剪裁
平均值,不包括异常值
描述
例子
修剪效率平均值
找到给定数据集的样本意味着10%修剪的相对效率。
从标准正态分布生成100×100的随机数矩阵。该矩阵表示100个样本,每个样本包含100个数据点。
rng默认;重复性的%x = normrnd(0,1,100,100);
计算数据矩阵的每列的样本均值和10%修剪平均值。
m =均值(x);%样本平均数修剪=修剪平均值(X,10);%修剪平均数
计算样本平均值的修剪均值的相对效率。相对效率是样本平均值除以修剪平均值的方差的样本均值的方差。
VM = var(m)%样本均值方差
VM = 0.0094.
vtrim=var(微调)%修剪均值方差
vtrim = 0.0097.
效率= VM / VTRIM%修剪平均值与样本平均值的相对效率
效率= 0.9663.
样本平均值的方差小于修剪平均值(效率<1).因此,The trimmed mean is less efficient than the sample mean.
使用异常值进行控制修剪
在以下情况下控制具有异常值的分布的修剪:K(修剪的异常值的数量)不是整数。
根据学生的答案生成一个随机数向量T分布具有等于1.学生的自由度T分布往往有异常值。
rng默认;重复性的%nu=1;%自由度n=60;%行数m = 1;% 列数x=trnd(nu,n,m);%载体
使用正态概率图可视化分布。
probplot(x)
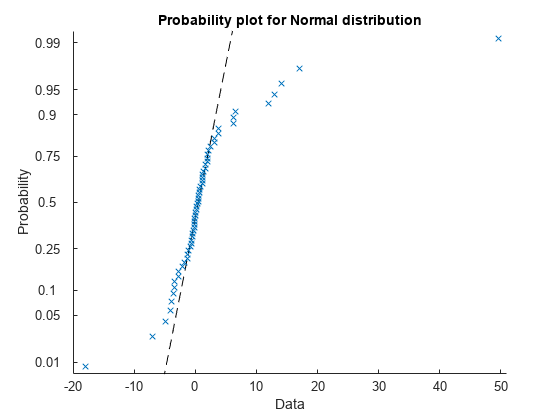
虽然分布对称零点,但是几个异常值会影响平均值。
找到数据的平均值。
mn=平均值(x)
Mn = 1.6452.
找到数据的33%修剪平均值。
修剪=剪裁(x,33)
修剪= 0.4940.
33%的修剪平均值更接近于零,这更能代表数据。对于33%的修剪平均值,K不是整数(k = 60 *(33/100)/ 2赋予价值9.9).因此,剪裁轮K到最接近的整数(10.)默认情况下。
通过四舍五入控制修剪K下一个较小的整数(9)。指定用于修剪的控件“地板”.
修剪=修剪(x,33,“地板”)
修剪= 0.4933.
沿着给定维度找到修剪的平均值
找到沿矩阵的不同尺寸的修剪平均值。
生成从学生的随机数的矩阵T分配。学生们T分布往往有异常值。
rng(“默认”)nu=1;%自由度n=2;%行数m=100;% 列数x = trnd(nu,n,m);
可视化每行数据的分布X使用正态概率图。
对于i = 1:n图()probplot(x(i,:))结束
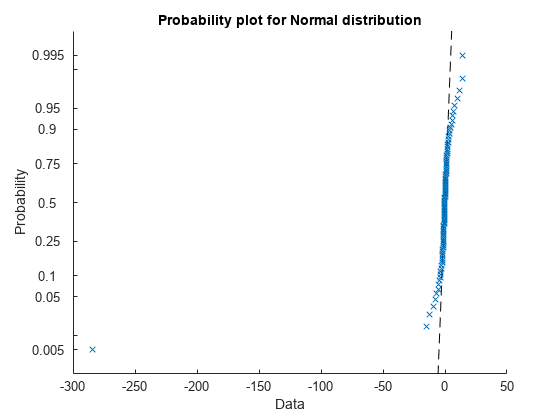
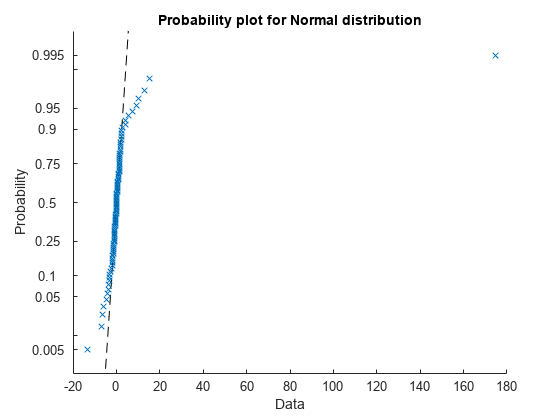
找到每行的平均值X.
mn=平均值(X,2)
锰=2×1-2.7379 2.0087
找到每排的30%修剪均值X. 具体说明昏暗= 2作为操作尺寸。
修剪=修剪平均值(X,30,2)
修剪=2×1-0.0868 0.1115
每行的30%修剪均值更接近零,这是数据的更像是数据。
沿维向量的修剪平均值
通过使用通过使用多维的修剪均值“全部”和vecdim输入参数。
使用一些异常值创建一个5×4-of-2阵列。
X=重塑(1:40,[5 4 2]);X([3 37])=-100
X=X(:,:,1)=1 6 11 16 2 7 12 17-100 8 13 18 4 9 14 19 5 10 15 20 X(:,:,2)=21 26 31 36 22 27 32-100 23 28 33 38 24 29 34 25 35 40
找到10%的修剪平均值X.
Mall = Trimmean(x,10,“全部”)
购物中心=19.4722
购物中心中90%数值的平均值X.
找到每页的10%修剪平均值X.
mpage=平均值(X,10,[12])
MPAGE = MPAGE(:,:,1)= 10.3889 MPAGE(:,:,2)= 29.6111
例如MPAGE(1,1,2)中90%数值的平均值x(:,:,2).
输入参数
X—输入数据
向量|矩阵|多维数组
输入数据,表示来自群体的样本,指定为矢量,矩阵或多维数组。
如果
X那么,这是一个向量Trimmean(x,百分比)是的所有值的平均值X,在删除异常值后计算。如果
X那么,这是一个矩阵Trimmean(x,百分比)是列平均值的行向量,在删除异常值后计算。如果
X是一个多维数组,那么剪裁沿着第一个不连贯的尺寸操作X.
指定操作维度X是矩阵或数组,使用昏暗的输入参数。
剪裁对待楠价值X缺少值并删除它们。
数据类型:单身的|双倍的
百分比—百分比
标量子
要修剪的输入数据的百分比,指定为介于0和100..
剪裁使用价值百分比确定异常值的数量(最高和最低K价值X)免除X在计算平均值之前。对于X具有N价值观,k=n*(百分比/100)/2.
数据类型:单身的|双倍的
旗帜—修剪控制
“圆形”(默认)|“地板”|'加权'
控制何时修剪K(异常值数量的一半)不是整数,指定为此表中的值之一。
| 价值 | 描述 |
|---|---|
“圆形” |
圆形的K到最近的整数(舍入到一个较小的整数)K是半整数)。此值是默认值。 |
“地板” |
圆形的K下一个较小的整数。 |
'加权' |
如果k=i+f, 在哪里我是一个整数和F是一小部分,计算重量的加权平均值(1 - F)对于(i + 1)th和(n–i)第值,以及它们之间的值的全重量。 |
数据类型:char|细绳
昏暗的—尺寸
正整数标量
沿其操作的维度,指定为正整数标量。如果未指定值,则默认值为的第一个数组维度X其大小不等于1。
考虑二维数组X:
如果
昏暗的等于1,然后Trimmean(x,百分比,1)返回包含每个列的修剪均值的行向量X.如果
昏暗的等于2,那么Trimmean(x,百分比,2)返回一个列向量,其中包含中每行的修剪平均值X.
如果昏暗的大于ndims(x)或者如果尺寸(x,dim)是1,然后剪裁返回X.
数据类型:单身的|双倍的
输出参数
提示
修剪平均值是对数据样本位置的稳健估计。如果数据包含异常值,则修剪平均值比样本平均值更能代表数据的中心。但是,如果所有数据都来自相同的概率分布,则修剪平均值作为数据loca的估计值的效率低于样本平均值激动。
扩展能力
您还可以从以下列表中选择网站:
