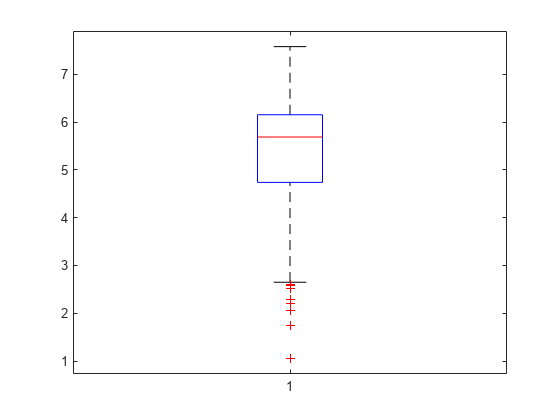
盒子图显示了0.25,0.5和0.75定位。长下尾和加号显示样本数据值中缺乏对称性。
计算描述性统计数据。
计算数据的均值和中位数。
Y = [均值(x),中位数(x)]
y =1×25.3438 5.6872
平均值和中值值似乎彼此接近,但比中位数小的平均值通常表示数据偏差。
计算数据的偏光和峰度。
y = [偏光(x),kurtosis(x)]
y =1×2-1.0417 3.5895
负偏斜值表示数据偏差。由于峰值值大于3,数据具有比正常分布更大的峰值。
计算z分数。
通过计算Z分数并找到大于3或小于-3的值来识别可能的异常值。
z = zscore(x);查找(ABS(Z)> 3);
基于Z分数,第3和第35次观察可能是异常值。
也可以看看
箱形图|histfit|久星病|意思是|中位数|分子|斯蒂利韦|歪斜
相关话题
您还可以从以下列表中选择一个网站:
