固定效果面板模型具有并发相关性
此示例显示如何使用面板数据分析mvregress..首先,利用普通最小二乘法(OLS)拟合出具有并行相关性的固定效应模型。然后,利用估计误差协方差矩阵得到回归系数的面板校正标准误差。
加载样本数据。
加载示例面板数据。
加载Paneldata.
数据集数组,Paneldata.,含有八个城市的年度观察6年。这是模拟数据。
定义变量。
第一个变量,生长,衡量经济增长(响应变量)。第二个和第三个变量分别是城市和年度指标。最后变量,采用,措施就业(预测变量)。
y = paneldata.growth;城市= Paneldata.City;年= paneldata.year;x = paneldata.employ;
按类别对数据进行分组。
要查找潜在的城市特定的固定效果,请创建由城市分组的响应的盒子图。
图()boxplot(y,city)xlabel('城市')
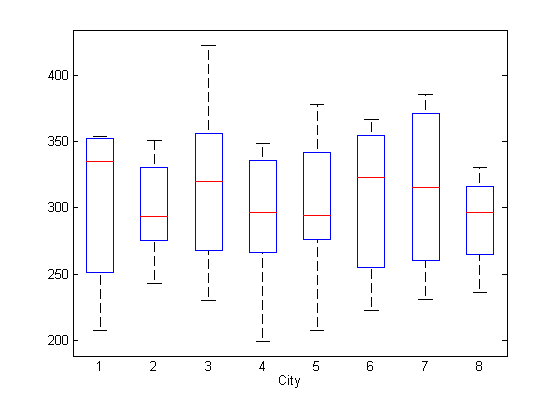
城市之间的平均反应似乎没有任何系统差异。
绘制由不同类别分组的数据。
要查找潜在的年度特定的固定效果,请创建一年中分组的响应的框绘图。
图()boxplot(y,年)xlabel('年')

似乎存在于岁月之间的平均反应中系统差异的一些证据。
格式响应数据。
让yIJ.表示对城市的回应j= 1,......,D.,在一年中一世= 1,......,N.相似地,XIJ.是预测变量的相应值。在这个例子中,N= 6和D.= 8。
考虑拟合一年特定的固定效果模型,同年城市之间的持续坡度和并发相关性,
在哪里 .同时存在的相关性解释了任何无法测量的、时间静态的因素,这些因素可能对某些城市的增长产生类似的影响。例如,空间接近的城市可能更有可能有相似的经济增长。
使用此模型使用mvregress.,将响应数据重写为一个N-经过-D.矩阵。
n = 6;d = 8;Y = REPAPE(Y,N,D);
格式化设计矩阵。
创建一个长度,N细胞阵列D.-经过-K.设计矩阵。对于这个模型,有K.= 7个参数(D.= 6个截距项和一个斜率)。
假设参数的向量被安排为
在这种情况下,第一年的第一个设计矩阵是这样的
第二年的第二个设计矩阵是这样的
其余4年的设计矩阵是相似的。
k = 7;n = n * d;x =单元格(n,1);为了i = 1:n x0 = 0 (d,K-1);x0(:,我)= 1;X{我}= (x0, X(我:n: n)];结尾
适合模型。
使用普通最小二乘(OLS)拟合模型。
[b,团体,E, V] = mvregress (X, Y,'算法'那'cwls');B.
B = 41.6878 26.1864 -64.5107 11.0924 -59.1872 71.3313 4.9525
绘图拟合模型。
xx = linspace(min(x),max(x));AXX = REPMAT(B(1:K-1),1,长度(XX));bxx = repmat(b(k)* xx,n,1);Yhat = Axx + Bxx;图()hpepts = g箭偶(x,y,年);抓住在线=情节(xx, yhat);为了i = 1: n组(线(我),'颜色'得到(hPoints(我),'颜色'));结尾抓住离开

具有年度特定拦截和公共斜率的模型似乎非常适合数据。
残余相关性。
绘制剩余的残留物,逐年分组。
图()g箭牌(年,E(:),城市)ylabel('残留')
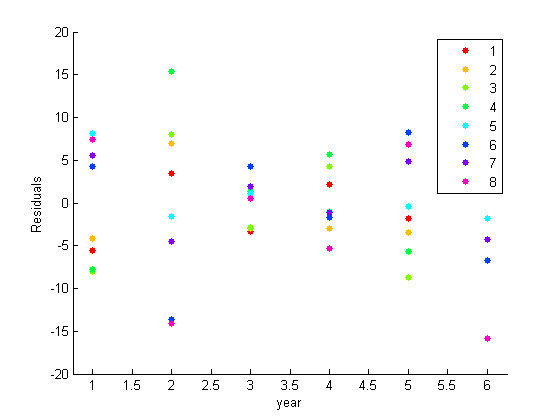
残差图表明存在并发相关。例如,第1、2、3和4个城市作为一个整体在任何一年里都是高于或低于平均水平的。对于城市5、6、7和8的集合也是如此。正如在探索地块中所看到的,没有系统的城市特定效应。
面板修正了标准误差。
使用估计的误差方差 - 协方差矩阵来计算面板纠正的回归系数的标准错误。
XX = cell2mat (X);S = kron(眼(n)、团体);Vpcse =发票(XX * XX) * XX的* * XX *发票(XX ' * XX);se =√诊断接头(Vpcse))
Se = 9.3750 8.6698 9.3406 9.4286 9.5729 8.8207 0.1527
也可以看看
相关例子
更多关于
你也可以从以下列表中选择一个网站:
