预测
类:FeatureSelectionNCAClassification
使用邻域成分分析(NCA)分类器预测响应
语法
(标签、postprobs一会)=预测(mdl, X)
输入参数
输出参数
例子
用于分类的调谐NCA模型
加载示例数据。
装载(“twodimclassdata.mat”);
使用[1]中描述的方案模拟该数据集。这是一个二维的两类分类问题。第一类(第一类)的数据来自两个二元正态分布 或
或 以相同的概率,其中
以相同的概率,其中![美元$ \ mu_1 = [-0.75, -1.5]](http://www.tatmou.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq03336482581861985583.png) ,
,![美元$ \ mu_2 = [0.75, 1.5]](http://www.tatmou.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq17527623940921012900.png) ,
, 类似地,第二类(第1类)的数据来自两个二元正态分布
类似地,第二类(第1类)的数据来自两个二元正态分布 或
或 以相同的概率,其中
以相同的概率,其中![$\mu_3=[1.5,-1.5]$](http://www.tatmou.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq02369827013796961285.png) ,
,![美元$ \ mu_4 = [-1.5, 1.5]](http://www.tatmou.com/help/examples/stats/win64/PredictClassLabelsUsingNCAModelExample_eq10119612338443584655.png) ,.用于创建该数据集的正态分布参数导致数据中的聚类比[1]中使用的数据更紧密。
,.用于创建该数据集的正态分布参数导致数据中的聚类比[1]中使用的数据更紧密。
创建按类分组的数据的散点图。
图gscatter (X (: 1), (:, 2), y)包含(x1的) ylabel (“x2”)

将100个不相关的功能添加到 .首先从均值为0、方差为20的正态分布生成数据。
.首先从均值为0、方差为20的正态分布生成数据。
n =大小(X, 1);rng (“默认”)XwithBadFeatures=[X,randn(n,100)*sqrt(20)];
规范化数据,使所有点都在0和1之间。
XwithBadFeatures = bsxfun (@rdivide,...bsxfun(@负,XwithBadFeatures,min(XwithBadFeatures,[],1)),...范围(XwithBadFeatures,1));X=XwithBadFeatures;
使用默认值对数据拟合邻域成分分析(NCA)模型λ(正则化参数, )值。使用LBFGS求解器显示收敛信息。
)值。使用LBFGS求解器显示收敛信息。
ncaMdl=fscnca(X,y,“FitMethod”,“准确”,“详细”,1,...“规划求解”,“lbfgs”);
o Solver=LBFGS,HessianHistorySize=15,LineSearchMethod=weakwolfe |=========================================================================================================================================================接受阿尔法-伽玛-标准阶阶数|================================================================================================4.015e+0.000e+4.015e+0.015e+01 | 4.015e+0 0124四四四四四四四四四四四四四四四四四四四四四个州的本本周四周四周四|124周四周四周四周四周四|124四四四四四四四四四四四四0 0 0 0 0 0\\124四四四四四四四四\124四四四四四四四四四\\\124;;||;;|;| 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 124; OK | 9.943e+01 | 1.000e+00 |是| 3 |-4.938877e-01 | 3.544e-03 | 1.464e+00 | OK | 9.366e+01 | 1.000e+00 |是| 4 |-4.964759e-01 | 23.901e-0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0是| 7 |-4.974868e-01 | 3.844e-05 | 4.161e-02 |好| 9.835e+01 | 1.000e+00 |是| 8 |-4.974874e-01 | 1.417e-05 | 1.073e-02 |好4.974874e-4.7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 4 4 4.7 7 7 7 7 7 7 7 7 7 7 4 4.893e-0 0 6 4 4.1 1 1.783 E-0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1.3 3 3 3 3 E+0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0最后一步的范数=8.947e-04,TolX=1.000e-06最终梯度的相对无穷范数=9.404e-08,TolFun=1.000e-06出口:找到本地最小值。
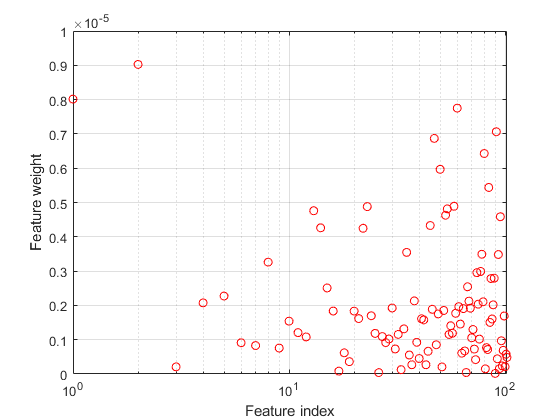
绘制特征权重。不相关特征的权重应非常接近于零。
图semilogx(ncaMdl.FeatureWeights,“罗”)xlabel(“功能索引”) ylabel (“功能重量”网格)在…上
使用NCA模型预测类并计算混淆矩阵。
ypred =预测(ncaMdl X);ypred confusionchart (y)
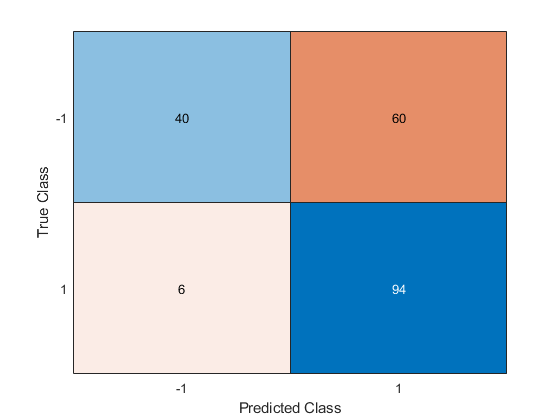
混淆矩阵显示,类别-1中的40个数据被预测为属于类别-1。类别-1中的60个数据被预测为类别1。类似地,类别1中的94个数据被预测为类别1,其中6个数据被预测为类别-1。类别-1的预测精度不高。
所有权重都非常接近于零,这表明用于训练的模型太大。当 时,所有特征权值均趋近于零。因此,在大多数情况下,调优正则化参数以检测相关特征是很重要的。
时,所有特征权值均趋近于零。因此,在大多数情况下,调优正则化参数以检测相关特征是很重要的。
使用五倍交叉验证进行优化用于通过使用进行特征选择fscnca.调谐意味着找到将产生最小分类损失的值。要调整使用交叉验证:
1.将数据划分为五个折叠。对于每个折叠,cvpartition将五分之四的数据指定为训练集,五分之一的数据指定为测试集。同样,对于每个折叠,cvpartition创建一个分层分区,其中每个分区拥有大致相同比例的类。
本量利= cvpartition (y,“kfold”,5);numtestset=cvp.numtestset;lambdavalues=linspace(0,2,20)/length(y);lossvalues=zeros(length(lambdavalues),numtestset;
2.为每个项目培训邻域成分分析(nca)模型值使用训练集在每个折叠。
3.使用nca模型计算褶皱中相应测试集的分类损失。记录损失值。
4.对所有折叠和所有折叠重复此过程值。
为i=1:长度(λ值)为k = 1: numtestsets%从分区对象中提取训练集Xtrain = X (cvp.training (k):);ytrain = y (cvp.training (k):);%从分区对象中提取测试集Xtest = X (cvp.test (k):);欧美= y (cvp.test (k):);%使用训练集训练NCA模型进行分类ncaMdl = fscnca (Xtrain ytrain,“FitMethod”,“准确”,...“规划求解”,“lbfgs”,“拉姆达”lambdavalues(我));%使用NCA计算测试集的分类损失%的模型lossvalues (i (k) =损失(ncaMdl Xtest,欧美,...“失去功能”,“二次”);结束结束
绘制褶皱的平均损失值与值。如果对应于最小损失的值落在被测的边界上值的范围价值观应该被重新考虑。
图绘制(lambdavalues,意味着(lossvalues, 2),“ro - - - - - -”)xlabel(“λ值”) ylabel (“损失价值”网格)在…上
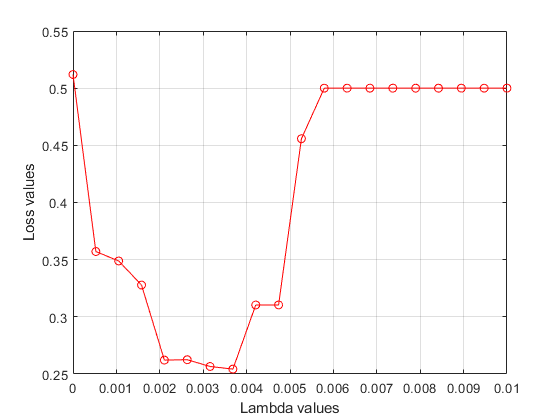
找到与最小平均损失相对应的值。
[~, idx] = min(意味着(lossvalues, 2));%查找索引bestlambda=lambdavalues(idx)找到最好的lambda值
最佳λ=0.0037
将NCA模型与所有数据进行最佳拟合价值。使用LBFGS求解器显示收敛信息。
ncaMdl=fscnca(X,y,“FitMethod”,“准确”,“详细”,1,...“规划求解”,“lbfgs”,“拉姆达”, bestlambda);
o Solver=LBFGS,HessianHistorySize=15,LineSearchMethod=weakwolfe |=========================================================================================================================================================接受阿尔法-伽玛-标准阶阶数|================================================================================================(124???????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????好的| 7.825e+01 | 1.000e+00 |是的| 3 |-5.817731e-01 | 8.496e-03 | 2.340e+00 |好的| 5.591e+01 | 5.000e-01 |是的| 4 |-6.132632e-01 |6.6.6.863 3 E-3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0“是”6.6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0|是| 7 | 6.148714e-01 | 6.392e-04 | 6.688e-02 |好| 3.195e+01 | 1.000e+00 |是| 8 |-6.1495224E-01 | 6.521e-04 | 9.934e-02 |O4.1497 7-6.9 9 9-6.1497 7-6.9 9 9 9-6.1497 7 7 7.9 9 9 9 9-6.1497 7 7 7.9 9 9 9 9-5 5-4 4 4.1.1.191e-0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.1.3 3 3 3 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 4 4 4 4 4 4 4\\12444 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4.1.1.1.1.1.1.1.1.1.1.1.1.1.1.191e-1.3-1.1.1.3-1.3-1.3 3 3-1.1 01 | 1.556e-05 | 8.354e-03 |好| 1.288e+02 | 1.000e+00 |是| 12 |-6.149994e-01 | 1.147e-05 | 7.256e-03 |好| 2.332e+02 | 1.000e+4.0 0-5 6.781e-0312444 0 0 0 0 0 0 0 0 0 0 0 4 4 4 4 4 4.781-10 10 10 10 10 10 4 4 4 4 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5 5 5 5 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 206e-03 | OK | 2.919e+02 | 1.000e+00 | YES | 16 |-6.149997e-01 | 8.374e-06 | 1.679e-02 | OK | 6.878e+02 | 1.000e+00 | YES 17 |-614.1999年9.9 9 9.9 9 9.7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 E-03“OK”1.284 E+0 0 0 0 0 0 0 0 5.4 4 4 5.9 9 9 9 9.9 9 9 9 9 9 9 9 9 9.9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 E+0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5.000e-0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 5 5 5.000e-E-0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 E-0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 5 5 5 5 5| 1.000e+00 |是| | |======================================================================================================================================================================================================================================================================================================================================================================================================第二方的第第二方的第二方的第二方的第二方的第二方的第二方的第二方的第第二方的第第二方的第第二方的第第第第二方的第第第二方的第第第二方的第第第二方的第二方的第二方的第第二方的第二方的第第二方的第第第第第二方的第第第第第第第第第第第二方的第第第第第第第第第第第第第第第第第第第第第二方的第第第第第第第第第第第第第第第第第第第第第第第第第第第二方的第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第二方的第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第第| 2.905e+02 | 1.000e+00 |是|最终坡度的无穷大范数=5.764e-07最后一步的两个范数=6.765e-04,TolX=1.000e-06最终梯度的相对无限范数=5.764e-07,TolFun=1.000e-06出口:找到局部最小值。
绘制特征权重。
图semilogx(ncaMdl.FeatureWeights,“罗”)xlabel(“功能索引”) ylabel (“功能重量”网格)在…上
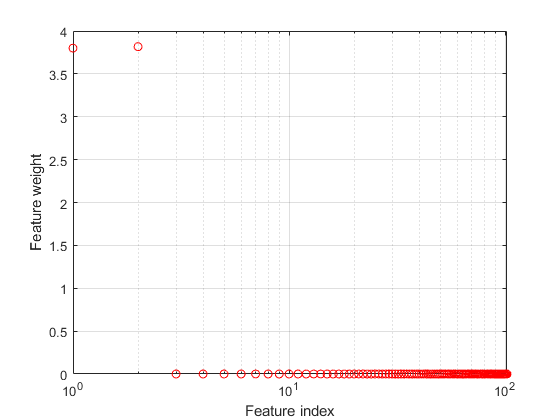
fscnca正确地指出前两个特征是相关的,而其余的则不是。前两个特征不是单独提供信息的,但当它们结合在一起时,会产生一个准确的分类模型。
使用新模型预测类别并计算精度。
ypred =预测(ncaMdl X);ypred confusionchart (y)
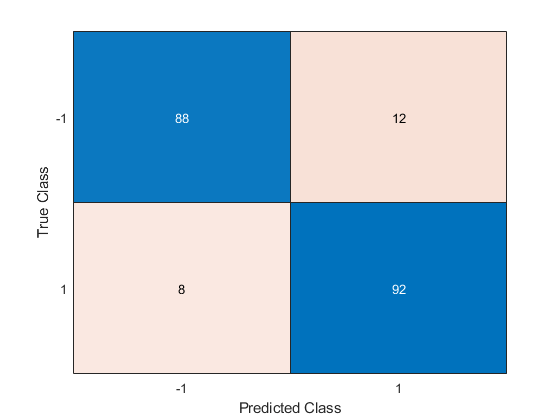
混淆矩阵表明,第1类的预测精度有所提高。88个来自-1类的数据被预测来自-1,其中12个来自1类。第1类的数据中有92个预测来自第1类,其中8个预测来自第1类。
工具书类
[1] 杨文凯,王文凯,左文凯。“高维数据的邻域组件特征选择。”计算机杂志.2012年1月,第7卷第1期。
你也可以从以下列表中选择一个网站:
