このページの翻訳は最新ではありません。ここをクリックして、英語の最新版を参照してください。
曲線近似アプリにおける複数の近似の作成
近似の改良
単一の近似を作成した後、以下のいずれかのオプション手順を使用して近似を改良できます。
複数の近似の作成
単一の近似を作成した後、複数の近似を作成して比較すると役に立つ場合があります。複数の近似を作成すると、曲線近似アプリで、さまざまな近似タイプおよび設定を並べて比較できます。
近似を作成した後、以下のいずれかの方法を使用して近似を追加できます。
ドキュメント バーで近似の Figure のタブの隣にある [新規近似] ボタンをクリック。
ドキュメント バーを右クリックし、[新規近似]を選択。
[近似]、[新規近似]を選択。
追加したそれぞれの近似は、曲線近似アプリの新しいタブおよび[近似テーブル]の新しい行として表示されます。複数の近似の表示および解析の詳細については、曲線近似アプリにおける複数の近似の作成を参照してください。
オプションで、追加の近似を作成した後で[近似]、[データを使用]、[Other Fit Name]を選択することにより、前の近似からデータの選択をコピーできます。これにより、前の近似におけるx、y、zの選択と選択した検証データがコピーされます。近似オプションは変更されません。
セッションを使用して近似を保存して再度読み込みます。詳細は、セッションの保存と再読み込みを参照してください。
近似の複製
現在の近似タブのコピーを作成するには、[近似]、["Current Fit Name"を複製]を選択します。[近似テーブル]で近似を右クリックし、[複製]を選択することもできます。
追加したそれぞれの近似は、曲線近似アプリの新しいタブとして表示されます。
近似の削除
以下のいずれかの方法でセッションから近似を削除します。
近似タブの表示を選択し、[近似]、[
Current Fit Nameを削除]を選択。[近似テーブル]で近似を選択し、删除キーを押下。
テーブル内の近似を右クリックし、[
Current Fit Nameを削除]を選択。
複数の近似の同時表示
複数の近似を作成している場合、曲線近似アプリで、さまざまな近似タイプおよび設定を並べて比較できます。プロットを同時に表示し、適合度の統計量を調べて近似を比較することができます。ここでは、複数の近似を比較する方法について説明します。
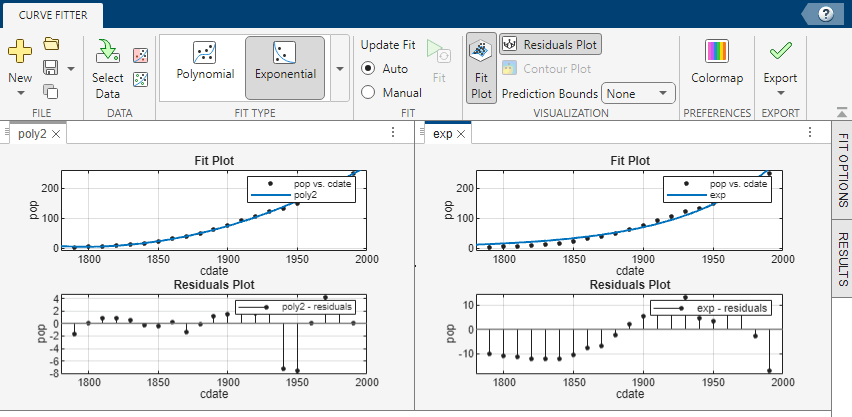
プロットの比較や複数の近似の同時表示を行うには、曲線近似アプリの右上にあるレイアウト コントロールを使用します。または、メニュー バーの[ウィンドウ]をクリックし、表示するタイルの数と位置を選択することもできます。"近似の Figure"には、単一の近似の近似設定、結果ペインおよびプロットが表示されます。次に、左右に並べて表示された 2 つの近似の Figure の例を示します。[近似テーブル]にリストされたセッション内の複数の近似を表示することができます。

近似の Figure の表示を閉じることができます ([閉じる] ボタン、[近似]メニューまたはコンテキスト メニューを使用します)。ただし、これらの近似はセッション内に残っています。[近似テーブル]にはすべての近似 (開かれているものと閉じられているもの) が表示されます。[近似テーブル]の近似をダブルクリックすると、その近似の Figure が開きます (既に開いている場合はフォーカスが移動)。近似を削除するには、近似の削除を参照してください。
ヒント
次に示すように広いスペースにプロットを表示して比較するには、[表示]メニューを使用して[近似設定]、[近似結果]、[近似テーブル]ペインの表示/非表示を切り替えます。
個々の近似のドッキングとドッキング解除、近似間の移動を行うには、曲線近似アプリの MATLAB®標準の[デスクトップ]および[ウィンドウ]メニューを使用します。詳細は、デスクトップのレイアウトの変更を参照してください。
近似テーブルの統計量の使用
[近似テーブル]リスト ペインには、現在のセッションにあるすべての近似が表示されます。

グラフィカルな方法を使用して適合度を評価した後で、テーブルに表示される適合度の統計量を調べて近似を比較することができます。適合度の統計量は、モデルがデータをどの程度適切に近似できるかの判断に役立ちます。テーブルの列ヘッダーをクリックすると、統計量、名前、近似タイプなどで並べ替えることができます。
以下のガイドラインは、統計量を使用して最適な近似を決定するのに役立ちます。
[SSE]は近似の誤差の二乗和です。値がゼロに近いほど、近似が予測に有効であることを示します。
[決定係数]は応答値と予測された応答値の間の相関を二乗したものです。値が 1 に近いほど、そのモデルによって分散の大部分が考慮されていることを示します。
[DFE]は誤差の自由度です。
[自由度調整済み決定係数]は自由度が調整済みの決定係数です。値が 1 に近いほど、近似が優れていることを意味します。
[RMSE]は平方根平均二乗誤差または標準誤差です。値が 0 に近いほど、近似が予測に有効であることを示します。
[係数の数]はモデルの係数の数です。複数の近似において適合度の統計量が似ている場合、係数の数が最も少ない近似を探すと最適な近似の決定に役立ちます。過適合を回避するには、係数の数と統計量が示す適合度のトレードオフを行わなければなりません。
Curve Fitting Toolbox™ の統計量の詳細な説明については、適合度の統計量を参照してください。
さまざまな近似の統計量を比較し、過適合と適合不足の間の最適なトレードオフを実現する近似を決定するには、曲線近似アプリにおける近似の比較で説明しているプロセスと同様のプロセスを使用します。
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)