主要内容
优化增强回归集成
这个例子展示了如何优化增强回归集成的超参数。优化使模型的交叉验证损失最小化。
问题是根据汽车的加速度、发动机排量、马力和重量,以每加仑汽油的英里数来模拟汽车的效率。加载carsmall数据,其中包含这些和其他预测因素。
负载carsmallX =[加速度位移马力重量];Y = MPG;
拟合回归集成到数据使用LSBoost算法,以及使用代理分割。通过改变学习周期的数量、代理拆分的最大数量和学习率来优化结果模型。此外,允许优化在每个迭代之间重新划分交叉验证。
为了重现性,设置随机种子并使用“expected-improvement-plus”采集功能。
rng (“默认”Mdl = fitrensemble(X,Y,...“方法”,“LSBoost”,...“学习者”templateTree (“代孕”,“上”),...“OptimizeHyperparameters”, {“NumLearningCycles”,“MaxNumSplits”,“LearnRate”},...“HyperparameterOptimizationOptions”结构(“再分配”,真的,...“AcquisitionFunctionName”,“expected-improvement-plus”))
|====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | NumLearningC - | LearnRate | MaxNumSplits | | | |结果日志(1 +损失)运行时| |(观察)| (estim) |永昌龙 | | | |====================================================================================================================| | 最好1 | | 3.5219 | 20.079 | 3.5219 | 3.5219 | 383 | 0.51519 | 4 | | 2 |最好| 3.4752 | 0.83429 | 3.4752 | 3.4777 | 16 | 0.66503 | 7 | | 3 |的| 3.1575 | 1.5792 | 3.1575 | 3.1575 | 33 | 0.2556 | 92 | | 4 |接受| 6.3076 | 0.87828 | 3.1575 | 3.1579 | 13 | 0.0053227 | 5 | | 5 |接受| 3.4449 | 11.803 | 3.1575 | 3.1579 | 277 | 0.45891 | 99 | | 6 |接受| 3.9806 | 0.62494 | 3.1575 | 3.1584 | 33 10 | 0.13017 | | |最好7 | | 3.059 | 0.45984 | 3.059 | 3.06 | 10 | 0.30126 | 3 | | 8 |接受| 3.1707 | 0.98218 | 3.059 | 3.1144 | 10 | 0.28991 | 15 | | | 9日接受| 3.0937 | 0.78937 | 3.059 | 3.1046 | 10 | 0.31488 | 13 | | |接受10 | 3.196 | 0.56298 | 3.059 | 3.1233 | 10 | 0.32005 | 11 | | 11最好| | 3.0495 | 0.48452 | 3.0495 | 3.1083 | 0.27882 | | 85 | |最好12 | | 2.946 | 1.2095 | 2.946 | 3.0774 | 10 | 0.27157 | 7 | | | 13日接受| 3.2026 | 0.54187 | 2.946 | 3.0995 | 10 | 0.25734 | 20 | | | 14日接受| 5.7151 | 14.348 | 2.946 | 3.0996 | 376 | 0.001001 | 43 | | | 15日接受| 3.207 | 19.037 | 2.946 | 3.0937 | 499 | 0.027394 | 18 | | | 16日接受| 3.8606 | 1.9099 | 2.946 | 3.0937 | 36 | 0.041427 |12 | | | 17日接受| 3.2026 | 18.422 | 2.946 | 3.095 | 443 | 76 | 0.019836 | | | 18日接受| 3.4832 | 7.4091 | 2.946 | 3.0956 | 205 | 0.99989 | 8 | | | 19日接受| 5.6285 | 9.0913 | 2.946 | 3.0942 | 192 | 0.0022197 | 2 | | |接受20 | 3.0896 | 8.1 | 2.946 | 3.0938 | 188 | 0.023227 | 93 ||====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | NumLearningC - | LearnRate | MaxNumSplits | | | |结果日志(1 +损失)运行时| |(观察)| (estim) |永昌龙 | | | |====================================================================================================================| | 21日|接受| 3.1408 | 6.89 | 2.946 | 3.0935 | 156 | 0.02324 | 5 | | |接受| 4.691 | 0.63904 | 2.946 | 3.0941 | 12 | 0.076435 | 2 | | | 23日接受| 5.4686 | 2.0784 | 2.946 | 3.0935 | 58 50 | 0.0101 | | | | 24日接受| 6.3759 | 1.0794 | 2.946 | 3.0893 | 0.0014716 | | 23日22日| | | 25日接受| 6.1278 | 1.9941 | 2.946 | 3.094 | 47 | 0.0034406 | 2 | | | 26日接受| 5.9134 | 0.61233 | 2.946 | 3.0969 | 11 | 0.024712 | 12 || 27 | Accept | 3.401 | 5.7575 | 2.946 | 3.0995 | 151 | 0.067779 | 7 | | 28 | Accept | 3.2757 | 8.5287 | 2.946 | 3.1009 | 198 | 0.032311 | 8 | | 29 | Accept | 3.2296 | 0.88442 | 2.946 | 3.1023 | 17 | 0.30283 | 19 | | 30 | Accept | 3.2385 | 3.1546 | 2.946 | 3.1027 | 83 | 0.21601 | 76 |
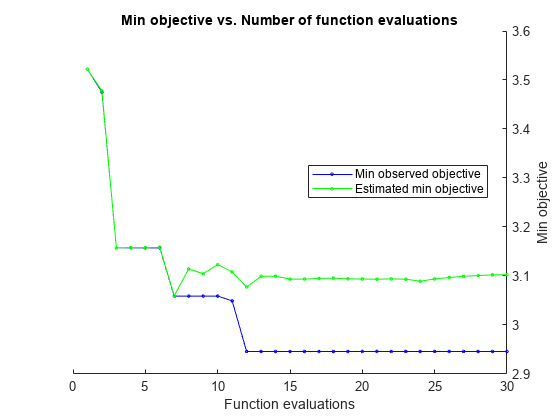
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:181.9637秒总目标函数计算时间:150.7641最佳观测可行点:NumLearningCycles LearnRate maxnumspl_________________ _________ ____________ 10 0.27157 7观察到的目标函数值= 2.946估计的目标函数值= 3.1219函数评估时间= 1.2095最佳估计可行点(根据模型):NumLearningCycles LearnRate maxnumsplit _________________ _________ ____________ 10 0.30126 3估计的目标函数值= 3.1027估计的函数评估时间= 0.65461
Mdl = RegressionEnsemble ResponseName:‘Y’CategoricalPredictors: [] ResponseTransform:“没有一个”NumObservations: 94 HyperparameterOptimizationResults: [1 x1 BayesianOptimization] NumTrained: 10个方法:“LSBoost”LearnerNames:{‘树’}ReasonForTermination:“终止通常在完成训练周期的请求的数量。正则化:[]属性,方法
将损失与一个增强的、未优化的模型以及与默认集成的损失进行比较。
损失= kfoldLoss (crossval (Mdl,“kfold”10))
损失= 19.2667
Mdl2 = fitrensemble (X, Y,...“方法”,“LSBoost”,...“学习者”templateTree (“代孕”,“上”));loss2 = kfoldLoss (crossval (Mdl2“kfold”10))
loss2 = 30.4083
Mdl3 = fitrensemble (X, Y);loss3 = kfoldLoss (crossval (Mdl3“kfold”10))
loss3 = 29.0495
关于优化这个集成的另一种方法,请参见使用交叉验证优化回归集成.
你也可以从以下列表中选择一个网站:
