分类学习者应用程序中的误分类成本
默认情况下,Classification Learner应用程序创建的模型对训练期间的所有错误分类都给予同样的惩罚。对于一个给定的观察,如果该观察被正确分类,应用程序将分配一个惩罚为0,如果该观察被错误分类,则分配一个惩罚为1。在某些情况下,这种分配是不合适的。例如,假设您想将病人分为健康或疾病两类。将一个病人误分类为健康的成本可能是将一个健康人误分类为疾病的成本的五倍。如果您知道将一个类的观察错误分类为另一个类的代价,并且这种代价在不同的类之间是不同的,那么在训练模型之前指定错误分类代价。
请注意
自定义误分类成本不支持logistic回归和神经网络模型。金宝app
指定错误分类代价
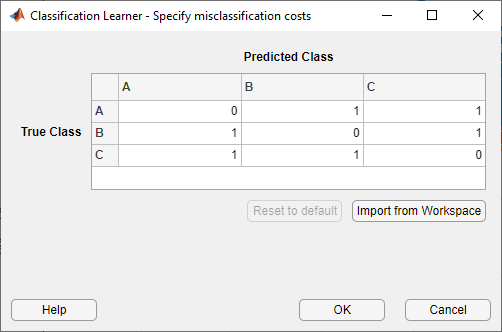
在分类学习者应用程序中,在选项部分的分类学习者选项卡上,选择误分类代价.应用程序打开一个对话框,显示默认的误分类成本(成本矩阵),作为一个表,由响应变量中的类决定行和列标签。表中的行对应于真实的类,列对应于预测的类。你可以这样解释成本矩阵:一行的条目我和列j是分类错误的代价吗我本班观察到j类。代价矩阵的对角项必须为0,非对角项必须为非负实数。
您可以通过两种方式指定错误分类成本:直接在对话框的表中输入值,或者导入包含成本值的工作区变量。
请注意
成本矩阵的缩放版本给出了相同的分类结果(例如,混淆矩阵和准确率),但总误分类成本不同。也就是说,如果CostMat误分类成本矩阵和一个是正的实标量,然后是用代价矩阵训练的模型a * CostMat和那个模型训练的混淆矩阵是一样的吗CostMat.
在对话框中直接输入成本
在错误分类成本对话框中,双击要编辑的表中的条目。删除该值并为条目键入正确的误分类开销。编辑完表后,单击好吧保存更改。
导入包含成本的工作区变量
在误分类代价对话框中,单击从工作区进口.该应用程序打开一个对话框,用于从MATLAB中的变量导入成本®工作区。

从成本变量列表,选择包含误分类成本的成本矩阵或结构。
代价矩阵——这个矩阵必须包含错误分类的代价。对角线项必须是0,非对角线项必须是非负实数。默认情况下,应用程序使用前面错误分类成本对话框中显示的类顺序来解释成本矩阵值。
要指定成本矩阵中类的顺序,请创建一个独立的工作区变量,以正确的顺序包含类名。在导入对话框中,从类别顺序在成本可变列表。包含类名的工作区变量必须是类别向量、逻辑向量、数字向量、字符串数组或字符向量的单元格数组。类名必须与响应变量中的类名(在拼写和大写方面)匹配。
结构——结构必须包含字段
ClassificationCosts和一会这些规范:ClassificationCosts-包含误分类成本的矩阵。一会-类名。班级的顺序一会的行和列的顺序ClassificationCosts.的变量一会必须是类别向量、逻辑向量、数字向量、字符串数组或字符向量的单元格数组。类名必须与响应变量中的类名(在拼写和大写方面)匹配。
在成本变量中指定成本变量和类顺序后,单击进口.app更新误分类成本对话框中的表格。
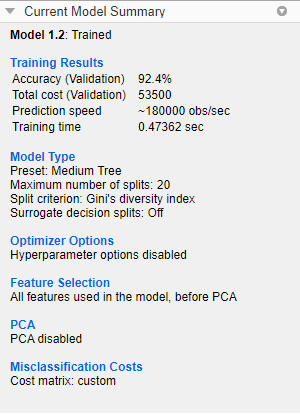
当你指定一个不同于默认值的成本矩阵后,应用程序会更新当前模型的总结窗格用于新模型。在当前模型的总结窗格中,在误分类代价,该应用程序将成本矩阵列为“自定义”。对于使用默认错误分类成本的模型,应用程序将成本矩阵列为“默认”。

评估模型的性能
在指定错误分类成本之后,您可以像往常一样训练和调整模型。然而,使用自定义错误分类成本可能会改变您评估模型性能的方式。例如,不要选择精度最好的模型,而要选择精度好、总误分类代价低的模型。模型的总误分类代价为总和(CostMat。* ConfusionMat,“所有”),在那里CostMat误分类成本矩阵和ConfusionMat为模型的混淆矩阵。混淆矩阵显示了模型如何对每个类中的观察结果进行分类。看到在混淆矩阵中检查每个类的表现.
为了检验训练模型的总误分类代价,在中选择模型模型窗格。在当前模型的总结窗格,看培训结果部分。总误分类成本列于模型的准确性以下。
导出模型和生成代码中的误分类成本
在你用自定义错误分类成本训练模型并从应用程序中导出它之后,你可以在导出的模型中找到自定义成本。例如,如果您将树模型导出为名为trainedModel,您可以使用以下代码访问成本矩阵和矩阵中类的顺序。
trainedModel.ClassificationTree.Cost trainedModel.ClassificationTree.ClassNames
成本属性被重置为默认代价矩阵,但是之前属性更新。
当您为使用自定义误分类代价训练的模型生成MATLAB代码时,生成的代码包括通过“成本”名称-值对的论点。
相关的话题
你也可以从以下列表中选择一个网站:
