选择分类器选项
选择分类器类型
你可以使用分类学习器在你的数据上自动训练不同的分类模型。使用自动化培训来快速尝试模型类型的选择,然后交互地探索有希望的模型。要开始,请先尝试以下选项:

| Get Started分类器按钮 | 描述 |
|---|---|
| 所有Quick-To-Train | 先试试这个。该应用程序将训练所有可用的模型类型的数据集,通常是快速适应。 |
| 全线性 | 如果您希望数据中的类之间有线性边界,请尝试此方法。该选项仅适用于线性支持向量机和线性判别器。 |
| 所有 | 使用此选项可以训练所有可用的不可优化模型类型。培训每种类型,而不考虑任何先前培训过的型号。可能很耗时。 |
看见自动分类器训练.
如果您想一次浏览一个分类器,或者您已经知道您想要的分类器类型,您可以选择单个模型或训练一组相同类型的分类器。要查看所有可用的分类器选项,请在分类学习者选项卡中单击箭头模型类型节以展开分类器列表。中不可优化的模型选项模型类型gallery是具有不同设置的预设起点,适用于一系列不同的分类问题。要使用可优化的模型选项并自动调整模型超参数,请参见分类学习者应用中的HyperParameter优化.
有关为您的问题选择最佳分类器类型的帮助,请参阅显示不同监督学习算法典型特征的表格。使用该表作为最终选择算法的指南。决定在速度、内存使用、灵活性和可解释性方面的权衡。最佳分类器类型取决于您的数据。
提示
为了避免过度拟合,要寻找灵活性较低但提供足够精度的模型。例如,寻找简单的模型,如决策树和判别器,它们快速且易于解释。如果模型不能足够准确地预测响应,可以选择具有更高灵活性的其他分类器,如集成器。要控制灵活性,请参阅每个分类器类型的详细信息。
分类器类型的特征
| 分级机 | 预测的速度 | 内存使用情况 | 解释性 |
|---|---|---|---|
| 决策树 |
快速的 | 小的 | 容易的 |
| 判别分析 |
快速的 | 小表示线性,大表示二次 | 容易的 |
| 对数几率回归 |
快速的 | 媒介 | 容易的 |
| 朴素贝叶斯分类器 |
简单分布的介质 对于内核分布或高维数据,速度较慢 |
对于简单分布来说较小 内核分布或高维数据的媒介 |
容易的 |
| 介质的线性 为别人慢 |
中等,适合线性。 所有其他:medium for multiclass, large for binary。 |
简单的线性支持向量机。 对于所有其他内核类型来说都很困难。 |
|
| 最近邻分类器 |
缓慢的立方 介质为他人 |
媒介 | 硬 |
| 集成分类器 |
快到媒介取决于算法的选择 | 根据算法的选择从低到高 | 硬 |
| 神经网络分类器 |
快速的 | 媒介 | 硬 |
这个页面上的表格描述了所有不可优化的预设分类器的速度和内存使用的一般特征。用不同的数据集(多达7000个观察值、80个预测值和50个类)对分类器进行了测试,结果定义了以下组:
速度
快0.01秒
中等1秒
缓慢的100秒
记忆力
小型1MB
中等4MB
大容量100MB
这些表格提供了一般的指导。您的结果取决于您的数据和机器的速度。
要阅读分类学习者中每个分类器的描述,请切换到详细视图。

提示
选择分类器类型(例如,决策树)后,尝试使用每个分类器进行训练。中的不可优化选项模型类型画廊是具有不同设置的起点。尝试所有选项以其数据提供哪些选项,使用您的数据产生最佳模型。
有关工作流说明,请参见在分类学习者应用程序中训练分类模型.
分类预测的支持金宝app
在分类学习者中模型类型图库显示支持所选数据的分类器类型可用。金宝app
| 分级机 | 所有的预测数字 | 所有预测分类 | 有些是绝对的,有些是数字的 |
|---|---|---|---|
| 决策树 | 是的 | 是的 | 是的 |
| 判别分析 | 是的 | 没有 | 没有 |
| 对数几率回归 | 是的 | 是的 | 是的 |
| 朴素贝叶斯 | 是的 | 是的 | 是的 |
| 支持向量机 | 是的 | 是的 | 是的 |
| 最近的邻居 | 欧氏距离只有 | 汉明距离只有 | 没有 |
| 乐团 | 是的 | 是的,除了子空间判别式 | 是的,除了任何子空间 |
| 神经网络 | 是的 | 是的 | 是的 |
决策树
决策树易于解释、拟合和预测速度快、内存使用量低,但预测精度较低。尝试种植简单的树木,以防止过度拟合。控件控制深度最大拆分数设置。
提示
模型的灵活性随着最大拆分数设置。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 粗树 |
快速的 | 小的 | 容易的 | 低 少量叶片在类之间产生粗糙的区别(最大分裂数为4)。 |
| 中树 |
快速的 | 小的 | 容易的 | 媒介 中等数量的叶子,以便在类之间进行更细微的区分(最大分裂次数为20次)。 |
| 好树 |
快速的 | 小的 | 容易的 | 高 许多叶子在类之间做出许多细微的区别(最大分裂次数为100)。 |
提示
在模型类型点击画廊所有的树尝试每个非优化的决策树选项。培训他们所有人都可以查看哪些设置使用您的数据产生最佳型号。选择最佳模型模型窗格。要想改进您的模型,请尝试特性选择,然后尝试更改一些高级选项。
你训练分类树来预测对数据的响应。要预测响应,请按照树中从根(开始)节点到叶节点的决策进行操作。叶节点包含响应。统计和机器学习工具箱™树是二进制的。预测的每一步都需要检查一个预测器(变量)的值。例如,这是一个简单的分类树:

这棵树基于两个预测器来预测分类,x1和x2.要预测,从最上面的节点开始。在每次决策时,检查预测器的值,以决定遵循哪个分支。当分支到达叶节点时,数据被分类为类型0或1..
您可以通过从应用程序导出模型,然后输入以下内容来可视化决策树模型:
视图(trainedModel.ClassificationTree,“模式”,“图”)
fisheriris数据

提示
例如,请参见使用分类学习程序训练决策树.
高级树选项
分类学习器中的分类树使用fitctree函数。你可以设置这些选项:
最大拆分数
指定分割点或分支点的最大数目,以控制树的深度。当您生长决策树时,请考虑它的简单性和预测能力。要更改分割的数目,请单击按钮或在最大拆分数盒子。
一棵有许多叶子的好树在训练数据上通常是非常精确的。然而,在一个独立的测试集上,树可能不会显示出可比的准确性。多叶树容易过度训练,其验证精度通常远低于其训练(或重新替换)精度。
相比之下,粗树的训练精度不高。但粗糙树的鲁棒性更强,因为它的训练精度可以接近具有代表性的测试集。而且,一棵粗糙的树很容易解释。
划分的标准
指定拆分何时拆分节点的拆分标准度量。尝试三个设置中的每一个,以查看它们是否与数据改进模型。
分割条件选项有
Gini的多样性指数,二重法则,或最大限度减少异常(也称为交叉熵)。分类树试图优化到只包含一个类的纯节点。基尼多样性指数(默认值)和偏差标准测量节点杂质。twoing规则是决定如何分割节点的不同度量,其中最大化twoing规则表达式可提高节点纯度。
有关这些分割条件的详细信息,请参见
ClassificationTree.更多关于.代理决定分裂-仅针对丢失数据。
指定决策分割的代理使用。如果数据缺少值,可以使用代理分割来提高预测的准确性。
当您设置代理决定分裂来
在,分类树在每个分支节点上最多找到10个代理项拆分。要更改数字,请单击按钮或在列表中输入正整数值每个节点最大代理数盒子。当您设置代理决定分裂来
找到所有,分类树查找每个分支节点上的所有代理分割。这个找到所有设置可以使用相当多的时间和内存。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
判别分析
判别分析由于其快速、准确和易于解释而成为一种流行的首选分类算法。判别分析适用于较宽的数据集。
判别分析假设不同的类根据不同的高斯分布生成数据。为了训练分类器,拟合函数估计每个类的高斯分布参数。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 线性判别式 |
快速的 | 小的 | 容易的 | 低 创建类之间的线性边界。 |
| 二次判别 |
快速的 | 大 | 容易的 | 低 创建类之间的非线性边界(椭圆,抛物线或双曲线)。 |
高级判别选项
判别分析在分类学习者中使用fitcdiscr.函数。对于线性和二次判别,你可以改变协方差结构选择。如果你有方差为零的预测器或者你的预测器的协方差矩阵是奇异的,使用默认值训练会失败,完整的协方差结构。如果训练失败,选择对角协方差结构。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
对数几率回归
如果你有两个类,逻辑回归是一种流行的简单分类算法,因为它很容易解释。分类器将分类概率建模为预测器的线性组合的函数。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 对数几率回归 |
快速的 | 媒介 | 容易的 | 低 您不能更改任何参数来控制模型的灵活性。 |
Logistic回归在分类学习者中使用fitglm函数。你不能在应用程序中为这个分类器设置任何选项。
朴素贝叶斯分类器
朴素贝叶斯分类器易于解释,对多类分类很有用。朴素贝叶斯算法利用贝叶斯定理,假设预测器在给定类的条件下是独立的。如果独立假设对数据中的预测器有效,请使用这些分类器。然而,当独立假设不成立时,该算法仍然可以很好地工作。
对于内核朴素贝叶斯分类器,您可以使用内核类型设置,并控制核平滑密度支持金宝app金宝app设置。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 高斯天真贝父 |
媒介 对于高维数据,速度较慢 |
小的 高维数据介质 |
容易的 | 低 您不能更改任何参数来控制模型的灵活性。 |
| 内核朴素贝叶斯 |
慢 | 媒介 | 容易的 | 媒介 您可以更改的设置内核类型和金宝app控制分类器模型如何预测分布。 |
朴素贝叶斯在分类学习器中使用Fitcnb.函数。
高级朴素贝叶斯选项
对于核朴素贝叶斯分类器,你可以设置以下选项:
内核类型—指定内核平滑类型。尝试设置每一个选项,看看它们是否改进了您的数据模型。
内核类型选项有
高斯,盒子,叶帕涅奇尼科夫,或三角形.金宝app—指定内核平滑密度支持。金宝app尝试设置每一个选项,看看它们是否改进了您的数据模型。
金宝app支持选项
无限的(所有真实值)或积极的(所有正的真实值)。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
有关下一步训练模型,请参见在分类学习者应用程序中训练分类模型.
金宝app支持向量机
在分类学习器中,当你的数据有两个或更多类时,你可以训练支持向量机。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 线性支持向量机 |
二:快速 多类:中等 |
媒介 | 容易的 | 低 在类之间进行简单的线性分离。 |
| 二次SVM |
二:快速 多类:慢 |
二:中等 多类:大 |
硬 | 媒介 |
| 立方支持向量机 |
二:快速 多类:慢 |
二:中等 多类:大 |
硬 | 媒介 |
| 细高斯支持向量机 |
二:快速 多类:慢 |
二:中等 多类:大 |
硬 | 高-降低与内核规模设置。 在类之间进行细致的区分,内核比例设置为 倍根号(P) / 4. |
| 介质高斯支持向量机 |
二:快速 多类:慢 |
二:中等 多类:大 |
硬 | 媒介 中等差别,内核规模设置为 sqrt(P). |
| 粗高斯支持向量机 |
二:快速 多类:慢 |
二:中等 多类:大 |
硬 | 低 对类进行粗区分,内核规模设置为 sqrt(P)*4,其中P是预测值的数量。 |
提示
尝试训练每个非可优化的支持向量机选项金宝app模型类型陈列室对他们进行培训,以了解哪些设置可以使用您的数据生成最佳模型。在列表中选择最佳模型模型窗格。要想改进您的模型,请尝试特性选择,然后尝试更改一些高级选项。
支持向量机通过寻找最好的超平面将一类数据点从另一类数据点中分离出来来分类数据。支持向量机的最佳超平面是指在两个类之间有最大的余量的超平面。边际是指平行于没有内部数据点的超平面的板的最大宽度。
这个金宝app支持向量是离分离超平面最近的数据点;这些点都在板的边界上。下图说明了这些定义,+表示类型1的数据点,-表示类型- 1的数据点。

支持向量机还可以使用软边界,这意味着一个超平面分离许多但不是所有的数据点。
例如,请参见火车支持矢量金宝app机器使用分类学习者应用程序.
高级SVM选项
如果您正好有两个类,分类学习者将使用fitcsvm.函数来训练分类器。如果你有两个以上的类,应用程序会使用fitcecoc函数将多类分类问题简化为一组二值分类子问题,每个子问题对应一个SVM学习器。要检查二进制和多类分类器类型的代码,可以从应用程序中训练的分类器生成代码。
您可以在应用程序中设置这些选项:
核函数
指定用于计算分类器的Kernel函数。
线性核,最容易解释
高斯或径向基函数(RBF)核
二次
立方
箱约束水平
指定方框约束,使拉格朗日乘数的允许值保持在一个方框中,一个有界区域。
要优化SVM分类器,请尝试增加框约束级别。单击按钮或在中输入正标量值箱约束水平盒子。增加框约束水平可以减少支持向量的数量,但也可以增加训练时间。金宝app
长方体约束参数是原始方程中称为C的软边界惩罚,在对偶方程中是硬“长方体”约束。
内核扩展模式
如果需要,请指定手动内核伸缩。
当您设置内核扩展模式来
汽车,然后软件采用启发式程序选择尺度值。启发式过程使用子抽样。因此,为了再现结果,设置随机数种子使用rng在训练分类器之前。当您设置内核扩展模式来
手册,则可以指定一个值。单击按钮或在中输入正标量值手动内核规模盒子。该软件将预测矩阵的所有元素除以核尺度的值。然后,软件应用合适的核范数来计算Gram矩阵。提示
模型灵活性随着内核规模的设置而降低。
多类方法
仅适用于包含3个或更多类的数据。该方法将多类分类问题简化为一组二值分类子问题,每个子问题对应一个SVM学习器。
一对一为每对班级训练一名学习者。它学会了区分不同的类。一vs-all每节课培训一名学员。它学会区分一个阶级和所有其他阶级。标准化数据
指定是否缩放每个坐标距离。如果预测器有很大的不同尺度,标准化可以提高拟合。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
最近邻分类器
最近的邻邻分类器通常具有低维度的良好预测精度,但可能不在高维度。他们有很高的内存使用量,并不容易解释。
提示
模型的灵活性随数量的邻居设置。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 好资讯 |
媒介 | 媒介 | 硬 | 类之间的细微差别。邻居数设置为1。 |
| 媒介资讯 |
媒介 | 媒介 | 硬 | 阶级之间的中等差别。设置邻居数为10。 |
| 粗糙的资讯 |
媒介 | 媒介 | 硬 | 阶级之间的粗略区分。邻居数设置为100。 |
| 余弦资讯 |
媒介 | 媒介 | 硬 | 使用余弦距离度量,类之间的中等差别。设置邻居数为10。 |
| 立方资讯 |
慢 | 媒介 | 硬 | 使用立方距离度量,类之间的中等区别。设置邻居数为10。 |
| 加权资讯 |
媒介 | 媒介 | 硬 | 等级之间的中等差别,使用距离权重。设置邻居数为10。 |
提示
尝试训练每个不可优化的最近邻选项模型类型陈列室对他们进行培训,以了解哪些设置可以使用您的数据生成最佳模型。在列表中选择最佳模型模型窗格。要想改进您的模型,请尝试特性选择,然后(可选地)尝试更改一些高级选项。
是什么K-最近邻分类法?根据查询点到训练数据集中的点(或邻居)的距离对查询点进行分类是对新点进行分类的一种简单而有效的方法。您可以使用各种度量来确定距离。给定一组X的N点和距离函数,K最近的邻居(K搜索让你找到K最近的点X到查询点或一组点。K基于神经网络的算法被广泛用作机器学习的基准规则。
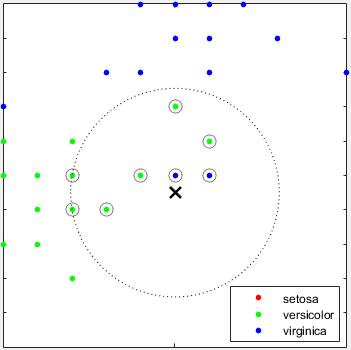
例如,请参见使用分类学习应用程序训练最近邻分类器.
高级KNN选项
最近邻分类器在分类学习中使用fitcknn函数。你可以设置这些选项:
数量的邻居
指定要查找的最近邻数量,以便在预测时对每个点进行分类。通过改变邻居的数量来指定精细(低数量)或粗分类器(高数量)。例如,精细KNN使用一个邻居,而粗KNN使用100个邻居。许多邻居可能要花很多时间才能适应。
距离度量
您可以使用各种度量来确定到点的距离。有关定义,请参见类
ClassificationKNN.距离重量
指定距离加权函数。你可以选择
平等的(没有重量),逆(重量是1/距离),或者平方反比(重量是1 /距离2.).标准化数据
指定是否缩放每个坐标距离。如果预测器有很大的不同尺度,标准化可以提高拟合。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
集成分类器
集成分类器将许多弱学习器的结果融合成一个高质量的集成模型。质量取决于算法的选择。
提示
模型的灵活性随着许多学习者设置。
所有的集成分类器适应起来都比较慢,因为它们通常需要很多学习者。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 集合法 | 模型的灵活性 |
|---|---|---|---|---|---|
| 提高了树 |
快速的 | 低 | 硬 | 演算法,决策树学习者 |
中到高-随增加许多学习者或最大拆分数设置。 提示 boost树通常比bagged做得更好,但可能需要参数调整和更多的学习器 |
| 套袋树 |
媒介 | 高 | 硬 | 随机森林包,决策树学习者 |
高增长许多学习者设置。 提示 首先尝试这个分类器。 |
| 子空间判别 |
媒介 | 低 | 硬 | 子空间,判别学习者 |
中等-随年龄增长而增长许多学习者设置。 对许多预测者来说都是好事 |
| 子空间资讯 |
媒介 | 媒介 | 硬 | 子空间,最近的邻居学习者 |
中等-随年龄增长而增长许多学习者设置。 对许多预测者来说都是好事 |
| RUSBoost树 |
快速的 | 低 | 硬 | RUSBoost,决策树学习者 |
中等-随年龄增长而增长许多学习者或最大拆分数设置。 对于扭曲的数据很好(1类有更多的观察) |
| 文件中没有提供模型类型画廊。 如果您有2个类数据,请手动选择。 |
快速的 | 低 | 硬 | GentleBoost或LogitBoost,决策树学习者选择 提高了树和改变GentleBoost方法。 |
中等-随年龄增长而增长许多学习者或最大拆分数设置。 仅用于二进制分类 |
袋装树使用Breiman's“随机森林”算法。如需参考,请参阅Breiman, L. Random Forests。机器学习45,pp. 5-32, 2001。
提示
先试试袋装的树。增强树通常可以做得更好,但可能需要搜索许多参数值,这非常耗时。
控件中的每个不可优化的集成分类器选项模型类型陈列室对他们进行培训,以了解哪些设置可以使用您的数据生成最佳模型。在列表中选择最佳模型模型窗玻璃要尝试改进模型,请尝试特征选择、PCA,然后(可选)尝试更改一些高级选项。
对于增强集成方法,您可以使用更深的树或更多数量的浅树获得详细信息。与单树分类器一样,深度树也会导致过拟合。您需要进行实验,为集合中的树选择最佳的树深度,以便在数据拟合与树的复杂性之间进行权衡。使用许多学习者和最大拆分数设置。
例如,请参见使用分类学习应用程序训练集成分类器.
高级合奏选项
分类学习者的集合分类器使用fitcensemble函数。你可以设置这些选项:
帮忙选择整体方法和学习者类型,请参见Ensemble表。先试试预设。
最大拆分数
对于增强集成方法,指定最大分割或分支点的数量,以控制树学习器的深度。许多分支倾向于过度拟合,简单的树可能更健壮,也更容易解释。实验为集合中的树选择最佳的树深度。
许多学习者
试着改变学习者的数量,看看你是否能改进这个模型。许多学习者可以产生较高的准确性,但可能需要花费时间来适应。先从几十个学员开始,然后检查他们的表现。一个具有良好预测能力的集成可能需要几百个学习者。
学习率
指定收缩的学习速率。如果将学习速率设置为小于1,则集成需要更多的学习迭代,但通常会获得更好的精度。0.1是一个常用的选择。
子空间维数
对于子空间集成,指定每个学习者中要采样的预测器数量。该应用程序为每个学习者随机选择预测因子的子集。不同学习者选择的子集是独立的。
或者,您可以让应用程序通过使用超参数优化自动选择一些模型选项。看见分类学习者应用中的HyperParameter优化.
神经网络分类器
神经网络模型通常具有良好的预测精度,可用于多类分类;然而,它们并不容易解释。
模型的灵活性随着神经网络中全连接层的大小和数量的增加而增加。
提示
在模型类型画廊,点击所有的神经网络![]() 尝试每个预设的神经网络选项,并查看哪些设置使用数据产生最佳模型。选择最佳模型模型窗格,并尝试通过使用特性选择和更改一些高级选项来改进该模型。
尝试每个预设的神经网络选项,并查看哪些设置使用数据产生最佳模型。选择最佳模型模型窗格,并尝试通过使用特性选择和更改一些高级选项来改进该模型。
| 分类器类型 | 预测的速度 | 内存使用情况 | 解释性 | 模型的灵活性 |
|---|---|---|---|---|
| 狭窄的神经网络 |
快速的 | 媒介 | 硬 | 中等-随年龄增长而增长每个完全连接层的大小背景 |
| 中神经网络 |
快速的 | 媒介 | 硬 | 中等-随年龄增长而增长每个完全连接层的大小背景 |
| 广泛的神经网络 |
快速的 | 媒介 | 硬 | 中等-随年龄增长而增长每个完全连接层的大小背景 |
| 双层神经网络 |
快速的 | 媒介 | 硬 | 高增长每个完全连接层的大小背景 |
| 三层神经网络 |
快速的 | 媒介 | 硬 | 高增长每个完全连接层的大小背景 |
每个模型都是一个用于分类的前馈全连接神经网络。神经网络的第一个完全连接层有一个来自网络输入(预测数据)的连接,每一个后续层都有一个来自前一层的连接。每个完全连通的层将输入乘以一个权值矩阵,然后添加一个偏置向量。激活函数跟随每一个完全连接的层。最后的全连接层和随后的softmax激活函数产生网络的输出,即分类分数(后验概率)和预测标签。有关更多信息,请参见神经网络结构.
例如,请参见使用分类学习应用程序训练神经网络分类器.
高级神经网络选项
神经网络分类器在分类学习中的应用菲茨内特函数。你可以设置这些选项:
完全连接的层数-指定神经网络中全连接层的数量,不包括最终用于分类的全连接层。您最多可以选择三个完全连接的层。
每个完全连接层的大小-指定每个完全连接层的大小,不包括最终完全连接层。如果您选择创建具有多个完全连接层的神经网络,请考虑指定大小较小的层。
激活—指定所有全连接层的激活功能,最终全连接层除外。最后一个完全连接层的激活函数总是softmax。从以下激活功能中选择:
线性整流函数(Rectified Linear Unit),双曲正切,乙状结肠,没有一个.迭代限制—指定最大训练迭代次数。
正则化项的力量-指定岭(L2)正则化惩罚项。
标准化数据—指定是否标准化数值预测器。如果预测器有很大的不同尺度,标准化可以提高拟合。强烈建议对数据进行标准化。
相关的话题
你也可以从以下列表中选择一个网站:
