Train and Compare Classifiers Using Misclassification Costs in Classification Learner App
This example shows how to create and compare classifiers that use specified misclassification costs in the Classification Learner app. Specify the misclassification costs before training, and use the accuracy and total misclassification cost results to compare the trained models.
In the MATLAB®Command Window, read the sample file
CreditRating_Historical.datinto a table. The predictor data consists of financial ratios and industry sector information for a list of corporate customers. The response variable consists of credit ratings assigned by a rating agency. Combine all theAratings into one rating. Do the same for theBandCratings, so that the response variable has three distinct ratings. Among the three ratings,Ais considered the best andCthe worst.creditrating = readtable('CreditRating_Historical.dat'); Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,{'AAA','AA','A'},'A'); Rating = mergecats(Rating,{'BBB','BB','B'},'B'); Rating = mergecats(Rating,{'CCC','CC','C'},'C'); creditrating.Rating = Rating;
Assume these are the costs associated with misclassifying the credit ratings of customers.
客户预测评级 ABCCustomer True Rating A$0 $100 $200 B$500 $0 $100 C$1000 $500 $0 For example, the cost of misclassifying a
Crating customer as anArating customer is $1000. The costs indicate that classifying a customer with bad credit as a customer with good credit is more costly than classifying a customer with good credit as a customer with bad credit.Create a matrix variable that contains the misclassification costs. Create another variable that specifies the class names and their order in the matrix variable.
ClassificationCosts = [0 100 200; 500 0 100; 1000 500 0]; ClassNames = categorical({'A','B','C'});Tip
Alternatively, you can specify misclassification costs directly inside the Classification Learner app. SeeSpecify Misclassification Costsfor more information.
Open Classification Learner. Click theAppstab, and then click the arrow at the right of theAppssection to open the apps gallery. In theMachine Learning and Deep Learninggroup, clickClassification Learner.

On theClassification Learnertab, in theFilesection, selectNew Session > From Workspace.
In the New Session from Workspace dialog box, select the table
creditratingfrom theData Set Variablelist.如d所示ialog box, the app selects the response and predictor variables based on their data type. The default response variable is the
Ratingvariable. The default validation option is cross-validation, to protect against overfitting. For this example, do not change the default settings.
To accept the default settings, clickStart Session.
Specify the misclassification costs. On theClassification Learnertab, in theOptionssection, clickMisclassification Costs. The app opens a dialog box showing the default misclassification costs.
In the dialog box, click进口from Workspace.
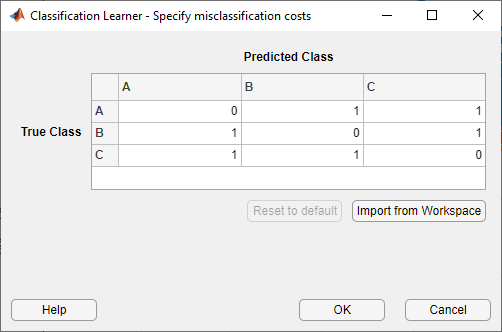
In the import dialog box, select
ClassificationCostsas the cost variable andClassNamesas the class order in the cost variable. Click进口.
The app updates the values in the misclassification costs dialog box. ClickOKto save your changes.

Train fine, medium, and coarse trees simultaneously. On theClassification Learnertab, in theModel Type部分,单击加勒比海盗ow to open the gallery. In theDecision Treesgroup, clickAll Trees. In theTrainingsection, clickTrain. The app trains one of each tree model type and displays the models in theModelspane.
Tip
If you have Parallel Computing Toolbox™, you can train all the models (All Trees) simultaneously by selecting theUse Parallelbutton in theTrainingsection before clickingTrain. After you clickTrain, the Opening Parallel Pool dialog box opens and remains open while the app opens a parallel pool of workers. During this time, you cannot interact with the software. After the pool opens, the app trains the models simultaneously.

Note
Validation introduces some randomness into the results. Your model validation results can vary from the results shown in this example.
In theModelspane, click a model to view the results, which are displayed in theCurrent Model Summarypane. Each model has a validation accuracy score that indicates the percentage of correctly predicted responses. In theModelspane, the app highlights the highestAccuracy (Validation)score by outlining it in a box.
Inspect the accuracy of the predictions in each class. On theClassification Learnertab, in thePlots部分,单击加勒比海盗ow to open the gallery, and then clickConfusion Matrix (Validation)in theValidation Resultsgroup. The app displays a matrix of true class and predicted class results for the selected model (in this case, for the medium tree).

You can also plot results per predicted class to investigate false discovery rates. UnderPlot, select thePositive Predictive Values (PPV)False Discovery Rates (FDR)option.
In the confusion matrix for the medium tree, the entries below the diagonal have small percentage values. These values indicate that the model tries to avoid assigning a credit rating that is higher than the true rating for a customer.

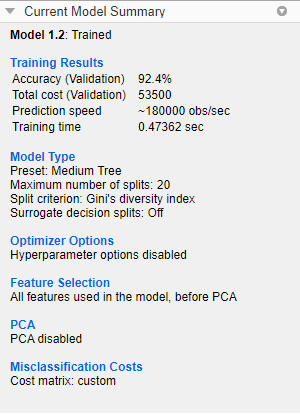
Compare the total misclassification costs of the tree models. To inspect the total misclassification cost of a model, select the model in theModelspane, and then view theTraining Resultssection of theCurrent Model Summarypane. For example, the medium tree has these results.
Alternatively, you can sort the models based on the total misclassification cost. In theModelspane, open theSort bylist and select
Total Cost (Validation).In general, choose a model that has high accuracy and low total misclassification cost. In this example, the medium tree has the highest validation accuracy value and the lowest total misclassification cost of the three models.









You can perform feature selection and transformation or tune your model just as you do in the workflow without misclassification costs. However, always check the total misclassification cost of your model when assessing its performance. For differences in the exported model and exported code when you use misclassification costs, seeMisclassification Costs in Exported Model and Generated Code.
Related Topics
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select:.
Selectweb siteYou can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)
