gencfeatures
执行工程自动化特性分类
语法
描述
的gencfeatures函数允许您自动功能工程过程中机器学习工作流程。之前表格分类器训练数据,您可以创建新特性预测的数据通过使用gencfeatures。使用返回的数据来训练分类器。
gencfeatures允许您从变量数据类型(如生成功能datetime,持续时间和各种int类型不支持大多数分类器训练功能。金宝app由此产生的特性数据类型所支持的这些培训功能。金宝app
为了更好地理解生成的特性,使用描述函数返回的FeatureTransformer对象。应用相同的训练集功能转换到一个测试集,使用变换的函数FeatureTransformer对象。
(使用自动化特性创建工程变压器,NewTbl)= gencfeatures (资源描述,ResponseVarName,问)问特性的预测资源描述。软件假定ResponseVarName变量资源描述响应,不从这个变量创建新功能。gencfeatures返回一个FeatureTransformer对象(变压器)和一个新表(NewTbl)包含转换功能。
默认情况下,gencfeatures假设生成功能是用于火车可判断的二进制响应变量的线性模型。如果你有一个多级响应变量和你想生成特性改善的准确性袋装合奏,指定TargetLearner = "包"。
例子
解释线性模型与生成的功能
使用自动功能工程生成新特性。火车一个线性分类器使用生成的特性。解释生成的特性和训练之间的关系模型。
加载病人数据集。创建一个表的一个子集变量。显示表的前几行。
负载病人台=表(年龄、舒张压、性别、身高、SelfAssessedHealthStatus…收缩压、体重、吸烟);头(台)
ans =8×8表年龄舒张性别身高SelfAssessedHealthStatus收缩期体重吸烟者___ _____ _____ _____ ________________________ ________交38 93{‘男性’}71{‘优秀’}124 176真的43 77{‘男性’}69{‘公平’}109 163假38 83{‘女性’}64{‘好’}125 131假40 75{‘女性’}67{‘公平’}117 133假49 80{‘女性’}64{‘好’}122 119假46 70{‘女性’}68{‘好’}121 142假33 88{‘女性’}{‘好’}64 130 142真的40 82{‘男性’}{‘好’}68 115 180错误
生成10个新特性的变量资源描述。指定吸烟者变量的响应。默认情况下,gencfeatures假设的新特性将被用来训练一个二进制线性分类器。
rng (“默认”)%的再现性[T, NewTbl] = gencfeatures(资源描述,“抽烟”,10)
T = FeatureTransformer属性:类型:“分类”TargetLearner:“线性”NumEngineeredFeatures: 10 NumOriginalFeatures: 0 TotalNumFeatures: 10
NewTbl =100×11表zsc(收缩压。^ 2)eb8(舒张压)处置(收缩压)eb8(收缩压)处置(舒张压)zsc (kmd9) zsc (sin(年龄))zsc (sin(重量))zsc (Height-Systolic) zsc _______ _________________ (kmc1)吸烟者___________ * * * _________________ _____ _________________ ___________ ____________________ _____ _____ 0.15379 8 6 4 8真正-1.7207 0.50027 0.19202 0.40418 0.76177 -1.9421 - 2 1 1 2 0.30311 -0.22056 -1.1319 -0.4009 2.3431 1.1617假4 6 5 5 -0.85785 0.57695 0.50027 -1.037 -0.78898 -1.4456假2 2 2 2 -0.14125 0.83391 1.1495 1.3039 0.85162 -0.010294假3 5 4 4 -0.28697 1.779 -1.3083 -0.42387 -0.34154 0.99368假1 4 3 1 1.0677 0.67326 1.3761 -0.72529 0.40418 1.3755假6 8 6 6真正-0.42521 1.5181 -0.72529 -1.5347 -1.4456 -1.1361 - 4 2 2 5 -1.1361 -0.79995 1.1495 -1.0225 1.2991 1.1617假3 2 2 3 -0.71693 -0.80136 0.46343 1.0806 1.2991 -1.208假5 3 3 6 -1.2734 0.37961 -0.51304 0.16741 0.55333 -1.4456假2 1 1 2 -1.1361 1.2572 1.3025 1.0978 1.4482 -0.010294假1 2 2 1 0.60534 1.001 -1.2545 -1.2194 1.0008 -0.010294假1 6 5 1 1.0677 -0.98493 -0.11998 -1.211 -0.043252 -1.208假8 8 6 8 -1.2734 -0.27307 1.4659 1.2168 -0.34154 0.24706真的3 1 1 4 1.0677 0.93395 -1.3633 -0.17603 1.0008 -0.010294假7 8 6 8 -0.91396 -1.04 -1.2109 -0.49069 0.24706真实⋮
T是一个FeatureTransformer对象,可以用于将新数据,和newTbl包含新功能产生的资源描述数据。
为了更好地理解生成的特性,使用描述对象的函数FeatureTransformer对象。例如,检查前两个生成的功能。
描述(T, 1:2)
_______________________________________________________________类型IsOriginal数据源转换___________ __________ * * * zsc(收缩压。^ 2)数字虚假收缩力量(2)标准化与z分数(= 15119.54,std = 1667.5858) eb8(舒张压)分类错误的舒张Equal-width装箱(箱子的数量= 8)
第一个功能newTbl是一个数值变量,由第一个平方的值收缩压变量,然后将结果转换为z得分。第二个特性newTbl是一个分类变量,由装箱的值舒张压变量为8箱的宽度相等。
使用生成的特性适合一个线性分类器没有任何正规化。
Mdl = fitclinear (NewTbl,“抽烟”λ= 0);
情节的系数预测用于火车Mdl。请注意,fitclinear扩展分类预测拟合模型。
p =长度(Mdl.Beta);[sortedCoefs, expandedIndex] = (Mdl.Beta ComparisonMethod =“abs”);sortedExpandedPreds = Mdl.ExpandedPredictorNames (expandedIndex);栏(sortedCoefs水平=“上”)yticks (1:2: p) yticklabels (sortedExpandedPreds(1:2:结束)包含(“系数”)ylabel (“扩展预测”)标题(“扩大了预测系数”)
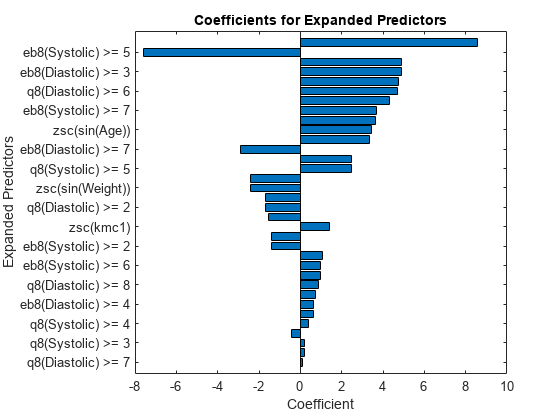
确定系数的预测有较大的绝对值。
bigCoefs = abs (sortedCoefs) > = 4;翻转(sortedExpandedPreds (bigCoefs))
ans =1 x7单元格列1到3 {zsc(收缩压。^ 2)”}{“eb8(收缩压)…'}{处置(舒张压)…“}”列4到6 {eb8(舒张压)…'}{(收缩压)> = 6处置的}{”游戏(舒张压)…'}列7 {“zsc (Height-Sys…”}
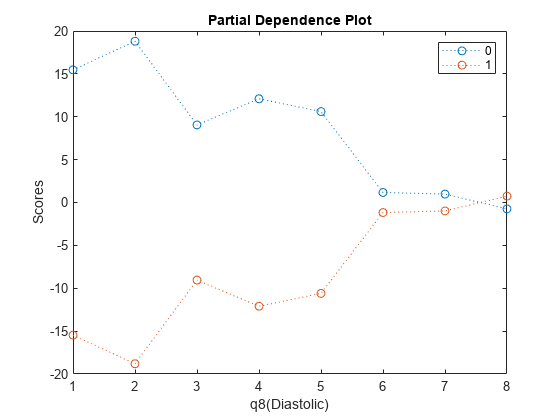
您可以使用部分依赖情节分析水平的分类特征系数的绝对值。例如,检查的部分依赖图处置(舒张压)变量的水平(舒张压)> = 3和(舒张压)> = 6与大型系数绝对值。这两个水平对应明显预测评分的变化。
plotPartialDependence (Mdl“处置(舒张压)”、Mdl.ClassNames NewTbl);
改善可线性模型的准确性
生成新特性来提高模型精度可判断的线性模型。比较线性模型的精度测试集训练对测试集的原始数据精度的线性模型训练转变特性。
加载电离层数据集。转换矩阵的预测X一个表。
负载电离层台= array2table (X);
分区数据分为训练集和测试集。使用大约70%的观测数据作为训练数据,和30%的观测数据作为测试数据。分区数据使用cvpartition。
rng (“默认”)%的再现性分区本量利= cvpartition (Y,坚持= 0.3);trainIdx =培训(cvp);trainTbl =(资源(培训(cvp):);trainY = Y (trainIdx);testIdx =测试(cvp);testTbl =(资源(testIdx:);暴躁的= Y (testIdx);
使用训练数据来生成45新特性。检查返回的FeatureTransformer对象。
[T, newTrainTbl] = gencfeatures (trainTbl trainY 45);T
T = FeatureTransformer属性:类型:“分类”TargetLearner:“线性”NumEngineeredFeatures: 45 NumOriginalFeatures: 0 TotalNumFeatures: 45
所有生成的特性设计功能而不是原始的特征trainTbl。
应用转换存储在对象T测试数据。
newTestTbl =变换(T, testTbl);
比较线性分类器的测试集的表演训练在原始特性和线性分类器训练的新特性。
适合没有改变数据的线性模型。检查测试集的性能使用混淆矩阵模型。
originalMdl = fitclinear (trainTbl trainY);originalPredictedLabels =预测(originalMdl testTbl);厘米= confusionchart(暴躁的,originalPredictedLabels);

confusionMatrix = cm.NormalizedValues;originalTestAccuracy =总和(诊断接头(confusionMatrix)) /笔(confusionMatrix,“所有”)
originalTestAccuracy = 0.8952
符合线性模型转换后的数据。检查测试集的性能使用混淆矩阵模型。
newMdl = fitclinear (newTrainTbl trainY);newPredictedLabels =预测(newMdl newTestTbl);newcm = confusionchart(暴躁的,newPredictedLabels);

newConfusionMatrix = newcm.NormalizedValues;newTestAccuracy =总和(诊断接头(newConfusionMatrix)) /笔(newConfusionMatrix,“所有”)
newTestAccuracy = 0.9048
线性分类器训练对转换后的数据似乎比原始数据的线性分类器训练。
产生新的特性来提高袋装整体精度
使用gencfeatures之前工程师新功能训练袋装系综分类器。之前预测新数据,应用相同的功能转换到新的数据集。比较测试集的性能,使用工程特性的测试集性能,使用原始的特性。
样例文件读取CreditRating_Historical.dat一个表中。预测数据由财务比率和企业客户的行业信息列表。响应变量由评级机构的信用评级分配。预览数据集的前几行。
creditrating = readtable (“CreditRating_Historical.dat”);头(creditrating)
ans =8×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业评级_____持续累积________ _____ ________ 62394 0.013 0.104 0.036 0.447 0.142 3 {“BB”} 48608 0.232 0.335 0.062 1.969 0.281 8 {A} 42444 0.311 0.367 0.074 1.935 0.366 1 {A} 48631 0.194 0.263 0.062 1.017 0.228 - 4 {BBB的}43768 0.121 0.413 0.057 3.647 0.466 12 {' AAA '} 39255 -0.117 -0.799 0.01 0.179 0.082 - 4 {“CCC”} 62236 0.087 0.158 0.049 0.816 0.324 - 2 {BBB的}39354 0.005 0.181 0.034 2.597 0.388 7 {“AA”}
因为每个值ID变量是一个独特的客户ID,即长度(独特(creditrating.ID))等于观测的数量creditrating,ID变量是一个可怜的预测。删除ID从表中变量和转换行业变量,分类变量。
creditrating = removevars (creditrating,“ID”);creditrating。行业= categorical(creditrating.Industry);
转换评级响应变量的顺序分类变量。
creditrating。评级= categorical(creditrating.Rating,…(“AAA”,“AA”,“一个”," BBB ",“BB”,“B”,“CCC”),序数= true);
分区数据分为训练集和测试集。使用大约75%的观测数据作为训练数据,和25%的观测数据作为测试数据。分区数据使用cvpartition。
rng (“默认”)%的再现性分区c = cvpartition (creditrating.Rating,坚持= 0.25);trainingIndices =培训(c);%训练集的指标testIndices =测试(c);%测试集的指标creditTrain = creditrating (trainingIndices:);信贷= creditrating (testIndices:);
使用训练数据来生成40个新特性以适应袋装合奏。默认情况下,40特性包括原始特性,可以作为预测袋装合奏。
[T, newCreditTrain] = gencfeatures (creditTrain“评级”现年40岁的…TargetLearner =“包”);T
T = FeatureTransformer属性:类型:“分类”TargetLearner:“袋子”NumEngineeredFeatures: 34 NumOriginalFeatures: 6 TotalNumFeatures: 40
创建newCreditTest通过应用转换存储在对象T测试数据。
newCreditTest =变换(T,信贷);
比较测试集表演袋装合奏训练的原始特性和袋装合奏训练的新特性。
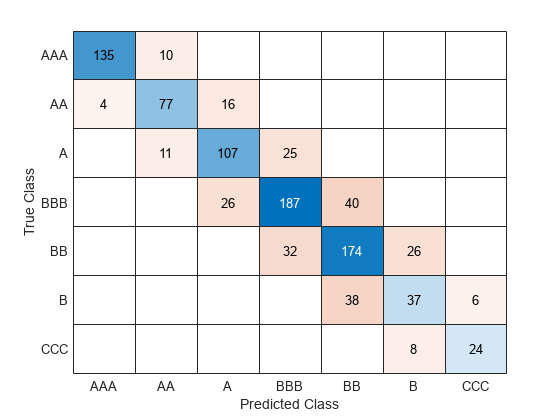
使用原始训练集训练袋装合奏creditTrain。计算模型的准确性对原来的测试集信贷。可视化结果使用混淆矩阵。
originalMdl = fitcensemble (creditTrain,“评级”方法=“包”);originalTestAccuracy = 1 -损失(originalMdl,信贷,…“评级”LossFun =“classiferror”)
originalTestAccuracy = 0.7604
predictedTestLabels =预测(originalMdl、信贷);confusionchart (creditTest.Rating predictedTestLabels);
使用转换后的训练集训练袋装合奏newCreditTrain。计算模型的准确性测试集转换newCreditTest。可视化结果使用混淆矩阵。
newMdl = fitcensemble (newCreditTrain,“评级”方法=“包”);newTestAccuracy = 1 -损失(newMdl newCreditTest,…“评级”LossFun =“classiferror”)
newTestAccuracy = 0.7501
newPredictedTestLabels =预测(newMdl newCreditTest);confusionchart (newCreditTest.Rating newPredictedTestLabels)
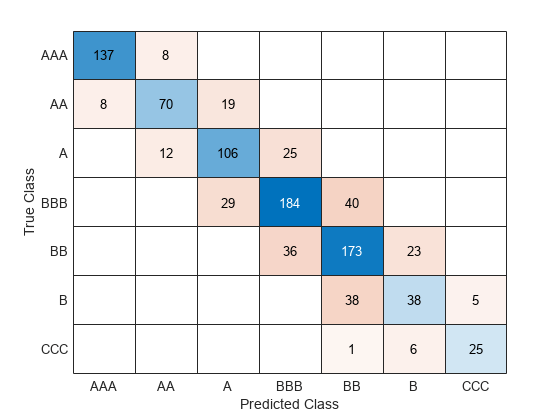
袋装合奏训练对转换后的数据似乎比袋装合奏训练有素的原始数据。
使用生成的特性计算交叉验证损失
生成特征来训练一个线性分类器。计算模型的交叉验证分类错误使用crossval函数。
加载电离层数据集,并创建一个包含预测的数据表。
负载电离层台= array2table (X);
创建一个随机的分区分层5倍交叉验证。
rng (“默认”)%的再现性分区本量利= cvpartition (Y, KFold = 5);
计算线性模型的交叉验证分类损失训练的原始特性资源描述。
CVMdl = fitclinear(资源描述,Y, CVPartition =利;cvloss = kfoldLoss (CVMdl)
cvloss = 0.1339
创建自定义函数myloss(如图所示的这个例子)。这个函数生成20从训练数据特征,然后同样的训练集转换适用于测试数据。然后函数符合线性分类器训练数据和计算测试集的损失。
注意:如果你使用现场脚本文件对于本例,myloss功能已经包含在文件的末尾。否则,您需要创建这个函数的m文件或将它添加在MATLAB®文件路径。
计算线性模型的交叉验证分类损失训练特征产生的预测因子资源描述。
newcvloss =意味着(crossval (@myloss台,Y,分区=利)
newcvloss = 0.0686
函数testloss = myloss (TrainTbl trainY TestTbl,暴躁的)[变压器,NewTrainTbl] = gencfeatures (TrainTbl trainY 20);NewTestTbl =变换(变压器、TestTbl);Mdl = fitclinear (NewTrainTbl trainY);testloss =损失(Mdl NewTestTbl,暴躁的,…LossFun =“classiferror”);结束
输入参数
输出参数
提示
默认情况下,当
TargetLearner是“线性”,数值预测的软件生成新功能通过使用z得分(见TransformedDataStandardization)。你可以改变的类型的标准化转换功能。然而,使用一些标准化的方法,从而避免了“没有”规范,强烈建议。与标准化数据线性模型拟合效果最好。
