- 正态(或高斯)分布
- 威布尔分布
- 广义极值(GEV)分布
- 物流配送
- 内核分配
- 连系动词(多元分布)
非参数分布是纯粹基于样本数据提供概率密度函数估计的概率分布。当数据不能被参数分布精确描述时,这是首选。一些常见的非参数概率分布包括:
- 内核分配
- 经验累积分布
- 分段线性分布
- 带有帕累托尾的分段分布
- 三角形分布
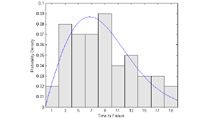
利用极大似然估计,参数分布可以很容易地拟合数据。然后,通过计算汇总统计数据、评估概率密度函数(PDF)和累积分布函数(CDF)以及评估分布对数据的拟合,可以使用拟合分布执行进一步的分析。
有关分布类型、分布拟合、分布可视化和生成随机数的更多信息,请参见统计和机器学习工具箱™使用MATLAB®.