主要内容
测试整体质量
您不能根据集成在训练数据上的性能来评估它的预测质量。组合倾向于“过度训练”,这意味着它们对自己的预测能力做出了过于乐观的估计。这意味着结果resubLoss分类(resubLoss用于回归)通常表示比在新数据上得到的错误更低。
为了更好地了解一个整体的质量,可以使用以下方法之一:
在一个独立的测试集上评估集成(当您有大量的训练数据时很有用)。
通过交叉验证(在没有大量训练数据时很有用)评估集成。
评估包外数据的集成(在创建包内集成时很有用
fitcensemble或fitrensemble).
本例使用了袋装集成,因此可以使用所有三种评估集成质量的方法。
生成一个具有20个预测器的人工数据集。每个条目都是0到1之间的随机数。最初的分类是 如果 和 否则。
rng (1,“旋风”)%的再现性X =兰特(2000年,20);Y = sum(X(:,1:5),2) > 2.5;
此外,为了在结果中添加噪声,随机切换10%的分类。
idx = randsample(2000、200);(idx) = ~ Y (idx);
独立的测试集
创建独立的训练和测试数据集。通过调用将70%的数据用于训练集cvpartition使用坚持选择。
cvpart = cvpartition (Y,“坚持”, 0.3);Xtrain = X(培训(cvpart):);Ytrain = Y(培训(cvpart):);Xtest = X(测试(cvpart):);欧美= Y(测试(cvpart):);
从训练数据中创建一个包含200棵树的袋装分类集合。
t = templateTree (“复制”,真正的);%用于随机预测器选择的重现性袋= fitcensemble (Xtrain Ytrain,“方法”,“包”,“NumLearningCycles”, 200,“学习者”, t)
包= ClassificationBaggedEnsemble ResponseName: 'Y' CategoricalPredictors: [] ClassNames: [0 1] ScoreTransform: 'none' NumObservations: 1400 NumTrained: 200 Method: ' bag ' LearnerNames: {'Tree'} ReasonForTermination: '在完成请求的训练周期数后正常终止。'userobsforlearner: [1400x200 logical]属性,方法
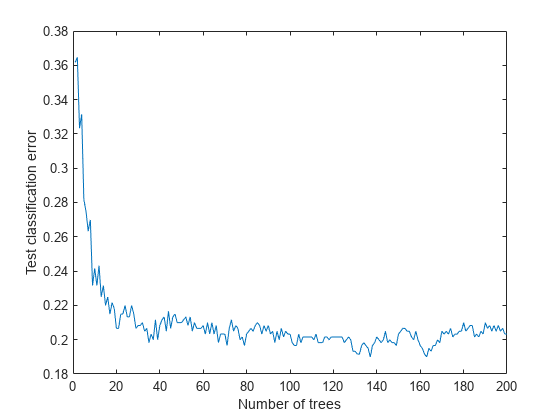
将测试数据的损失(误分类)作为集合中训练树的数量的函数绘制出来。
图绘制(损失(包,Xtest,欧美,“模式”,“累积”)包含(树木的数量) ylabel (“测试分类错误”)
交叉验证
生成一个五折交叉验证袋套装。
简历= fitcensemble (X, Y,“方法”,“包”,“NumLearningCycles”, 200,“Kfold”5,“学习者”, t)
cv = ClassificationPartitionedEnsemble CrossValidatedModel: 'Bag' PredictorNames: {1x20 cell} ResponseName: 'Y' NumObservations: 2000 KFold: 5 Partition: [1x1 cvpartition] NumTrainedPerFold: [200 200 200 200 200] ClassNames: [0 1] ScoreTransform: 'none'属性,方法
将交叉验证损失作为集合中树数量的函数进行检查。
图绘制(损失(包,Xtest,欧美,“模式”,“累积”)举行在情节(kfoldLoss(简历,“模式”,“累积”),“r”。)举行从包含(树木的数量) ylabel (分类错误的)传说(“测试”,交叉验证的,“位置”,“不”)

交叉验证给出了独立集的可比估计。
Out-of-Bag估计
生成包外估计的损失曲线,并将其与其他曲线一起绘制。
图绘制(损失(包,Xtest,欧美,“模式”,“累积”)举行在情节(kfoldLoss(简历,“模式”,“累积”),“r”。)情节(oobLoss(包,“模式”,“累积”),“k——”)举行从包含(树木的数量) ylabel (分类错误的)传说(“测试”,交叉验证的,的包的,“位置”,“不”)

包外估计再次与其他方法的估计相比较。
另请参阅
cvpartition|fitcensemble|fitrensemble|kfoldLoss|损失|oobLoss|resubLoss|resubLoss
相关的话题
你也可以从以下列表中选择一个网站:
