基因表达谱分析
这个例子展示了许多在基因表达谱中寻找模式的方法。
探索数据集
该示例使用来自Derisi等人的酵母中基因表达的微阵列表达的数据。1997 [1]。作者使用DNA微阵列研究几乎所有基因的时间基因表达酿酒酵母在代谢从发酵到呼吸的转变期间。在辅助偏移期间在七个时间点测量表达水平。可以从基因表达式omnibus网站下载完整数据集,https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE28.
的MAT-fileyeastdata.mat包含表达式值(log2的ratioch2dn_mean.和CH1DN_MEAN),从实验的七个时间步骤,基因的名称,和一组表达水平测量的时间。
负载yeastdata.mat
来了解你可以使用的数据的大小元素个数(基因)为了显示数据集中包含多少个基因。
元素个数(基因)
ans = 6400
你可以通过索引变量来访问与实验相关的基因名称基因,一个代表基因名称的细胞阵列。例如,第15个元素基因是yal054c。这表示变量的第15行yeastvalues包含YAL054C的表达水平。
基因{15}
ans ='yal054c'
可以使用一个简单的图来显示这个ORF的表达式概要文件。
情节(次yeastvalues(15日:))包含(的时间(小时));ylabel ('Log2相对表达水平');

您还可以绘制实际的表达式比率,而不是经过log2转换的值。
情节(*,2。^ yeastvalues(15日:))包含(的时间(小时));ylabel (的相对表达水平的);
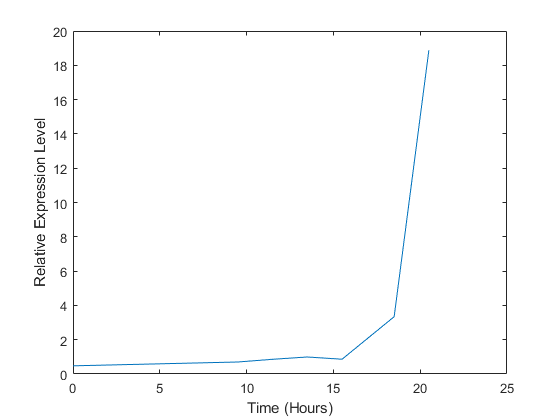
与这个ORF相关的基因,ACS1,似乎在双auxic转移中被强烈上调。你可以通过在同一个图上画多条线来比较这个基因和其他基因的表达。
持有在情节(*,2。^ yeastvalues(: 16:26)”)包含(的时间(小时));ylabel (的相对表达水平的);标题('个人资料表达级别');
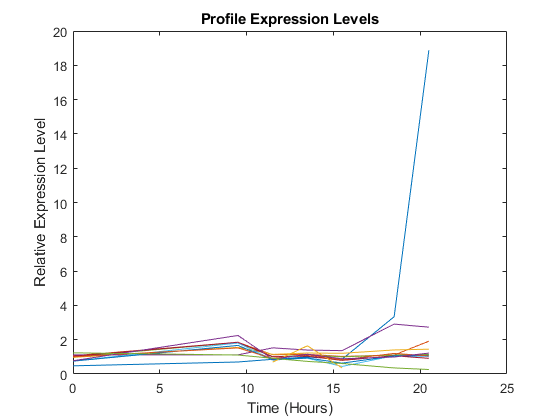
过滤基因
通常情况下,基因表达数据集包含与基因相对应的信息,这些基因在实验过程中没有显示出任何有趣的变化。为了更容易地找到感兴趣的基因,可以将数据集的大小减少到只包含最重要基因的某个子集。
如果您浏览基因列表,您将看到几个标记为的斑点“空”.这些是阵列上的空斑点,而它们可能具有与它们相关联的数据,因为此示例的目的,您可以考虑这些要点是噪声。可以使用这些点使用Strcmp.函数并从具有索引命令的数据集中删除。
emptySpots = strcmp (“空”,基因);yeastvalues (emptySpots:) = [];基因(emptySpots) = [];元素个数(基因)
ans = 6314
还可以看到数据集中的一些地方将表达式级别标记为南.这表明在特定的时间步长没有收集该点的数据。处理这些缺失值的一种方法是使用特定基因随时间变化的数据的平均值或中值来推断它们。这个例子使用了一种不那么严格的方法,即简单地丢弃任何没有测量一个或多个表达水平的基因的数据。这个函数isnan用于识别具有缺失数据的基因,使用索引命令用于删除具有缺失数据的基因。
纳丁德=任何(Isnan(yeastvalues),2);yeastvalues(纳丁德,:) = [];基因(Naninindes)= [];元素个数(基因)
ans = 6276
如果您要绘制所有其余配置文件的表达式配置文件,您将看到大多数配置文件是扁平的,与其他配置文件没有显著差异。这个平坦的数据显然是有用的,因为它表明与这些谱图相关的基因不受双auxic转移的显著影响;然而,在这个例子中,您感兴趣的是伴随双auxic转移的表达变化较大的基因。您可以使用生物信息学工具箱™中的过滤功能来删除具有不同类型配置文件的基因,这些配置文件不能提供有关受代谢变化影响的基因的有用信息。
你可以使用genevarfilter滤除随时间变化小的基因的功能。该函数返回与变量大小相同的逻辑数组(即掩码)基因1对应的行yeastvalues方差大于第10个百分位数,零对应于低于阈值的。您可以使用掩码对值建立索引,并删除过滤的基因。
掩码= genevarfilter (yeastvalues);: yeastvalues = yeastvalues(面具);基因=基因(面具);元素个数(基因)
ans = 5648
这个函数genelowvalfilter去除绝对表达值很低的基因。注意,这些筛选函数还可以自动计算筛选后的数据和名称,因此没有必要使用掩码索引原始数据。
(面具,yeastvalues,基因)= genelowvalfilter (yeastvalues,基因,“absval”log2 (3));元素个数(基因)
ANS = 822.
最后,您可以使用该函数geneentropyfilter删除其配置文件具有低熵的基因,例如数据的第15位熵级别。
[面膜,酵母,基因] =基因裂解(酵母,基因,“prctile”15);元素个数(基因)
ANS = 614.
聚类分析
现在您已经有了一个可管理的基因列表,您可以使用Statistics和Machine Learning Toolbox™中的一些不同的聚类技术来查找配置文件之间的关系。对于分层聚类,函数pdist计算配置文件之间的成对距离和链接创建层次集群树。
corrdist = pdist(yeastvalues,“相关系数”);clusterTree =连杆(corrDist,'平均数');
的集群函数根据截断距离或最大簇数计算簇。在这种情况下maxclust选项用于识别16个不同的群集。
集群=集群(clusterTree“maxclust”16);
这些基因簇中的基因图谱可以用简单的循环和子图命令。
数字为C = 1:16 subplot(4,4, C);情节(次,yeastvalues ((: = = c)集群)');轴紧的结束sgtitle ('配置文件的分层群集');
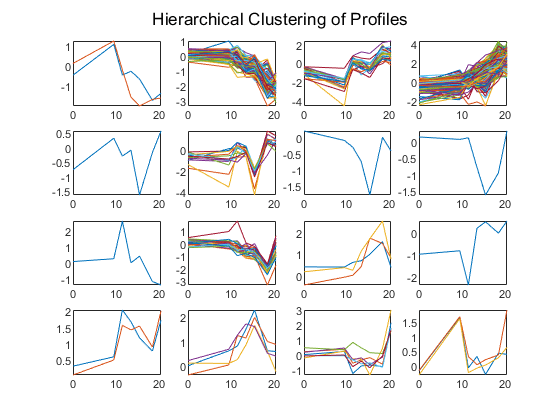
统计和机器学习工具箱也有一个k -均值聚类函数。同样,我们发现了16个簇,但由于算法不同,这些簇不一定与分层聚类发现的簇相同。
初始化随机数生成器的状态,以确保由这些命令生成的图形匹配此示例的HTML版本中的图。
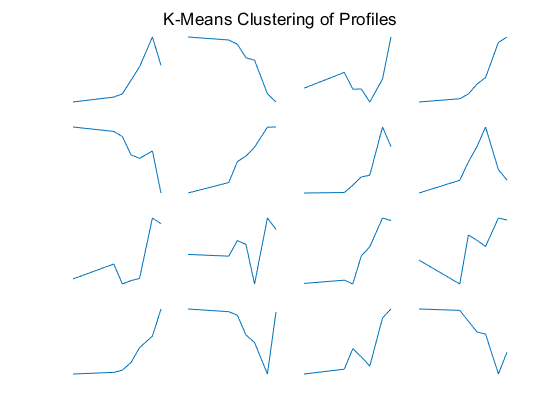
RNG('默认');[CIDX,CTRS] = kmeans(yeastvalues,16,“距离”,“相关系数”,'rep',5,“disp”,“最后一次”);数字为C = 1:16 subplot(4,4, C);情节(次,yeastvalues ((cidx = = c):) ');轴紧的结束sgtitle (“概况的K-Means聚类”);
重复1次,21次迭代,总距离之和= 23.4699。重复2次,22次迭代,总距离之和= 23.5615。重复3次,10次迭代,总距离之和= 24.823。重复4次,28次迭代,总距离之和= 23.4501。重复5次,19次迭代,总距离之和= 23.5109。距离的最佳总和= 23.4501
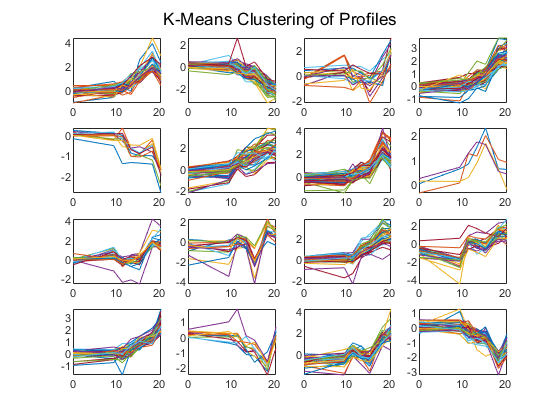
你可以绘制质心而不是绘制所有配置文件。
数字为C = 1:16 subplot(4,4, C);情节(次,点击率数据(c:) ');轴紧的轴离开结束sgtitle (“概况的K-Means聚类”);
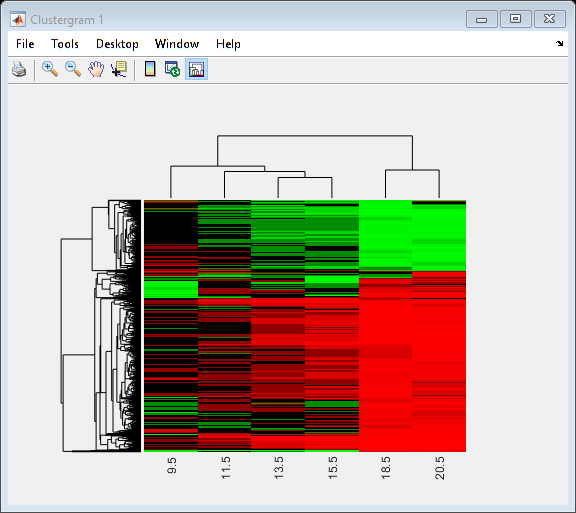
你可以使用clustergram功能要从分层聚类的输出中创建表达式的热图和树木图。
cgObj = clustergram (yeastvalues(:, 2:结束),'rowlabels'的基因,“ColumnLabels”,乘以(2:结束));
主要成分分析
主成分分析(PCA)是一种有用的技术,可用于降低大数据集的维数,例如来自微阵列的数据集。PCA也可以用于在有噪声的数据中寻找信号。这个函数mapcaplot计算数据集的主要组成部分并创建结果的散点图。您可以交互方式从其中一个绘图中选择数据点,并且这些点在另一个绘图中自动突出显示。这使您可以同时可视化多个维度。
h = mapcaplot (yeastvalues,基因);

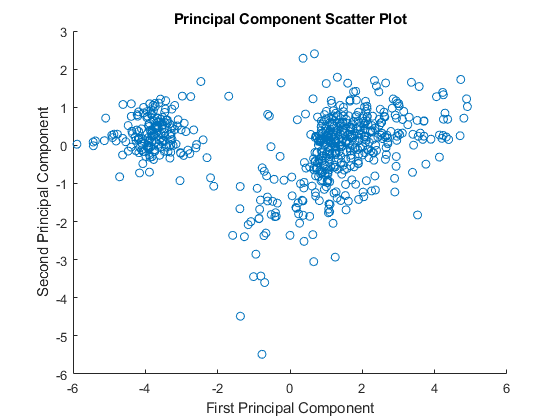
请注意,前两个主要成分的分数的散点图表明有两个不同的区域。这不是出乎意料的,因为过滤过程删除了具有低方差或低信息的许多基因。这些基因已经出现在散点图的中间。
如果你想看看主分量的值主成分分析函数用于计算数据集的主成分。
[pc, zscores, pcvars] = pca(酵母值);
第一个输出,个人电脑,是一个主要成分的矩阵yeastvalues数据。矩阵的第一列是第一个主分量,第二列是第二个主分量,以此类推。第二个输出,zscores,由主成分得分组成,即在主成分空间中酵母值的表示。第三个输出,pcvars,包含主成分差异,这可以测量每个主组件的数据算法的数量。
很明显,第一个主成分占了模型中方差的大部分。如下所示,您可以计算每个组件的方差的确切百分比。
pcvars. /笔(pcvars) * 100
Ans = 79.8316 9.5858 4.0781 2.6486 2.1723 0.9747 0.7089
这意味着差异的差异占前两个主要成分的差异。你可以使用浓汤命令查看方差的累积和。
CuMsum(PCVars./sum(PCVARS)* 100)
ANS = 79.8316 89.4174 93.4955 96.1441 98.3164 99.2911 100.0000
如果您想对主分量的绘制有更多的控制,您可以使用散射函数。
图散射(zscores (: 1), zscores (:, 2));包含(“第一主成分”);ylabel (第二主成分的);标题(“主成分散点图”);
创建散点图的另一种方法是使用函数g箭偶来自统计学和机器学习工具箱。g箭偶创建一个分组散点图,其中每一组的点都有不同的颜色或标记。您可以使用clusterdata,或任何其他聚类功能,以对点进行分组。
图PCClusters = ClusterData(Zscores(:,1:2),“maxclust”8“链接”,“影音”);gscatter (zscores (: 1) zscores (:, 2), pcclusters)包含(“第一主成分”);ylabel (第二主成分的);标题(“带有彩色簇的主成分散点图”);

自组织地图
如果您有深度学习工具箱™,您可以使用自组织映射(SOM)来聚类数据。
%检查是否安装了深度学习工具箱如果~((存在“selforgmap”),“文件”) disp (“本例中的自组织地图部分需要使用深度学习工具箱。”)返回结束
的selforgmap函数创建一个新的SOM网络对象。此示例将使用前两个主组件生成一个索峰。
P = zscores(: 1:2)”;Net = selforgmap([4 4]);
使用默认参数列车。
网=火车(净,P);
用plotsom在数据的散点图上显示网络。注意,SOM算法使用随机的起始点,因此每次运行的结果都会不同。
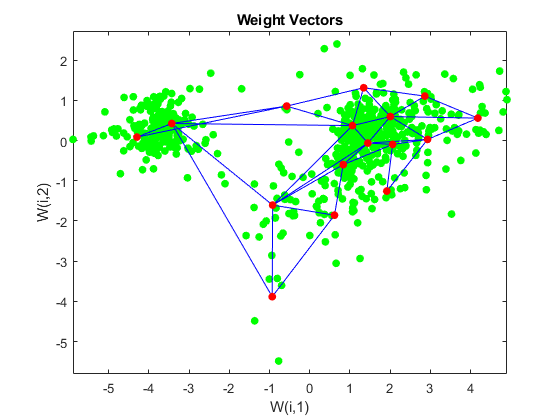
图绘图(p(1,:),p(2,:),'。G','Markersize', 20)在net.layers plotsom (net.iw {1}, {1} .distances)离开
您可以通过查找数据集中的每个点来分配使用SOM的群集。
距离= dist (P’,net.IW{1}”);[d, cndx] = min(距离,[],2);% CNDX包含集群指数图g箭偶(p(1,:),p(2,:),cndx);传奇离开;持有在net.layers plotsom (net.iw {1}, {1} .distances);持有离开
关闭所有数字。
关闭(“所有”);删除(cgObj);删除(h);
参考
[1] DeRisi J.L., Iyer, V.R. and Brown, P.O.,“在基因组规模上探索基因表达的代谢和遗传控制”,科学,278(5338):680- 6,1997。
您还可以从以下列表中选择一个网站: