导入预训练的ONNX YOLO v2对象检测器
这个例子展示了如何导入一个预先训练的ONNX™(开放神经网络交换),你只看一次(YOLO) v2[1]物体检测网络,并利用它来检测物体。导入网络后,您可以使用GPU编码器™将其部署到嵌入式平台,或使用迁移学习对自定义数据进行再培训trainYOLOv2ObjectDetector.
下载ONNX YOLO v2 Network
下载与预培训的Tiny YOLO v2网络相关的文件[2],[3].
pretrainedURL =“https://onnxzoo.blob.core.windows.net/models/opset_8/tiny_yolov2/tiny_yolov2.tar.gz”;pretrainedNetZip =“yolov2Tmp.tar.gz”;如果~存在(pretrainedNetZip“文件”) disp ('下载预训练网络(58mb)…');websave (pretrainedNetZip pretrainedURL);结束
下载预训练网络(58mb)…
提取YOLO v2网络
解压缩并解压下载的文件,以解压Tiny YOLO v2网络。加载“model.onnx”模型,是在PASCAL VOC数据集上预训练的ONNX YOLO v2网络。该网络可以检测20个不同类别的目标[4].
pretrainedNetTar = gunzip (pretrainedNetZip);onnxfiles =压缩(pretrainedNetTar {1});pretrainedNet = onnxfiles {1,2};
导入ONNX YOLO v2图层
使用importONNXLayers命令功能,导入下载的网络。
lgraph = importONNXLayers (pretrainedNet,“ImportWeights”,真正的);
警告:导入的层没有输出层,因为ONNX文件没有指定网络的输出层类型。在添加输出层之前,这些层是不可训练的。要么向导入的层添加一个输出层,要么在importONNXLayers调用中使用'OutputLayerType'指定输出层类型。
在本例中,您向导入的层添加了一个输出层,因此可以忽略此警告。的添加YOLO v2变换和输出层小节展示了如何将YOLO v2输出层以及YOLO v2 Transform层添加到导入层。
本例中的网络不包含不受支持的层。金宝app注意,如果要导入的网络不支持层,该函数将它们作为占位符层导入。金宝app在使用导入的网络之前,必须替换这些层。有关替换占位符层的更多信息,请参见findPlaceholderLayers(深度学习工具箱).
定义YOLO v2锚盒
YOLO v2使用预定义的锚盒来预测对象位置。导入网络中使用的锚盒在Tiny YOLO v2网络配置文件中定义[5].ONNX锚是根据最终卷积层的输出大小定义的,最终卷积层是13乘13。使用锚yolov2ObjectDetector,将锚盒的大小调整为网络输入的大小,即416 × 416。锚箱yolov2ObjectDetector必须在[高,宽]中指定。
onnxAnchors = [1.08, 1.19;3.42、4.41;6.63、11.38;9.42、5.11;16.62、10.52);inputSize = lgraph.Layers (1,1) .InputSize (1:2);lastActivationSize =(13、13);upScaleFactor = inputSize. / lastActivationSize;anchorBoxesTmp =圆(upScaleFactor。* onnxAnchors);anchorBoxes = [anchorBoxesTmp (:, 2), anchorBoxesTmp (: 1)];
重新排序检测层权重
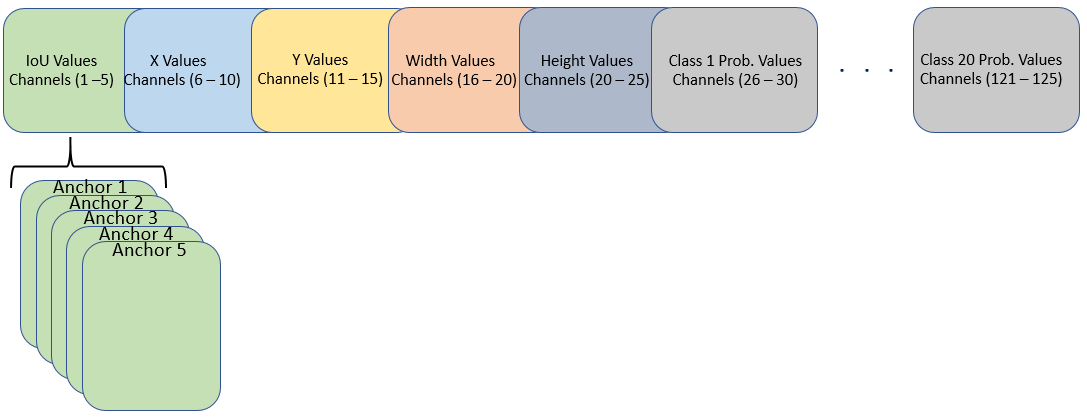
为了有效的处理,您必须重新排序导入网络中最后一个卷积层的权值和偏差,以获得以下安排中的激活yolov2ObjectDetector需要。yolov2ObjectDetector预计最后一层卷积的feature map的125个通道,排列如下:
频道1到5 -五个主播的IoU值
频道6至10 - X值为五个锚
频道11至15 - 5个锚点的Y值
通道16到20 -五个锚的宽度值
频道21至25 -五个锚的高度值
频道26至30 - 5个主播的1级概率值
频道31到35 - 5个锚的第2类概率值
121至125频道- 5个锚的20级概率值
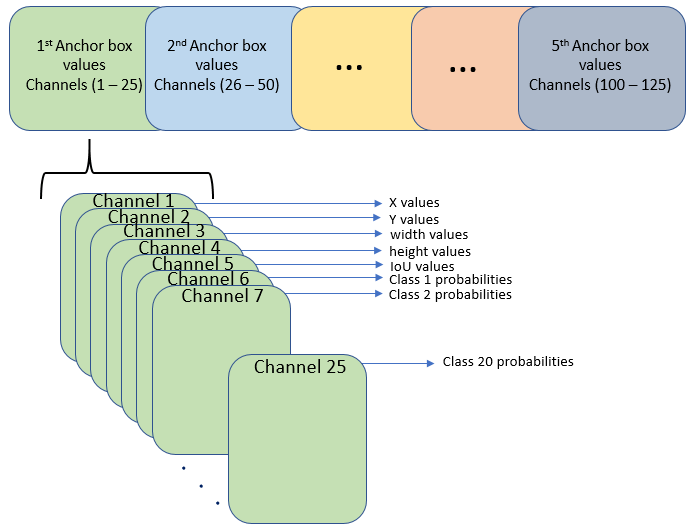
然而,在最后一层的大小为13 × 13的卷积层中,激活的排列不同。feature map中的25个通道分别对应于:
通道1 - X值
通道2 - Y值
通道3 -宽度值
频道4 -高度值
通道5 - IoU值
通道6 -第一类概率值
通道7 -第2类概率值
信道25 - 20类概率值
使用支持函数金宝apprearrangeONNXWeights,以重新排序导入网络中最后一个卷积层的权值和偏差,并获得所需格式的激活yolov2ObjectDetector.
重量= lgraph.Layers(结束,1).Weights;偏见= lgraph.Layers(结束,1).Bias;layerName = lgraph.Layers(结束,1). name;numAnchorBoxes =大小(onnxAnchors, 1);[modWeights, modBias] = rearrangeONNXWeights(重量、偏见、numAnchorBoxes);
将引入的网络中最后一层卷积层的权值和偏差替换为使用重排序权值和偏差的新卷积层。
filterSize = size(modWeights,[1 2]);numFilters =大小(modWeights 4);modConvolution8 = convolution2dLayer (filterSize numFilters,...“名字”layerName,“偏见”modBias,“重量”, modWeights);lgraph = replaceLayer (lgraph,“convolution8”, modConvolution8);
添加YOLO v2变换和输出层
YOLO v2检测网络需要YOLO v2变换层和YOLO v2输出层。创建这两个层,将它们串联起来,并将YOLO v2转换层附加到最后一个卷积层。
一会= tinyYOLOv2Classes;layersToAdd = [yolov2TransformLayer(numAnchorBoxes,“名字”,“yolov2Transform”);yolov2OutputLayer (anchorBoxes“类”一会,“名字”,“yolov2Output”);];lgraph = addLayers(lgraph, layersToAdd);lgraph = connectLayers (lgraph layerName,“yolov2Transform”);
的ElementwiseAffineLayer在导入的网络中复制所执行的预处理步骤yolov2ObjectDetector.因此,删除ElementwiseAffineLayer从导入的网络。
yoloScaleLayerIdx =找到(...arrayfun (@ (x) isa (x,“nnet.onnx.layer.ElementwiseAffineLayer”),...lgraph.Layers));如果~ isempty (yoloScaleLayerIdx)为i = 1:size(yoloScaleLayerIdx,1) layerNames {i} = lgraph.Layers(yoloScaleLayerIdx(1),1).Name;结束lgraph = removeLayers (lgraph layerNames);lgraph = connectLayers (lgraph,“Input_image”,“卷积”);结束
创建YOLO v2对象检测器
控件组装层图assembleNetwork函数创建YOLO v2对象检测器yolov2ObjectDetector函数。
净= assembleNetwork (lgraph)
net = DAGNetwork with properties: Layers: [34×1 net.cnn.layer. layer] Connections: [33×2 table] InputNames: {'Input_image'} OutputNames: {'yolov2Output'}
yolov2Detector = yolov2ObjectDetector(净)
yolov2Detector = yolov2ObjectDetector with properties: ModelName: 'importedNetwork' Network: [1×1 DAGNetwork] TrainingImageSize: [416 416] AnchorBoxes: [5×2 double] ClassNames:[飞机自行车鸟船瓶子巴士汽车猫椅子牛餐台狗马摩托车人盆栽植物羊沙发火车电视监视器]
使用导入的YOLO v2探测器检测对象
使用导入的检测器检测测试图像中的对象。显示结果。
我= imread (“car1.jpg”);%将图像转换为BGR格式。我=猫(3,我(:,:,3),我(:,:2),我(:,:1));[bboxes, scores, labels] =检测(yolov2Detector, I);detectedImg = insertObjectAnnotation(我“矩形”bboxes,分数);图imshow (detectedImg);

金宝app支持功能
函数[modWeights, modBias] = rearrangeONNXWeights(重量、偏见、numAnchorBoxes)rearrangeONNXWeights重新排列导入YOLO的权重和偏差%v2网络,由yolov2ObjectDetector要求。numAnchorBoxes是一个标量%值,该值包含用于重新排序权重和的锚的数量%的偏见。执行以下功能:% *提取与IoU、框和类相关的权重和偏差。% *按照yolov2ObjectDetector的预期对提取的权重和偏差重新排序。% *将它们组合并重塑为原始维度。weightsSize =大小(重量);biasSize =大小(偏差);sizeOfPredictions = biasSize (3) / numAnchorBoxes;%根据预测和锚的大小重塑权重。reshapedWeights =重塑(重量、刺激(weightsSize (1:3)), sizeOfPredictions, numAnchorBoxes);%提取与IoU、boxes、classes相关的权重。weightsIou = reshapedWeights (: 5:);1:4, weightsBoxes = reshapedWeights (::);weightsClasses = reshapedWeights(::, 6:结束);%按要求组合提取参数的权重% yolov2ObjectDetector。reorderedWeights =猫(2 weightsIou weightsBoxes weightsClasses);permutedWeights = permute(reorderedWeights,[1 3 2]);%将新权重重塑为原来的大小。modWeights =重塑(permutedWeights weightsSize);重塑与预测和锚的大小有关的偏差。reshapedBias =重塑(偏见,sizeOfPredictions numAnchorBoxes);%提取与IoU、盒子和类别相关的偏差。: biasIou = reshapedBias(5日);: biasBoxes = reshapedBias (1:4);biasClasses = reshapedBias(6:最后,);%按照yolov2ObjectDetector的要求,结合提取参数的偏差。reorderedBias =猫(1 biasIou biasBoxes biasClasses);permutedBias = permute(reorderedBias,[2 1]);将新的偏差重塑到原来的大小。modBias =重塑(permutedBias biasSize);结束函数类= tinyYOLOv2Classes ()返回与预训练的ONNX微小YOLO v2对应的类名%网络。%%在Pascal VOC数据集上预训练微小的YOLO v2网络,%包含来自20个不同类的图像。类= [...“飞机”,“自行车”,“鸟”,“船”,“瓶子”,“公共汽车”,“汽车”,...“猫”,“椅子”,“牛”,“diningtable”,“狗”,“马”,“摩托车”,...“人”,“pottedplant”,“羊”,“沙发”,“训练”,“tvmonitor”];结束
参考文献
雷蒙德,约瑟夫和阿里·法哈迪。“YOLO9000:更好、更快、更强。”2017 IEEE计算机视觉与模式识别会议(CVPR), 6517-25。火奴鲁鲁,HI: IEEE, 2017。https://doi.org/10.1109/CVPR.2017.690。
[2]“微型YOLO v2模型”。https://github.com/onnx/models/tree/master/vision/object_detection_segmentation/tiny-yolov2
[3]“微小的YOLO v2模型许可。”https://github.com/onnx/onnx/blob/master/LICENSE.
Everingham, Mark, Luc Van Gool, Christopher K. I. Williams, John Winn和Andrew Zisserman。“Pascal视觉对象类(VOC)挑战”。计算机工程与应用,2018,(5):514 - 514。2(2010年6月):303-38。https://doi.org/10.1007/s11263 - 009 - 0275 - 4。
[5]“yolov2-tiny-voc.cfg”https://github.com/pjreddie/darknet/blob/master/cfg/yolov2-tiny-voc.cfg.
你也可以从以下列表中选择一个网站:
