预测
利用回归神经网络预测反应
描述
例子
利用回归神经网络预测测试集响应
利用训练好的回归神经网络模型预测测试集的响应值。
加载病人数据集。从数据集中创建一个表。每一行对应一个病人,每列对应一个诊断变量。使用收缩压变量作为响应变量,其余变量作为预测变量。
负载病人tbl = table(年龄,舒张压,性别,身高,吸烟,体重,收缩压);
将数据分成一个训练集tblTrain和一个测试集tblTest通过使用非分层坚持分区。该软件为测试数据集保留大约30%的观测值,并将其余观测值用于训练数据集。
rng (“默认”)用于分区的再现性C = cvpartition(size(tbl,1),“坚持”, 0.30);trainingIndices = training(c);testIndices =测试(c);tblTrain = tbl(trainingIndices,:);tblTest = tbl(testIndices,:);
使用训练集训练回归神经网络模型。指定收缩压列的tblTrain作为响应变量。指定以标准化数值预测器。默认情况下,神经网络模型有一个全连接层和10个输出,不包括最终的全连接层。
Mdl = fitrnet(tblTrain,“收缩”,...“标准化”,真正的);
预测测试集中患者的收缩压水平。
predictedY = predict(Mdl,tblTest);
通过使用带有参考线的散点图来可视化结果。沿纵轴绘制预测值,沿横轴绘制真实响应值。参考线上的点表示正确的预测。
情节(tblTest。收缩压,预测edY,“。”)举行在情节(tblTest.Systolic tblTest.Systolic)从包含(“真实收缩压水平”) ylabel (“预测收缩压水平”)

由于许多点远离参考线,默认的神经网络模型具有大小为10的完全连接层,似乎不能很好地预测收缩压水平。
选择回归神经网络中要包含的特征
通过比较测试集损失和预测来执行特征选择。将使用所有预测器训练的回归神经网络模型的测试集指标与仅使用预测器子集训练的模型的测试集指标进行比较。
加载示例文件fisheriris.csv,其中包含虹膜数据,包括萼片长度、萼片宽度、花瓣长度、花瓣宽度和物种类型。将文件读入表。
渔场=可读表(“fisheriris.csv”);
将数据分成一个训练集trainTbl和一个测试集testTbl通过使用非分层坚持分区。该软件为测试数据集保留大约30%的观测值,并将其余观测值用于训练数据集。
rng (“默认”) c = cvpartition(size(fishtable,1),“坚持”, 0.3);trainTbl =渔场(训练(c),:);testTbl = fishtable (test(c),:);
使用训练集中的所有预测器训练一个回归神经网络模型,并使用训练集中的所有预测器训练另一个模型PetalWidth.对于这两个模型,请指定PetalLength作为响应变量,并对预测函数进行标准化。
allMdl = fitrnet(trainTbl,“PetalLength”,“标准化”,真正的);subsetMdl = fitrnet(trainTbl,“PetalLength ~ SepalLength + SepalWidth + Species”,...“标准化”,真正的);
比较两个模型的测试集均方误差(MSE)。MSE值越小,性能越好。
allMSE = loss(allMdl,testTbl)
allMSE = 0.0856
subsetMSE = loss(subsetMdl,testTbl)
subsetMSE = 0.0881
对于每个模型,将测试集预测的花瓣长度与真实的花瓣长度进行比较。沿纵轴绘制预测花瓣长度,沿横轴绘制真实花瓣长度。参考线上的点表示正确的预测。
tiledlayout (2, 1)%顶轴Ax1 = nexttile;allPredictedY = predict(allMdl,testTbl);情节(ax₁,testTbl。PetalLength,allPredictedY,“。”)举行在情节(ax₁,testTbl.PetalLength testTbl.PetalLength)从包含(ax₁“真实花瓣长度”) ylabel (ax₁,“预计花瓣长度”)标题(ax₁,“预测”)%底轴Ax2 = nexttile;subsetPredictedY = predict(subsetMdl,testTbl);情节(ax2 testTbl。PetalLength,subsetPredictedY,“。”)举行在情节(ax2、testTbl.PetalLength testTbl.PetalLength)从包含(ax2,“真实花瓣长度”) ylabel (ax2,“预计花瓣长度”)标题(ax2,“预测因子子集”)
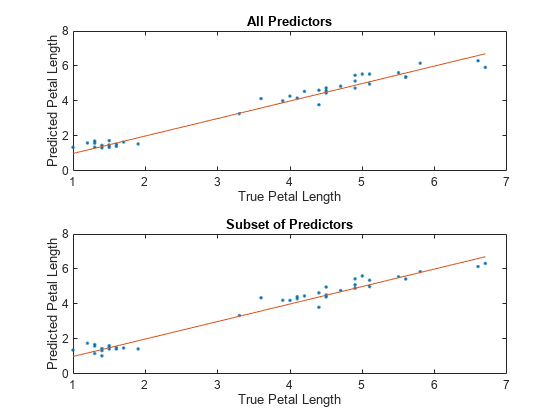
因为这两个模型似乎都表现得很好,预测分散在参考线附近,考虑使用使用所有预测器训练的模型PetalWidth.
回归神经网络模型的层结构预测
了解回归神经网络模型的各层如何协同工作以预测单个观测的响应值。
加载示例文件fisheriris.csv,其中包含虹膜数据,包括萼片长度、萼片宽度、花瓣长度、花瓣宽度和物种类型。将文件读入一个表,并显示表的前几行。
渔场=可读表(“fisheriris.csv”);头(fishertable)
ans =8×5表SepalLength SepalWidth PetalLength PetalWidth物种 ___________ __________ ___________ __________ __________ 5.1 3.5 1.4 1.4 0.2 4.9{‘setosa} 3{‘setosa} 4.7 3.2 1.3 0.2 0.2{‘setosa} 4.6 3.1 1.5 0.2{‘setosa} 5 3.6 1.4 0.2{‘setosa} 5.4 3.9 1.7 0.4{‘setosa} 4.6 3.4 1.4 0.3{‘setosa} 5 3.4 1.5 0.2 {' setosa '}
使用数据集训练回归神经网络模型。指定PetalLength变量作为响应,并使用其他数值变量作为预测器。
Mdl = fitrnet(渔场表,“PetalLength ~ SepalLength + SepalWidth + PetalWidth”);
从数据集中选择第15个观测值。看看神经网络的各层是如何获取观察结果并返回预测的响应值的newPointResponse.
newPoint = Mdl。X{15日:}
newPoint =1×35.8000 4.0000 0.2000
firstFCStep = (Mdl.LayerWeights{1})*newPoint' + Mdl.LayerBiases{1};reluStep = max(firstFCStep,0);finalFCStep = (Mdl.LayerWeights{end})*reluStep + Mdl.LayerBiases{end};newPointResponse = finalFCStep
newPointResponse = 1.6716
方法返回的预测是否匹配预测对象的功能。
predictedY = predict(Mdl,newPoint)
predictedY = 1.6716
isequal (newPointResponse predictedY)
ans =逻辑1
这两个结果是一致的。
输入参数
您也可以从以下列表中选择一个网站:
