tsne设置
此示例显示了各种tsne设置。
获得数据
首先从中获取MNIST[1]图像和标签数据
http://yann.lecun.com/exdb/mnist/
解压文件。对于本例,请使用t10k-images数据。
图像文件名=“t10k-images.idx3-ubyte”;labelFileName =“t10k-labels.idx1-ubyte”;
处理文件以将其加载到工作区中。此处理函数的代码显示在本示例的末尾。
[X, L] = processMNISTdata (imageFileName labelFileName);
正在读取MNIST图像数据。。。数据集中的图像数:10000。。。每个图像是28乘28像素。。。图像数据被读取到一个尺寸矩阵:10000×784。。。读取图像数据的结束。正在读取MNIST标签数据。。。数据集中的标签数:10000。。。标签数据被读取到尺寸矩阵:10000 x 1。。。读取标签数据的结束。
使用t-SNE处理数据
使用t-SNE获得数据簇的二维模拟。使用Barnes-Hut算法在这个大型数据集上获得更好的性能。使用PCA将初始维度从784降到50。
rng默认的%的再现性Y=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”, 50);图gscatter (Y (: 1), Y (:, 2), L)标题(“默认数字”)
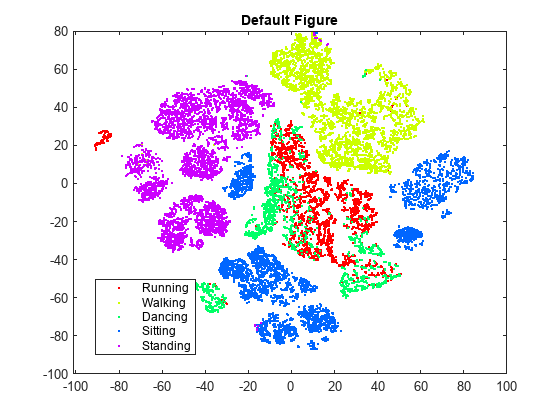
t-SNE创建了一个具有分离良好的集群和相对较少的似乎错位的数据点的数字。
困惑
尝试改变困惑设置,以查看在图上的效果。
rng默认的为了公平比较Y100=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“困惑”, 100);图gscatter(日圆(:1),(2):,日圆,L)标题(“100年困惑”)rng默认的为了公平比较Y4=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“困惑”4);图gscatter (Y4 (: 1), Y4 (:, 2), L)标题(“困惑4”)


将perplexity设置为100将得到一个与默认值非常相似的数字。集群比默认设置更紧。然而,将perplexity设置为4会给出一个没有很好地分离集群的图。与默认设置相比,集群更松散。
夸张
试着改变夸张设置,看看效果在数字上。
rng默认的为了公平比较YEX0 = tsne (X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“夸张”,20); 图gscatter(YEX0(:,1),YEX0(:,2),L)标题(“夸张20”)rng默认的为了公平比较YEx15=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“夸张”, 1.5);图gscatter (YEx15 (: 1), YEx15 (:, 2), L)标题(“夸张1.5”)

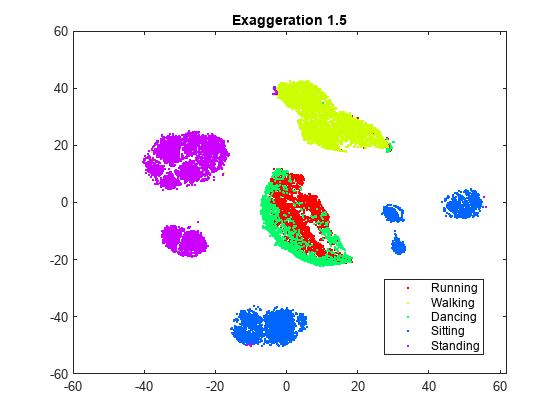
虽然夸张设置对数字有影响,但不清楚任何非默认设置是否比默认设置提供更好的图像。夸张了20的数字与默认的数字相似。一般来说,放大会在嵌入式集群之间产生更多的空白空间。如果将1.5夸大,则标记为1和6的两组会各自分成两组,这是一个不理想的结果。X的联合分布的值被夸大使得Y的联合分布的值变小。这使得嵌入的点彼此相对移动更加容易。集群1和集群6的分裂反映了这一效应。
学习速率
尝试改变学习速率设置,看看对图的影响。
rng默认的为了公平比较YL5=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“LearnRate”,5); 图gscatter(YL5(:,1),YL5(:,2),L)标题(“学习率5”)rng默认的为了公平比较YL2000=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“LearnRate”图gscatter(YL2000(:,1),YL2000(:,2),L)标题(‘2000年学习率’)


学习率为5的图形有几个簇,这些簇分成两个或多个部分。这表明,如果学习率太小,最小化过程可能会陷入一个糟糕的局部最小值。学习率为2000的图形与默认图形类似。
不同设置下的初始行为
大的学习速率或大的夸大值会导致不良的初始行为。要查看这一点,设置这些参数的大值并设置NumPrint和冗长的到1显示所有迭代。在10之后停止迭代,因为本实验的目标只是查看初始行为。
首先将夸张程度设定为200。
rng默认的为了公平比较选择= statset (“MaxIter”,10);YEX200=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“夸张”, 200,...“NumPrint”1.“冗长”1.“选项”,opts);
|==============================================| | ITER | | KL分歧规范研究生使用| | |娱乐价值使用|夸大DIST | | | X的夸张DIST | | | | (X) | | |==============================================| | 1 e + 03 | 2.190347 | 6.078667 e-05 | | 2 | 2.190352 e + e 03 03 | 4.769050 | | 3 | 2.204061 e + 03 e-02 | 9.423678 | | 4 | 2.464585 e + 03| 2.113271e-02 | | 5 | 2.501222e+03 | 2.616407e-02 | | 6 | 2.529362e+03 | 3.022570e-02 | | 7 | 2.553233e+03 | 3.108418e-02 | | 8 | 2.562822e+03 | 3.27887e -02 | | 9 | 2.538056e+03 | 3.222265e-02 | | 10 | 2.504932e+03 | 3.671708e-02 |
Kullback-Leibler散度在最初的几次迭代中增加,梯度的范数也增加。
要查看嵌入的最终结果,请使用默认停止条件让算法运行到完成。
rng默认的为了公平比较YEX200 = tsne (X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“夸张”, 200);图gscatter (YEX200 (: 1), YEX200 (:, 2), L)标题(“夸张200”)
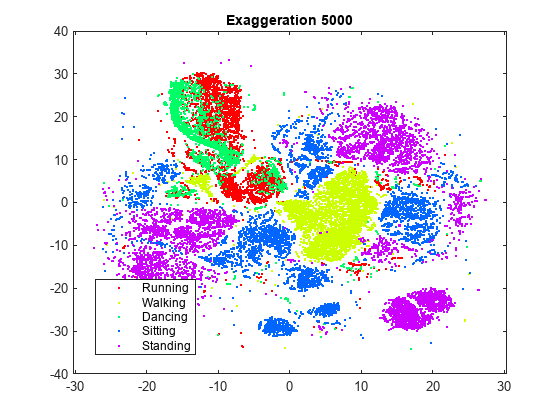
这个夸大的值并没有清晰地划分到集群中。
显示学习率为100000时的初始行为。
rng默认的为了公平比较YL100k=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“LearnRate”1 e5,...“NumPrint”1.“冗长”1.“选项”,opts);
|==============================================| | ITER | | KL分歧规范研究生使用| | |娱乐价值使用|夸大DIST | | | X的夸张DIST | | | | (X) | | |==============================================| | 1 e + 01 | 2.815885 | 1.024049 e-06 | | 2 | 2.816002 e + 01 | 2.902059 e-04 | | 3 | 3.195873 e + 01 | 7.355889 e-04 | | 4 | 3.348151 e + 01| 3.958901e-04 | | 5 | 3.365935e+01 | 2.876905e-04 | 6 | 3.342462e+01 | 3.906245e-04 | | 7 | 3.303205e+01 | 4.037983e-04 | | 8 | 3.263320e+01 | 5.665630e-04 | | 9 | 3.235384e+01 | 4.319099e-04 | | 10 | 3.211238e+01 | 4.803526e-04 |
同样,Kullback-Leibler散度在前几个迭代期间增加,梯度的范数也增加。
要查看嵌入的最终结果,请使用默认停止条件让算法运行到完成。
rng默认的为了公平比较YL100k=tsne(X,“算法”,“巴尼舒特”,“NumPCAComponents”,50,“LearnRate”1 e5);图gscatter (YL100k (: 1), YL100k (:, 2), L)标题(“学习率100000”)

学习率太大了,没有给出有用的嵌入。
结论
tsne使用默认设置可以很好地将高维初始数据嵌入到定义良好的聚类的二维点中。算法设置的效果很难预测。有时它们可以改善聚类,但大多数情况下默认设置看起来不错。虽然速度不是本次调查的一部分,设置可能会影响算法的速度。特别是,Barnes-Hut算法对该数据的处理速度明显更快。
处理MNIST数据的代码
下面是将数据读入工作区的函数的代码。
功能[X,L] = processMNISTdata(imageFileName,labelFileName) [fileID,errmsg] = fopen(imageFileName, labelFileName)“r”,“b”);如果fileID < 0错误(errmsg);结束%%先读这个神奇的数字。对于图像数据,这个数字是2051% 2049用于标签数据magicNum =从文件中读(文件标识,1“int32”,0,“b”);如果magicNum == 2051 fprintf('\nRead mist图像数据…\n')结束%%%然后读取图像数量、行数、列数numImages=fread(fileID,1,“int32”,0,“b”); fprintf('数据集中的图像数量:%6d…\n',numImages);numRows=fread(文件ID,1,“int32”,0,“b”);numCols=fread(文件ID,1,“int32”,0,“b”); fprintf('每个图像的像素数为%2d乘以%2d…\n'numRows numCols);%%%读取镜像数据X=fread(文件ID,inf,“无符号字符”);%%%将数据重塑为数组XX =重塑(X, numCols numRows numImages);X = permute(X,[2 1 3]);%%%然后将每个图像数据扁平化为1 × (numRows*numCols)向量,然后%将所有图像数据存储到numImages by(numRows*numCols)数组中。X=重塑(X,numRows*numCols,numImages);fprintf(['图像数据被%4d读取到维度矩阵:%6d…\n',...'读取图像数据结束。\n'],大小(X,1),大小(X,2));%%%关闭文件文件关闭(文件标识);%%%同样,读取标签数据。[文件标识,errmsg] = fopen (labelFileName,“r”,“b”);如果fileID < 0错误(errmsg);结束magicNum =从文件中读(文件标识,1“int32”,0,“b”);如果magicNum == 2049 fprintf('\nRead nist label data…\n')结束numItems =从文件中读(文件标识,1“int32”,0,“b”); fprintf('数据集中的标签数量:%6d…\n',numItems);L=fread(fileID,inf,“无符号字符”); fprintf(['标签数据由%2d读取到维度矩阵:%6d…\n',...'读取标签数据的结束。\n']大小(1,1),大小(1,2));fclose(fileID);
参考文献
Yann LeCun (Courant Institute, NYU)和Corinna Cortes(谷歌Labs, New York)拥有MNIST数据集的版权,该数据集是NIST原始数据集的衍生作品。MNIST数据集是在知识共享署名-共享相似3.0许可条款下提供的,https://creativecommons.org/licenses/by-sa/3.0/
相关的例子
更多关于
外部网站
您还可以从以下列表中选择网站:
