评估分类器在分类学习者中的性能
在Classification Learner中训练分类器后,您可以根据准确度分数比较模型,通过绘制类预测可视化结果,并使用混淆矩阵和ROC曲线检查性能。
如果你使用K-折叠交叉验证,然后应用程序使用K验证折叠并报告平均交叉验证误差。它还对这些验证折叠中的观察值进行预测,并根据这些预测计算混淆矩阵和ROC曲线。
笔记
将数据导入应用程序时,如果接受默认设置,应用程序将自动使用交叉验证。要了解更多信息,请参阅选择验证方案.
如果使用保持验证,应用程序将使用验证折叠中的观察值计算准确度分数,并对这些观察值进行预测。应用程序还将根据这些预测计算混淆矩阵和ROC曲线。
如果使用重新替代验证,则分数是基于所有训练数据的重新替代精度,并且预测是重新替代预测。
在“模型”窗格中检查性能
在分类学习器中培训模型后,检查模型窗格以查看哪个模型的总体精度(百分比)最好。最佳准确性(验证)分数在框中突出显示。这个分数是验证的准确度。与训练数据相比,验证准确度得分估计模型在新数据上的性能。使用分数帮助您选择最佳模型。
对于交叉验证,分数是所有观察结果的准确度,当每个观察结果处于保持(验证)状态时进行计数。
对于坚持验证,分数是坚持观察的准确性。
对于重新替代验证,分数是针对所有训练数据观察的重新替代准确性。
最好的总分可能不是你目标的最佳模式。总体精度稍低的模型可能是实现目标的最佳分类器。例如,特定类中的误报可能对您很重要。您可能希望排除一些数据收集昂贵或困难的预测因素。
要了解分类器在每个类中的执行情况,请检查混淆矩阵。
查看和比较模型度量
您可以在中查看模型度量当前模型摘要窗格并使用这些度量来评估和比较模型培训结果在验证集上计算度量。这个测试结果度量(如果显示)是在导入的测试集上计算的。有关详细信息,请参阅评估测试集模型性能.
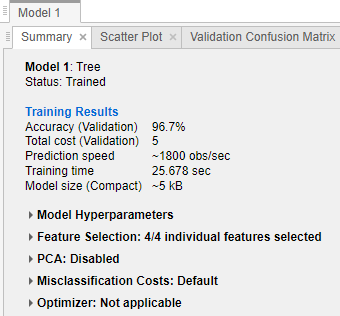
将信息复制到当前模型摘要窗格中,您可以右键单击窗格并选择复制文本.
模型度量
| 米制的 | 描述 | 提示 |
|---|---|---|
| 精确 | 正确分类的观察值百分比 | 寻找更大的精度值。 |
| 总成本 | 总误分类成本 | 寻找较小的总成本值。确保精度值仍然较大。 |
您可以根据不同的模型度量对模型进行排序。要选择模型排序的度量,请使用排序列表位于列表的顶部模型窗玻璃
您还可以删除中列出的不需要的模型模型窗玻璃选择要删除的模型,然后单击删除所选模型按钮,或右键单击模型并选择删除模型。无法删除中最后剩余的模型模型窗玻璃
绘图分类器结果
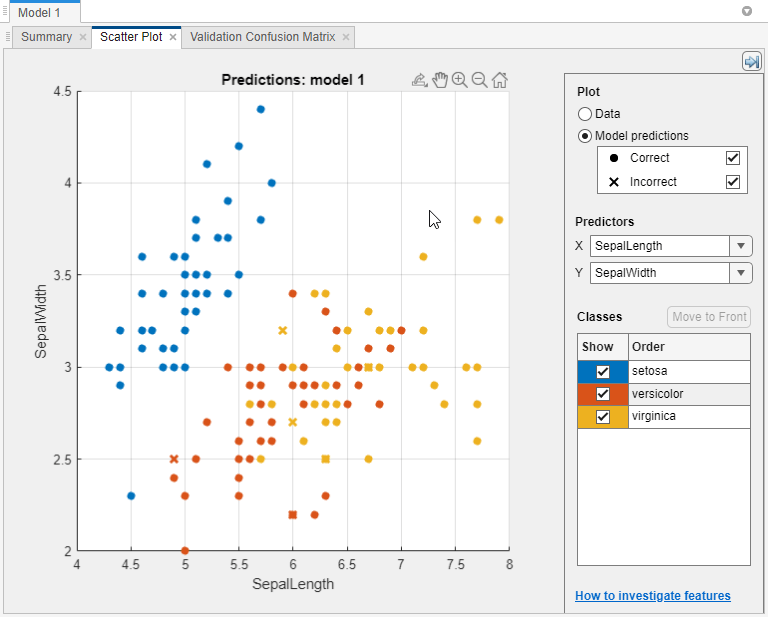
在散点图中,查看分类器结果。训练分类器后,散点图从显示数据切换到显示模型预测。如果使用保持或交叉验证,则这些预测是保持(验证)上的预测观察。换句话说,每个预测都是使用未使用相应观察的训练模型获得的。要调查结果,请使用右侧的控件。您可以:
选择是绘制模型预测还是单独绘制数据。
使用下面的复选框显示或隐藏正确或不正确的结果模型预测.
选择要使用X和Y下的列表预测因子.
通过使用下面的复选框显示或隐藏特定类,按类可视化结果显示.
通过在下选择一个类来更改打印类的堆叠顺序班级然后点击到前面去.
放大和缩小或平移绘图。要启用缩放或平移,请将鼠标悬停在散点图上,然后单击显示在该图右上方的工具栏上的相应按钮。
另见调查散点图中的特征.
要将应用程序中创建的散点图导出为地物,请参见在分类学习器应用程序中导出绘图.
在混淆矩阵中检查每个类的性能
使用混淆矩阵图了解当前选定分类器在每个类中的执行情况。要在训练模型后查看混淆矩阵,请单击混淆矩阵选择验证数据在阴谋部分分类学习者标签。混淆矩阵有助于识别分类器性能不佳的区域。
打开绘图时,行显示真实类,列显示预测类。如果使用保留或交叉验证,则使用保留(验证)观察的预测计算混淆矩阵。对角线单元格显示真实类和预测类的匹配位置。如果这些对角单元格为蓝色,则分类器已分类,且该真实类别的观察值已正确分类。
默认视图显示每个单元格中的观察数。
要查看每个类的分类器执行情况,请参见情节,选择真阳性率(TPR),假阴性率(FNR)选项TPR是每个真实类别正确分类的观察值的比例。FNR是每个真实类别的错误分类观察值的比例。该图显示了右侧最后两列中每个真实类的摘要。
提示
通过检查显示高百分比且为橙色的对角单元格,查找分类器性能不佳的区域。百分比越高,单元格颜色的色调越深。在这些橙色单元格中,真实类和预测类不匹配。数据点被错误分类。

在本例中,使用卡斯莫尔数据集,从顶部开始的第二行显示了所有真正的德国级汽车。这些列显示预测的类。22.2%的德国车分类正确,因此22.2%是该类别中正确分类点的真实阳性率,如图中蓝色单元格所示TPR柱
德国行中的其他汽车被错误分类:55.6%的汽车被错误分类为来自日本,22.2%被分类为来自美国。该类别中错误分类分数的假阴性率为77.8%,显示在中的橙色单元格中FNR柱
如果要查看观察值的数量(本例中为汽车),而不是百分比,请在情节选择观察次数.
如果误报在分类问题中很重要,请按预测类(而不是真实类)绘制结果,以调查误报发现率。要查看每个预测类的结果,请在情节,选择阳性预测值(PPV),错误发现率(FDR)选项PPV是每个预测类别的正确分类观测值的比例。FDR是每个预测类别的错误分类观测值的比例。选择此选项后,混淆矩阵现在包括表下的摘要行。对于每个类别中正确预测的点,阳性预测值以蓝色显示,对于每个类别中错误预测的点,错误发现率以橙色显示。
如果确定感兴趣的类中存在太多错误分类点,请尝试更改分类器设置或特征选择以搜索更好的模型。
要将应用程序中创建的混淆矩阵图导出为数字,请参见在分类学习器应用程序中导出绘图.
检查ROC曲线
要在训练模型后查看ROC曲线,请在分类学习者选项卡,在阴谋部分,单击ROC曲线选择验证数据。查看显示真阳性率和假阳性率的接收器工作特性(ROC)曲线。ROC曲线显示当前所选训练分类器的真阳性率与假阳性率。您可以选择不同的类别进行绘制。
绘图上的标记显示当前选定分类器的性能。该标记显示当前选定分类器的假阳性率(FPR)和真阳性率(TPR)值。例如,假阳性率(FPR)0.2表示当前分类器将20%的观察值错误地分配给正类。0.9表示当前分类器将90%的观察值正确分配给正类。
没有错误分类点的完美结果是与绘图左上角成直角。一条45度的直线是一个不好的结果,它并不比“随机”好多少。这个曲线下面积数字是分类器整体质量的度量。更大曲线下面积值表示更好的分类器性能。比较课程和经过训练的模型,看看它们在ROC曲线中的表现是否不同。
有关详细信息,请参阅性能曲线.
要将应用程序中创建的ROC曲线图导出为地物,请参见在分类学习器应用程序中导出绘图.
评估测试集模型性能
在Classification Learner中培训模型后,您可以在应用程序中的测试集上评估模型性能。此过程允许您检查验证准确性是否为新数据上的模型性能提供了良好的估计。
将测试数据集导入分类学习器。
如果测试数据集在MATLAB中®工作区,然后在测试关于分类学习者选项卡,单击测试数据选择从工作空间.
如果测试数据集位于文件中,则在测试部分,单击测试数据选择从文件. 在列表中选择文件类型,例如电子表格、文本文件或逗号分隔值(
.csv)文件,或选择所有文件浏览其他文件类型,如.dat.
在“导入测试数据”对话框中,从中选择测试数据集测试数据集变量列表测试集必须具有与为培训和验证导入的预测值相同的变量。测试响应变量中的唯一值必须是完整响应变量中类的子集。
计算测试集度量。
要计算单个模型的测试度量,请在模型窗玻璃上分类学习者选项卡,在测试部分,单击全部测试选择选定的测试.
要计算所有经过培训的模型的测试指标,请单击全部测试选择全部测试在测试部分
该应用程序计算在完整数据集上训练的每个模型的测试集性能,包括训练和验证数据。
将验证精度与测试精度进行比较。
在当前模型摘要窗格中,应用程序将在下显示验证度量和测试度量培训结果章节及测试结果分别为第节。您可以检查验证精度是否能很好地估计测试精度。
您还可以使用绘图可视化测试结果。
显示混淆矩阵。在阴谋关于分类学习者选项卡,单击混淆矩阵选择测试数据.
显示ROC曲线。在阴谋部分,单击ROC曲线选择测试数据.
有关示例,请参见使用分类学习器应用程序中的测试集检查分类器性能。有关在超参数优化工作流中使用测试集度量的示例,请参阅在分类学习器应用程序中使用超参数优化训练分类器.
相关话题
您还可以从以下列表中选择网站:
