主要内容
FeatureSelectionNCAClassification类
基于邻域成分分析(NCA)的分类特征选择
描述
FeatureSelectionNCAClassification对象包含邻域分量分析(NCA)模型的数据,拟合信息,特征权重和其他参数。fscnca使用对角自适应的NCA学习特征权值,并返回一个实例FeatureSelectionNCAClassification对象。该函数通过正则化特征权值来实现特征选择。
建设
创建一个FeatureSelectionNCAClassification对象使用fscnca。
属性
例子
探索FeatureSelectionNCAClassification目的
加载样本数据。
负载电离层
数据集具有34个连续预测器。响应变量是雷达返回,标记为B(坏)或g(好)。
适合邻域分量分析(NCA)模型,用于分类以检测相关功能。
mdl = fscnca (X, Y);
返回的NCA模型,MDL.,是A.FeatureSelectionNCAClassification对象。该对象存储有关训练数据、模型和优化的信息。您可以使用点表示法访问对象属性,如特性权重。
绘制特征权重。
图()图(mdl。FeatureWeights,“罗”)包含(“功能指数”)ylabel('特征重量') 网格在
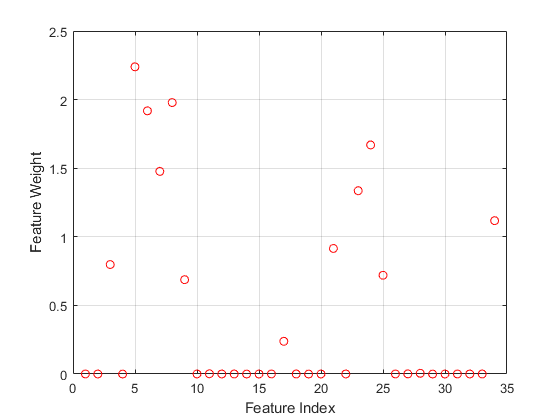
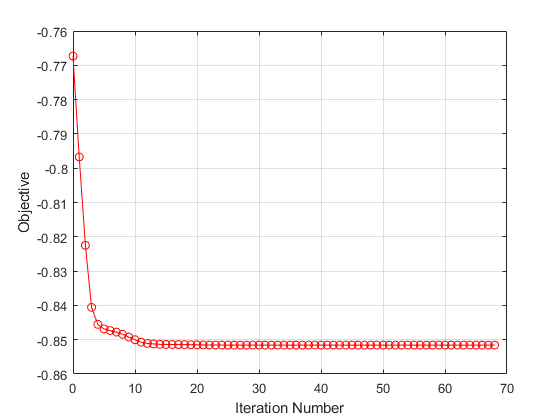
无关的特征的重量为零。的“详细”,1选项fscnca在命令行上显示优化信息。您还可以通过绘制目标函数和迭代数来可视化优化过程。
图绘制(mdl.FitInfo.Iteration mdl.FitInfo.Objective,'ro-') 网格在Xlabel(的迭代次数)ylabel(“目标”)
的ModelParameters物业是A.塑造其中包含有关模型的更多信息。您可以使用点表示法访问此属性的字段。例如,请参阅数据是否标准化。
mdl.modelparameters.standardize.
ans =.逻辑0
0意味着在拟合NCA模型之前未标准化数据。当使用时,您可以在非常不同的尺度上标准化预测器'标准化',1的调用中的名称-值对参数fscnca。
复制语义
价值。要了解值类如何影响复制操作,请参阅复制对象。
介绍了R2016b
您还可以从以下列表中选择一个网站:
