预测
班级:PeazerateLectionNcArtortion.
使用邻域成分分析(NCA)回归模型预测响应
语法
X ypred =预测(mdl)
输入参数
输出参数
例子
调整NCA模型进行回归使用损失和预测
加载样本数据。
从UCI机器学习存储库下载“住房数据”[1] [2]。数据集有506个观察结果。第一个13列包含预测值值,最后一列包含响应值。目标是预测郊区波士顿的所有者被占领的房屋的中位数,作为13个预测因子的函数。
加载数据并定义响应向量和预测器矩阵。
负载(“housing.data”);X =住房(:,1:13);y =住房(:,结束);
将数据分为训练集和测试集,使用第4个预测器作为分组变量进行分层划分。这确保了每个分区包含了来自每个组的相似数量的观察结果。
rng (1)再现性的百分比本量利= cvpartition (X (:, 4),“坚持”,56);xtrain = x(cvp.training,:);Ytrain = Y(CVP.TRAINARING,:);xtest = x(cvp.test,:);ytest = y(cvp.test,:);
cvpartition将56个观察数据随机分配到一个测试集,其余数据随机分配到一个训练集。
使用默认设置执行功能选择
使用NCA模型进行回归的功能选择。将预测值标准化。
NCA = FSRNCA(Xtrain,Ytrain,'标准化',1);
绘制特征权重。
图()绘图(nca.featurepuights,“罗”)
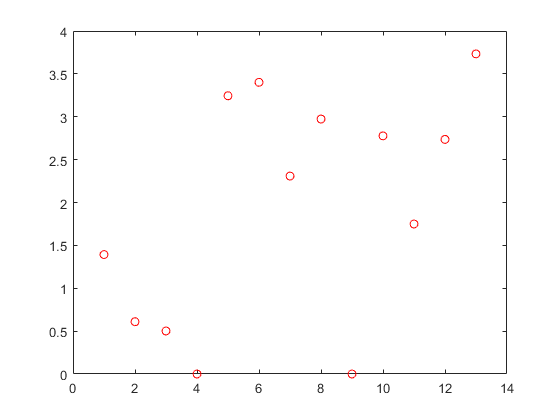
不相关特征的权值期望趋近于零。FSRNCA确定两个不相关的特征。
计算回归丢失。
L =损耗(NCA,XTEST,YTEST,“LossFunction”,“疯了”)
L = 2.5394
计算测试集的预测响应值,并将它们与实际响应进行对比。
Ypred =预测(NCA,XTEST);图()绘图(ypred,ytest,'博')Xlabel(“预测响应”)ylabel('实际反应')

完美的适合与实际值形成45度直线。在此绘图中,预测和实际响应值似乎分散在这条线上。调优 (正则化参数)值通常有助于提高性能。
使用10倍交叉验证调优正则化参数
调优 意味着找到 将产生最小回归损失的值。下面是调优的步骤 使用10倍交叉验证:
1.首先将数据分成10个部分。对于每一个褶皱,cvpartition将十分之一的数据分配为训练集,将十分之一的数据分配为测试集。
n =长度(ytrain);本量利= cvpartition (Xtrain (:, 4),“kfold”10);numvalidsets = cvp.numtestsets;
分配 值的搜索。创建一个数组来存储损失值。
lambdavals = linspace(0,2,30)* std(ytrain)/ n;lockvals = zeros(长度(lambdavals),numvalidsets);
2.训练每一个的邻域成分分析(nca)模型 使用每个折叠中的训练设置的值。
3.使用所选功能拟合高斯进程回归(GPR)模型。接下来,使用GPR模型计算折叠中的相应测试集的回归损耗。记录损失值。
4.对每一个重复此步骤 价值和每一折。
为i = 1:长度(lambdavals)为k = 1:numvalidsets X = Xtrain(cvp.training(k),:);y = ytrain (cvp.training (k):);Xvalid = Xtrain (cvp.test (k):);yvalid = ytrain (cvp.test (k):);nca = fsrnca (X, y,“FitMethod”,'精确的',...“λ”,lambdavals(i),...'标准化',1,“LossFunction”,“疯了”);%使用特征权重和一个相对值选择特征%的阈值。托尔= 1 e - 3;selidx = nca。FeatureWeights > tol *马克斯(max (nca.FeatureWeights));使用选定的特征拟合一个非ard GPR模型。探地雷达= fitrgp (X (:, selidx), y,'标准化',1,...'骨箱',“squaredexponential”,“详细”,0);损失(i,k)=损失(gpr,xvalid(:,selidx),yvalid);结束结束
计算每个折叠的平均损耗 价值。画出平均损失和 值。
meanloss =意味着(lossvals, 2);图;情节(lambdavals meanloss,'ro-');包含(“λ”);ylabel (“损失(MSE)”);网格在;
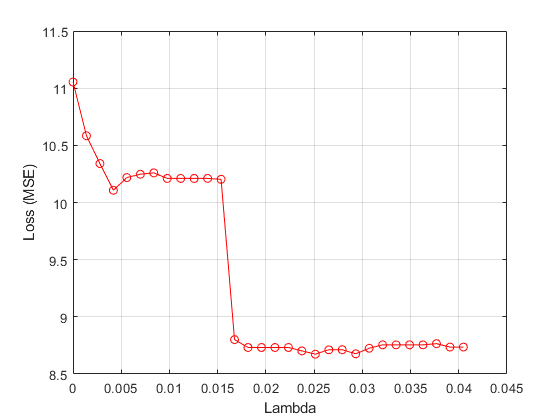
找到 值产生最小损耗值。
[〜,IDX] = min(meanloss);Bestlambda = Lambdavals(IDX)
bestlambda = 0.0251
使用最好的回归执行功能选择 价值。将预测值标准化。
nca2 = fsrnca (Xtrain ytrain,'标准化',1,“λ”,Bestlambda,...“LossFunction”,“疯了”);
绘制特征权重。
图()绘图(nca.featurepuights,“罗”)
在测试数据上使用新的nca模型计算损失,该模型不用于选择特征。
L2 =损失(nca2 Xtest,欧美,“LossFunction”,“疯了”)
L2 = 2.0560
调整正则化参数有助于识别相关特征,减少损失。
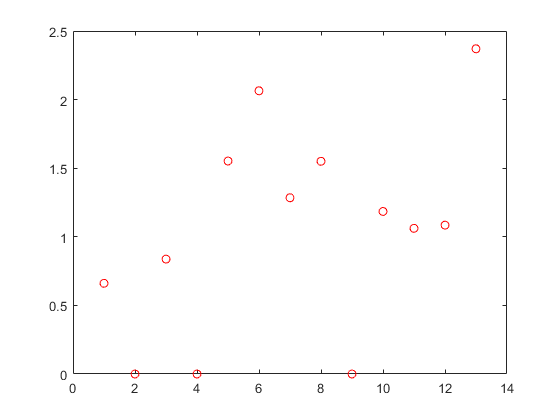
绘制测试集中的预测与实际响应值。
ypred =预测(nca2 Xtest);图;情节(ypred,欧美,'博');

预测的响应值似乎也更接近实际值。
参考
哈里森,d。和d。l。鲁宾菲尔德。"享乐价格和对清洁空气的需求"j .包围。经济学和管理。第5卷,1978年,81-102页。
[2] Lichman,M. UCI机器学习储存库,Irvine,CA:加州大学,信息学院,2013年信息学院。https://archive.ics.uci.edu/ml。
您还可以从以下列表中选择一个网站:
