主要内容
histfit
直方图具有分配合适
描述
例子
直方图具有正常分配的拟合
从具有平均10和方差1的正态分布产生大小100的样本。
RNG.默认;重复性的%r = normrnd(10,1,100,1);
构造具有正常分配合适的直方图。
histfit(r)
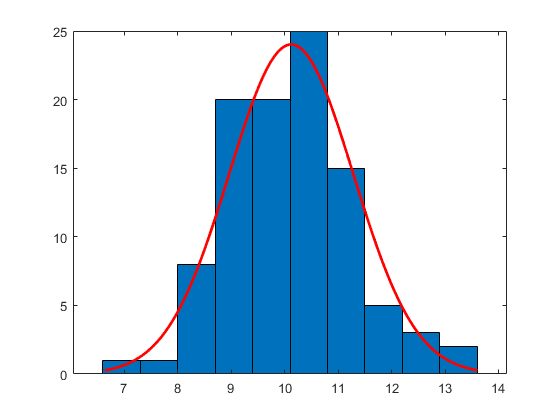
histfit用途Fitdist.适合数据分发。用Fitdist.获得适合使用的参数。
pd = fitdist(r,'普通的')
PD =正规分布正常分布MU = 10.1231 [9.89244,10.3537] Sigma = 1.1624 [1.02059,1.35033]
参数估计旁边的间隔是分布参数的95%置信区间。
给定数量的垃圾箱直方图
从具有平均10和方差1的正态分布产生大小100的样本。
RNG.默认;重复性的%r = normrnd(10,1,100,1);
使用具有正常分配合适的六个箱构造直方图。
histfit(r,6)
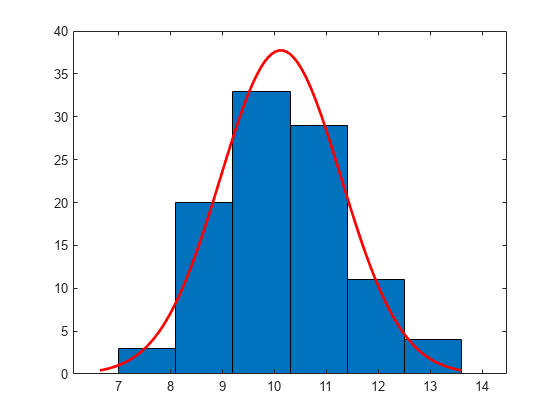
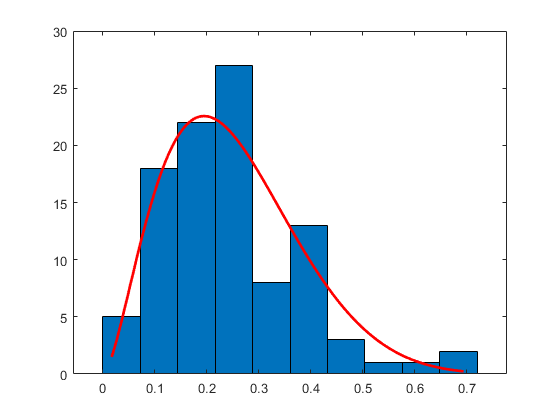
直方图具有指定的分配适合
从具有参数(3,10)的β分布产生大小100的样本。
RNG.默认;重复性的%b = betarnd(3,10,100,1);
使用具有β配合物的10个箱构造直方图。
histfit(b,10,'beta')
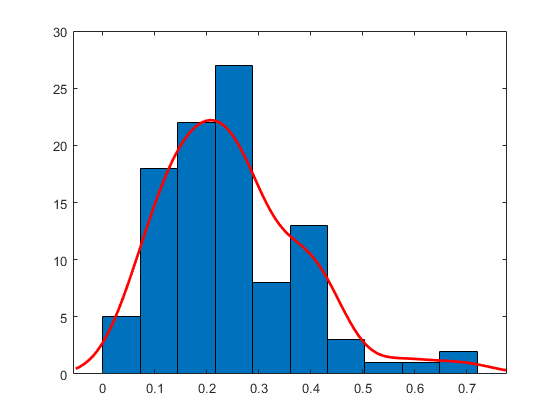
直方图具有内核平滑功能适合
从具有参数(3,10)的β分布产生大小100的样本。
RNG.默认;重复性的%b = betarnd(3,10,[100,1]);
使用具有平滑功能适合的10个箱构造直方图。
histfit(b,10,'核心')
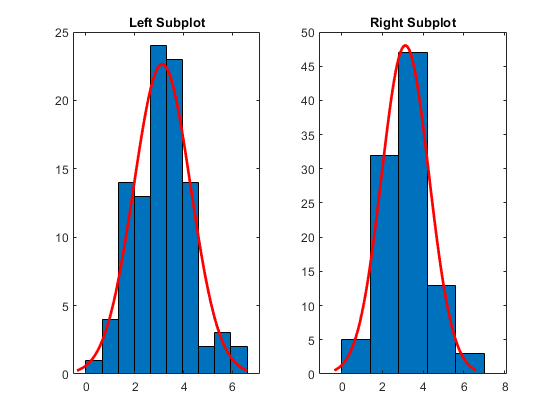
指定具有分配合适的直方图的轴
生成一个大小样本100.从正常分布与平均值3.和方差1。
RNG('默认')重复性的%r = normrnd(3,1,100,1);
创建一个具有两个子图的数字并返回轴物体AX1和AX2。通过参考相应的相应,在每组轴中创建具有正常分布的直方图轴目的。在左侧子图中,绘制具有10个箱的直方图。在右侧子图中,绘制5个箱的直方图。通过传递相应的每个绘图向每个绘图添加标题轴对象到标题功能。
AX1 =子图(1,2,1);%左侧子图histfit(AX1,R,10,'普通的')标题(AX1,'左子刻')AX2 =子图(1,2,2);%正确的子图histfit(ax2,r,5,'普通的')标题(AX2,'正确的子图')
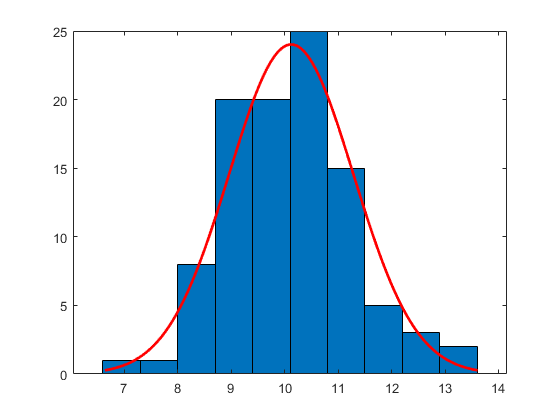
处理具有分配合适的直方图
从具有平均10和方差1的正态分布产生大小100的样本。
RNG.默认重复性的%r = normrnd(10,1,100,1);
构造具有正常分配合适的直方图。
h = histfit(r,10,'普通的')
H = 2x1图形阵列:栏线
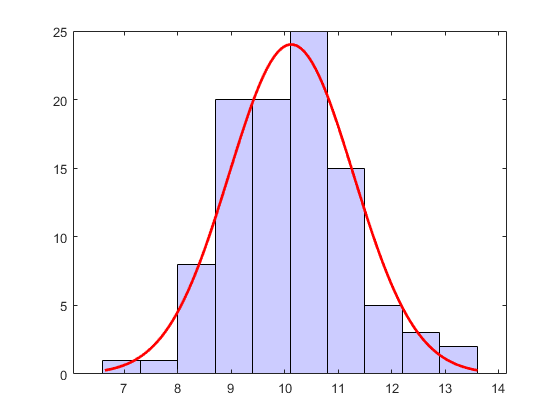
更改直方图的栏颜色。
h(1).facecolor = [.8 .8 1];
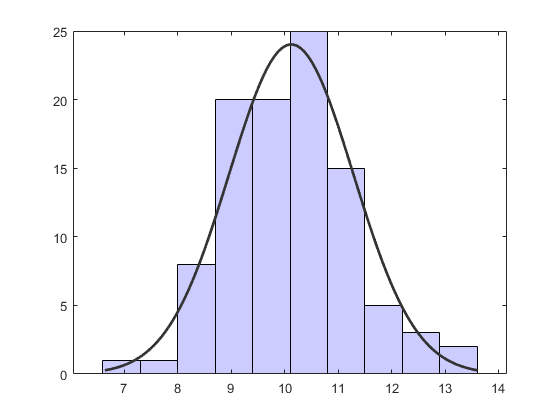
改变密度曲线的颜色。
h(2).color = [.2 .2 .2];
输入参数
输出参数
算法
histfit用途Fitdist.适合数据分发。用Fitdist.获得适合使用的参数。
在R2006A之前介绍
您还可以从以下列表中选择一个网站:
