VAR模型案例研究
这个例子展示了如何分析一个VAR模型。
案例概述
本节包含了中描述的工作流的一个示例VAR模型的工作流。该示例使用三个时间序列:GDP,M1货币供应量,3个月国库券利率。例子所示:
加载和转换为平稳数据
将所述转换后的数据到样品前体,估计和预测的时间间隔,以支持一个返回检验实验金宝app
让几个模型
拟合模型数据
决定哪个模型是最好的
基于最佳模型进行预测
加载和转换数据
该文件Data_USEconModel附带计量经济学工具箱™软件。该文件包含来自圣路易斯的经济数据的联邦储备银行(FRED)在表阵数据库的时间序列。这个例子使用了三个时间序列:
国内生产总值(
国内生产总值)M1货币供应量(
M1SL)三个月国库券利率(
TB3MS)
加载数据集。创建实际GDP的变量。
加载Data_USEconModelDataTable.RGDP = DataTable.GDP./DataTable.GDPDEF*100;
绘制数据以寻找趋势。
图次要情节(3、1、1)的阴谋(DataTable.Time DataTable.RGDP,'R');标题(实际国内生产总值的网格)在次要情节(3、1、2);情节(DataTable.Time DataTable.M1SL,“b”);标题('M1'网格)在次要情节(3,1,3);图(DataTable.Time,DataTable.TB3MS,数k)标题(“3谟国库券”网格)在

实际GDP和M1数据似乎呈指数级增长,而短期国债收益率没有显示出指数级增长。为了对抗实际GDP和M1的趋势,对数据取不同的对数。同样,通过第一个差来稳定国债系列。同步日期系列,以便每个列的数据具有相同的行数。
rgdpg = price2ret(DataTable.RGDP);m1slg = price2ret(DataTable.M1SL);dtb3ms = DIFF(DataTable.TB3MS);数据= array2timetable([rgdpg m1slg dtb3ms]…'RowTimes',DataTable.Time(2:结束),“VariableNames”,{“RGDP”'M1SL'“TB3MS”});图次要情节(3、1、1)的阴谋(Data.Time Data.RGDP,'R');标题(实际国内生产总值的网格)在次要情节(3、1、2);图(Data.Time,Data.M1SL,“b”);标题('M1'网格)在次要情节(3,1,3);情节(Data.Time Data.TB3MS,数k),标题(“3谟国库券”网格)在

前两列的比例大约比第三列小100倍。将前两列乘以100,这样时间序列的比例就大致相同了。这种比例可以很容易地在同一块图上绘制所有级数。更重要的是,这种类型的扩展使优化在数值上更稳定(例如,最大化loglikelihood)。
数据{:1:2}{:1:2}= 100 *数据;图绘制(Data.Time Data.RGDP,'R');保持在图(Data.Time,Data.M1SL,“b”);datetick ('X'网格)在情节(Data.Time Data.TB3MS,数k);传说(实际国内生产总值的,'M1',“3谟国库券”);保持离

选择并适合模型
您可以为数据选择许多不同的模型。这个例子使用了四个模型。
VAR(2)与对角自回归
带有完全自回归的VAR(2)
带有对角自回归的VAR(4)
带有完全自回归的VAR(4)
从系列的开头删除所有缺失值。
IDX =所有(〜ISMISSING(数据),2);数据=数据(IDX,:);
创建四个模型。
numseries = 3;dnan =诊断接头(nan (numseries, 1));seriesnames = {实际国内生产总值的,'M1',“3谟国库券”};VAR2diag = varm ('AR'{dnaN之间dnaN之间},'SeriesNames',seriesnames);VAR2full = varm (numseries 2);VAR2full。SeriesNames = SeriesNames;VAR4diag = varm ('AR',{dnan dnan dnan dnan},'SeriesNames',seriesnames);VAR4full = varm(numseries,4);VAR4full.SeriesNames = seriesnames;
矩阵dnan是对角矩阵与为NaN沿其主对角线值。通常,缺失的值指定模型的参数的存在,并且指示该参数需要是适合的数据。MATLAB®持有的非对角线元素,0,在估计期间固定。相反,规范VAR2full和VAR4full有矩阵组成的为NaN值。因此,估计适合自回归矩阵的全矩阵。
要评估模型的质量,可以创建将响应数据划分为三个阶段的索引向量:预采样、估计和预测。将模型与估计数据进行拟合,利用预充足期提供滞后数据。将拟合模型的预测结果与预测数据进行比较。估计期在样本内,预测期在样本外(也称为样本外)回溯测试)。
对于两个VAR(4)模型中,样品前体期是前四行数据。因此,所有的车型都适合同一数据使用相同的样品前期限为VAR(2)模型。这是必要的模型拟合比较。对于这两种模式,在预测期内是行的最后10%数据。模型的估计周期从第5行到90%行。定义这些数据周期。
idxPre = 1:4;T =小区(0.9 *大小(数据,1));idxEst = 5:T;idxF =(T + 1):大小(数据,1);FH = numel(idxF);
现在,该模型和时间序列存在,你可以很容易地适应模型的数据。
[EstMdl1,EstSE1,logL1,E1] =估计(VAR2diag,数据{idxEst ,:}…“Y0”、数据{idxPre:});[EstMdl2, EstSE2 logL2, E2] =估计(VAR2full、数据{idx:}…“Y0”、数据{idxPre:});[EstMdl3,EstSE3,logL3,E3] =估计(VAR4diag,数据{idxEst ,:}…“Y0”、数据{idxPre:});[EstMdl4, EstSE4 logL4, E4] =估计(VAR4full、数据{idx:}…“Y0”、数据{idxPre:});
该
EstMdl模型对象是拟合的模型。该
EstSE结构包含拟合模型的标准误差。该
logL值是拟合模型的loglikelihood,您可以使用它来帮助选择最佳模型。该
Ë载体是残差,其尺寸为估计数据相同。
检查型号充足
通过显示,可以检查估计的模型是否稳定且可逆描述每个对象的属性。(还有在这些模型中没有MA而言,这样的模式必然是可逆的。)的说明显示,所有评估模型是稳定的。
EstMdl1.Description
ANS = “AR-固定3维VAR(2)模型”
EstMdl2.Description
ANS = “AR-固定3维VAR(2)模型”
EstMdl3.Description
ans = "AR-Stationary三维VAR(4) Model"
EstMdl4.Description
ans = "AR-Stationary三维VAR(4) Model"
AR-固定出现在输出中,表示自回归过程是稳定的。
您可以使用受限(对角)AR模型与非受限(完全)AR模型进行比较lratiotest。测试拒绝或不能拒绝假设限制模型是足够的,有一个默认的5%的容差。这是一个样品中测试。
应用似然比检验。你必须从返回的汇总结构提取估计参数的数量总结。然后,将估计参数的数量和loglikeli之间的差异传递给lratiotest执行测试。
结果1 =总结(EstMdl1);NP1 = results1.NumEstimatedParameters;结果2 =总结(EstMdl2);NP2 = results2.NumEstimatedParameters;结果3 =总结(EstMdl3);NP3 = results3.NumEstimatedParameters;results4 =总结(EstMdl4);NP4 = results4.NumEstimatedParameters;reject1 = lratiotest(logL2,logL1,NP2 - NP1)
reject1 =合乎逻辑1
reject3 = lratiotest(logL4,logL3,np4 - np3)
reject3 =合乎逻辑1
reject4 = lratiotest(logL4,logL2,NP4 - NP2)
reject4 =合乎逻辑0
该1结果表明,似然比检验拒绝了两种限制模型,而选择了相应的非限制模型。因此,基于此检验,我们选择不受限制的VAR(2)和VAR(4)模型。但是,该测试并不排斥不受限制的VAR(2)模型,而是支持不受限制的VAR(4)模型。(本测试将VAR(2)模型视为VAR(4)模型,其限制条件为自回归矩阵AR(3)和AR(4)为0。)因此,不受限制的VAR(2)模型似乎是最好的模型。
为了在一个集合中找到最好的模型,最小化Akaike信息准则(AIC)。使用样本内数据计算AIC。计算四种模型的判据。
AIC = aicbic([logL1 logL2 logL3 logL4],[NP1 NP2 NP3 NP4])
AIC =1×4103×1.4794 1.4396 1.4785 1.4537
根据这一标准,最好的模型是不受限制的VAR(2)模型。还要注意,不受限制的VAR(4)模型的Akaike信息比任何一个受限制的模型都要低。基于此准则,不受限制的VAR(2)模型最好,其次是不受限制的VAR(4)模型。
四个模型的预测与之比较的预测数据,使用预测。这个函数返回一个双方的平均时间序列预测和误差协方差矩阵,提供有关的手段置信区间。这是外的样品的计算。
[FY1, FYCov1] =预测(EstMdl1、跳频、数据{idx:});[FY2, FYCov2] =预测(EstMdl2、跳频、数据{idx:});[FY3, FYCov3] =预测(EstMdl3、跳频、数据{idx:});[FY4, FYCov4] =预测(EstMdl4、跳频、数据{idx:});
为最佳拟合模型估计大约95%的预测区间。
extractMSE = @ (x)诊断接头(x) ';MSE = cellfun (extractMSE FYCov2,“UniformOutput”,假);SE = SQRT(cell2mat(MSE));YFI =零(FH,EstMdl2.NumSeries,2);YFI(:,:,1)= FY2 - 2 * SE;YFI(:,:,2)= FY2 + 2 * SE;
该图显示的阴影区域的最佳拟合模型向右的预测。
数字;对于j = 1: EstMdl2。NumSeries次要情节(3 1 j);h1 =情节(Data.Time ((end-49):结束),数据{(end-49):最终,j});保持在;h2 =情节(Data.Time (idxF) FY2 (:, j));h3 =情节(Data.Time (idxF) YFI (j,: 1),'K--');情节(Data.Time (idxF) YFI (: j 2),'K--');标题(EstMdl2.SeriesNames {j});甘氨胆酸h =;填充([Data.Time (idxF (1) h。XLim (2 [2]) Data.Time (idxF (1))),…h。YLim([1,1,2,2]),数k,“FaceAlpha”,0.1%,'EdgeColor','没有');图例([H1 H2 H3]“真正的”,'预测',“95%的预测区间”,…“位置”,“西北”)举行离;结束

现在可以直接计算预测和数据之间的平方和误差。
Error1 = Data{idxF,:} - FY1;Error2 = Data{idxF,:} - FY2;Error3 = Data{idxF,:} - FY3;Error4 = Data{idxF,:} - FY4;SSerror1 = Error1(:)' * Error1(:);SSerror2 = Error2(:)' * Error2(:);SSerror3 = Error3(:)' * Error3(:);SSerror4 = Error4(:)' * Error4(:);图条([SSerror1 SSerror2 SSerror3 SSerror4],.5) ylabel(“误差平方的总和”)设置(GCA,“XTickLabel”,…{“AR2诊断”“AR2全”“第四次评估报告诊断”“AR4完整”})标题("预测误差平方和")
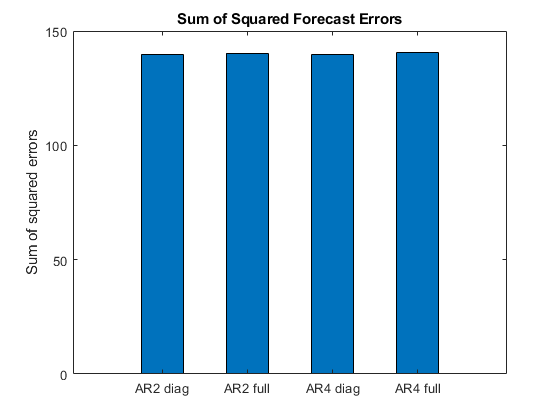
四种模型的预测性能相似。
完整的AR(2)模型似乎是最好的,最吝啬的契合。它的模型参数如下。
总结(EstMdl2)
AR-Stationary 3-Dimensional VAR(2) Model Effective Sample Size: 176 Number of Estimated Parameters: 21 LogLikelihood: -698.801 AIC: 1439.6 BIC:1506.18价值StandardError TStatistic PValue __________ _________________ __________ __________常数(1)0.34832 0.11527 3.0217 0.0025132常数(2)0.55838 0.1488 3.7526 0.00017502常数(3)-0.45434 0.15245 -2.9803 0.0028793基于“增大化现实”技术的{1}(1,1)0.26252 0.07397 3.5491 0.00038661基于“增大化现实”技术的{1}(2,1)-0.029371 0.095485 -0.3076 0.75839基于“增大化现实”技术的{1}(3,1)0.22324 0.097824 2.2821 0.022484基于“增大化现实”技术的{1}(1、2)-0.074627 0.054476 -1.3699 0.17071基于“增大化现实”技术的{1}(2,2)0.2531 0.070321 3.5992 0.00031915基于“增大化现实”技术的{1}(3 2)-0.017245 0.072044 -0.239360.81082基于“增大化现实”技术的{1}(1、3)0.032692 0.056182 0.58189 0.56064基于“增大化现实”技术的{1}(2、3)-0.35827 0.072523 -4.94 7.8112 e-07 AR {1} (3,3) -0.29179 0.0743 -3.9272 8.5943 e-05 AR{2}(1,1) 0.21378 0.071283 2.9991 0.0027081基于“增大化现实”技术的{2}(2,1)-0.078493 0.092016 -0.85304 0.39364基于“增大化现实”技术的{2}(3,1)0.24919 0.094271 2.6433 0.0082093基于“增大化现实”技术的{2}(1、2)0.13137 0.051691 2.5415 0.011038基于“增大化现实”技术的{2}(2,2)0.38189 0.066726 5.7233 1.045 e-08 AR{2}(3 2) 0.049403 0.068361 0.72269 0.46987基于“增大化现实”技术的{2}(1、3)-0.22794 0.059203 -3.85 0.00011809基于“增大化现实”技术的{2}(2、3)-0.0052932 - 0.076423-0.069262 0.94478 AR{2}(3,3) -0.37109 0.078296 -4.7397 2.1408e-06创新协方差矩阵:0.5931 0.0611 0.1705 0.0611 0.9882 -0.1217 0.1705 -0.1217 1.0372创新相关矩阵:1.0000 0.0798 0.2174 0.0798 1.0000 - 0.2174 -0.1202 1.0000
预测的观察
您可以使用拟合的模型预测或预测(EstMdl2)通过:
调用
预测走过最后几排YF模拟与几个时间序列
模拟
在这两种情况下,变换的天气预报所以他们直接等同于原来的时间序列。
生成拟合模型预测10使用最迟开始时间预测。
[YPred, YCov] =预测(EstMdl2 10数据{idxF:});
通过还原应用于原始数据的缩放和差分来转换预测。在使用之前,请确保在时间序列的开头插入最后一个观察值cumsum撤销差异。并且,由于取对数后会发生差分,所以在使用前先插入对数cumsum。
YFirst =数据表(IDX,{“RGDP”'M1SL'“TB3MS”});EndPt = YFirst {,,};EndPt(:,1:2)=日志(EndPt(:,1:2));YPred(:,1:2)= YPred(:,1:2)/ 100;%重缩放比例YPred = [EndPt;YPred];%准备cumsumYPred (: 1:3) = cumsum (YPred (: 1:3));YPred (: 1:2) = exp (YPred (: 1:2));fdates = dateshift (YFirst.Time(结束),'结束',“季”,0:10);%插入预测地平线数字对于J = 1:EstMdl2.NumSeries副区(3,1,j)的积(fdates,YPred(:,j)的'--b')举行在图(YFirst.Time,YFirst {:,J},数k网格)在title(EstMdl2.SeriesNames{j}) h = gca;填充([fdates (1) h。XLim (2 [2]) fdates (1)), h。YLim([1,1,2,2]),数k,…“FaceAlpha”,0.1%,'EdgeColor','没有');保持离结束

图中显示的外推法为浅灰色预测层中的蓝色虚线,原始数据系列为纯黑色。
看这个情节在过去几年得到的预测如何与最新的数据点的感觉。
YLast = YFirst(170年:,);数字对于J = 1:EstMdl2.NumSeries副区(3,1,j)的积(fdates,YPred(:,j)的“b——”)举行在情节(YLast.Time YLast {: j},数k网格)在title(EstMdl2.SeriesNames{j}) h = gca;填充([fdates (1) h。XLim (2 [2]) fdates (1)), h。YLim([1,1,2,2]),数k,…“FaceAlpha”,0.1%,'EdgeColor','没有');保持离结束
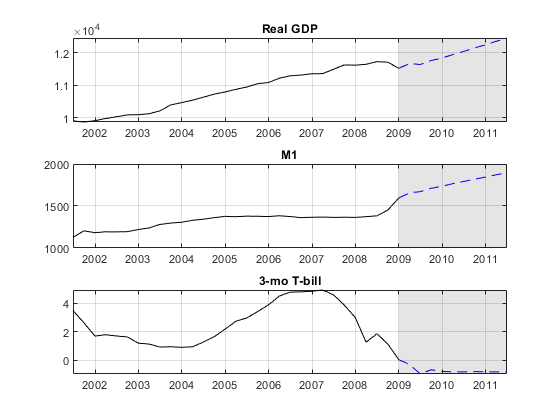
预报显示增加实际GDP和M1,并且在利率略有下降。然而,预测没有错误吧。
或者,您可以使用以下工具从拟合的模型生成10个预测,从最晚的时间开始模拟。该方法模拟了2000的时间序列的时间,然后产生用于每个周期的平均值和标准偏差。的偏离为每个周期的装置是在该期间的预测。
模拟从拟合模型开始的最新时间序列。
RNG(1);%用于重现YSim =模拟(EstMdl2,10,“Y0”,数据{idxF ,:}“NumPaths”,2000);
通过还原应用于原始数据的缩放和差分来转换预测。在使用之前,请确保在时间序列的开头插入最后一个观察值cumsum撤销差异。并且,由于取对数后会发生差分,所以在使用前先插入对数cumsum。
EndPt = YFirst {,,};日志(EndPt EndPt (1:2) = (1:2));YSim (1:2,::) = YSim (1:2,::) / 100;YSim = [repmat (EndPt [1, 2000]); YSim);YSim (1:3,::) = cumsum (YSim (: 1:3,:));YSim (1:2,::) = exp (YSim (:, 1:2,:));
计算每个系列的平均值和标准偏差,得出结果。该地块具有平均为黑色,与红色+/- 1个标准差。
YMean =意味着(YSim, 3);YSTD =性病(YSim 0 3);数字对于J = 1:EstMdl2.NumSeries副区(3,1,j)的积(fdates,YMean(:,j)的数k网格)在保持在情节(YLast.Time(端10:结束),YLast {端-10:端,J},数k)情节(fdates,YMean(:,J)+ YSTD(:,j)的“——r”) plot(fdates,YMean(:,j) - YSTD(:,j)“——r”) title(EstMdl2.SeriesNames{j}) h = gca;填充([fdates (1) h。XLim (2 [2]) fdates (1)), h。YLim([1,1,2,2]),数k,…“FaceAlpha”,0.1%,'EdgeColor','没有');保持离结束
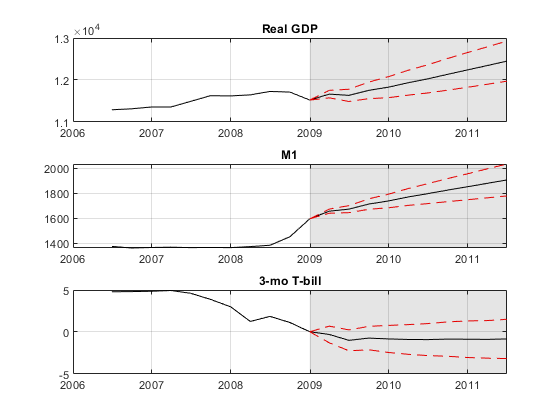
该图显示在GDP不断增长,中度到M1小的增长,不确定性的国库券利率的方向。
也可以看看
对象
功能
相关的话题
您还可以选择从下面的列表中的网站:
