使用分类学习应用程序训练集成分类器
这个例子展示了如何在Classification Learner应用程序中构建分类器的集成。集成分类器将许多弱学习者的结果融合为一个高质量的集成预测器。质量取决于算法的选择,但是集成分类器的适应速度往往很慢,因为它们通常需要很多学习者。
在MATLAB®,加载
fisheriris数据集并定义从数据集以用于分类的一些变量。fishertable = readtable (“fisheriris.csv”);在应用程序标签,在机器学习和深度学习组中,单击分类学习者.
在分类学习者标签,在文件部分中,点击新会话>从工作区.

在“从工作区”对话框的“新会话”中,选择表
fishertable从数据集变量列表(如果有必要)。观察应用程序根据数据类型选择响应和预测变量。花瓣和萼片的长度和宽度是预测因子。物种是你想要分类的反应。对于本例,不要更改选择。点击开始课程.
分类学习者创建数据的散点图。
使用散点图来研究哪些变量对预测响应有用。在X轴和y轴控件中选择不同的变量,以可视化物种和测量值的分布。观察哪些变量能最清楚地区分物种的颜色。
创建一个选择的集合模型,在分类学习者标签,在模型类型节中,单击向下箭头以展开分类器列表,然后在合奏分类器,点击所有合奏.

在里面培训部分中,点击火车.

提示
如果您有并行计算工具箱™,您可以培训所有型号(所有合奏)同时选择使用并行按钮培训节之前点击火车.你点击后火车,打开“打开并行池”对话框,并在应用程序打开并行工人池时保持打开状态。在此期间,您无法与软件进行互动。池后,应用程序同时列出模型。
分类学习者在库中列出了每个非优化的合奏分类选项之一,并突出显示最佳分数。应用程序概述了一个框中准确性(验证)得分最佳模型。
选择一个模型模型窗格以查看结果。检查训练模型的散点图。分类错误的点用X表示。
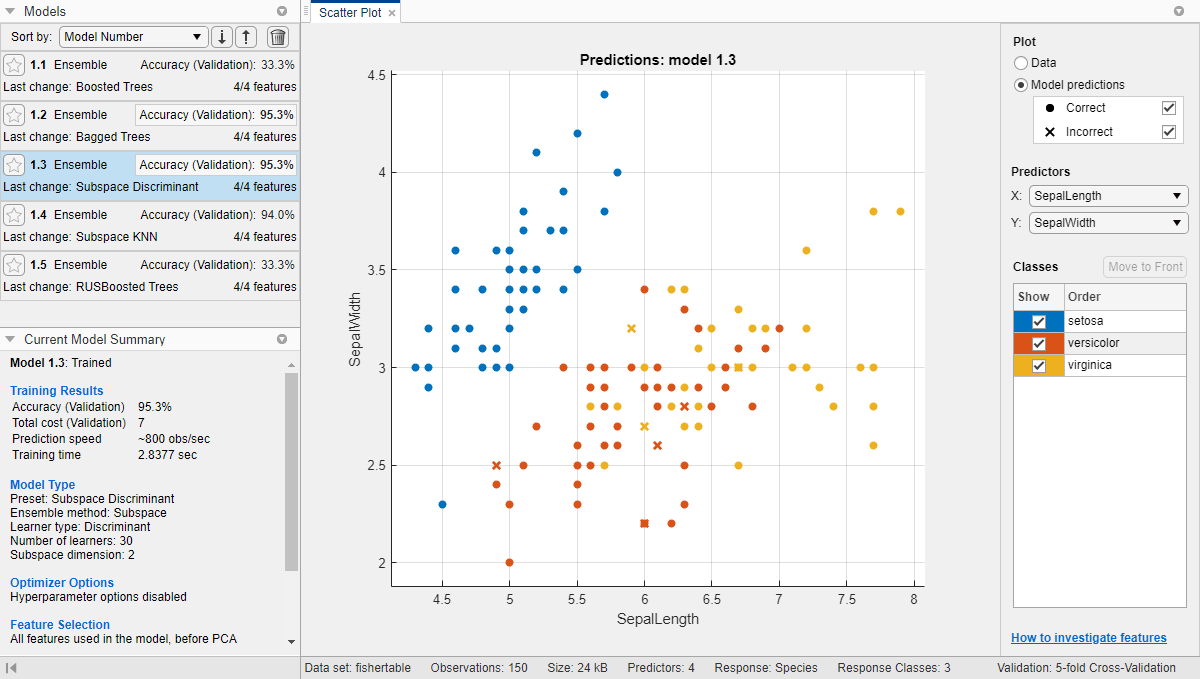
检查每个班级预测的准确性,在分类学习者标签,在情节部分中,点击混淆矩阵并选择验证数据.查看真实班级和预测班级结果的矩阵。
中选择其他模型模型窗格来比较。
选择最好的模型(最好的分数在准确性(验证)盒子)。为了改进模型,尝试在模型中包括不同的功能。看看您是否可以通过删除具有低预测电源的功能来改进模型。
在分类学习者标签,在特性部分中,点击功能选择.在Feature Selection对话框中,指定要从模型中删除的预测器,然后单击火车用新的选项训练一个新的模型。的分类器之间比较结果模型窗格。
为了研究要包含或排除的特征,使用散点和平行坐标图。在分类学习者标签,在情节部分中,选择平行坐标.
选择最佳模型模型窗格。为了进一步改进模型,请尝试更改设置。在分类学习者标签,在模型类型部分中,点击先进的.尝试更改设置,然后单击训练新模型火车.
有关要尝试的设置和不同集成模型类型的优点的信息,请参见合奏分类器.
要将训练过的模型导出到工作空间,请选择Classification Learner选项卡并单击出口模式.看导出分类模型来预测新数据.
要检查培训此分类器的代码,请单击生成函数.



使用相同的工作流来评估和比较您可以在分类学习器中训练的其他分类器类型。
尝试所有不可优化的分类器模型预置您的数据集:
单击最右边的箭头模型类型节以展开分类器列表。
点击全部,然后单击火车.

要了解其他分类器类型,请参见在分类学习者应用中列车分类模型.
相关话题
您还可以从以下列表中选择一个网站:
