このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
fitrsvm
サポートベクターマシン回帰モデルの近似
构文
说明
fitrsvmは,低〜中间元のの子データセットサポートベクター(svm)回帰回帰に学习をせるか,svm回帰モデルの交差検证行。fitrsvmは,カーネル关键ををするするするし,目的关键词によるのための二次计画によるによる,の二次计画法による,ISDAまたはl1ソフトマージンマージン最しサポートしししししし
高次元データセット,つまり多数の予測子変数が含まれているデータセットに対して線形SVM回帰モデルに学習をさせるには,代わりにFitrinear.を使用します。
バイナリ分类用途のsvmモデルに学习をさせる方法については,低〜中炎元の予测子データセットの合fitcsvm,高次元データセットの場合はfitclinearを参照してください。
MDL.= fitrsvm(资源描述那ResponseVarName的)资源描述に含まれている予测子の値とtbl.responseVarname.に含まれている応答値を使用して学習させた,完全な学習済みサポートベクターマシン(SVM)回帰モデルMDL.を返します。
例
線形サポートベクターマシン回帰モデルの学習
行动に格式さている标データデータ使しサポートマシン(svm)回帰回帰に学习
carsmallデータセットを読み込みます。
加载carsmallrng“默认”%的再现性
予测子阶数(X)として马力と重量を,応答変数(y)として英里/加仑を指定します。
x = [马力,重量];Y = MPG;
既定のSVM回帰モデルに学習をさせます。
Mdl = fitrsvm (X, Y)
Mdl = RegressionSVM ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' Alpha: [75x1 double] Bias: 57.3958 KernelParameters: [1x1 struct] NumObservations: 93 BoxConstraints: [93x1 struct] ConvergenceInfo: [1x1 struct] Is金宝appSupportVector: [93x1 logical] Solver: 'SMO'属性,方法
MDL.は学习させたRegressionSVMモデルです。
モデルが収束したかチェックします。
Mdl.ConvergenceInfo.Converged
ANS =.逻辑0.
0.は,モデルが収束しなかったことを示します。
標準化したデータを使用して,モデルを再学習させます。
MdlStd = fitrsvm (X, Y,“标准化”,真的)
MdlStd = RegressionSVM ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' Alpha: [77x1 double] Bias: 22.9131 KernelParameters: [1x1 struct] Mu: [109.3441 2.9625e+03] Sigma: [45.3545 805.9668] numobservers: 93 BoxConstraints: [93x1 double] ConvergenceInfo: [1x1 struct] IsSup金宝appportVector: [93x1 logical] Solver:SMO的属性,方法
モデルが収束したかチェックします。
MdlStd.ConvergenceInfo.Converged
ANS =.逻辑1
1は,モデルが収束したことを示します。
新しいモデルの再代入(標本内)平均二乗誤差を計算します。
lStd = resubLoss (MdlStd)
LSTD = 17.0256.
サポートベクターマシン回帰モデルの学習
UCI机器学习储存库
データをダウンロードして,'abalone.csv'という名前で現在のフォルダに保存します。
url =“https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data”;websave ('abalone.csv'url);
データをテーブルにます。
varnames = {“性”;'长度';“直径”;“高度”;“Whole_weight”;...“Shucked_weight”;“Viscera_weight”;'shell_weight';“戒指”};台= readtable ('abalone.csv'那“文件类型”那“文本”那'readvariablenames'、假);Tbl.Properties.VariableNames = varnames;
标本データには4177个の観测値が含まれています。性を除くすべての予測子変数は連続です。この変数はカテゴリカル変数で,可能な値は“米”(雄)、“F”(雌)および“我”(稚貝)です。目標は,物理的な測定値を使用して(戒指に格式されているアワビの轮の数号予测,年份を决定すること。
自动カーネルカーネルのカーネルを回帰て。
rng默认的%的再现性Mdl = fitrsvm(资源描述,“戒指”那“KernelFunction”那'高斯'那“KernelScale”那'汽车'那...“标准化”,真的)
mdl = regressionsvm predictornames:{1×8 cell} resportename:'rings'patporicalpricictors:1 responsefransform:'none'alpha:[3635×1双]偏置:10.8144内核参数:[1×1结构] mu:[1×10双] Sigma:[1×10双] NumObservations:4177 BoxConstraints:[4177×1双] ColoupGenceInfo:[1×1结构] IssupportVector:[4177×1金宝app逻辑]求解器:'smo'
MDL.が学習済みのRegressionSVMモデルであることとプロパティのリストがコマンドウィンドウに表示されます。
ドット表记を使使用して,MDL.〖图库“
conv = mdl.convergenceInfo.converged Iter = mdl.numentations
conv =逻辑1 iter = 2759
返された结果は,このモデルが2759回の反复后に收束したことを示しています。
支持向量机回帰モデルの交差検証
carsmallデータセットを読み込みます。
加载carsmallrng“默认”%的再现性
予测子阶数(X)として马力と重量を,応答変数(y)として英里/加仑を指定します。
X =[马力重量];Y = MPG;
5分钟の交差検证を使て2つのsvm回帰回帰モデルを交差検证しし両ののモデルについてについてししのモデルの标准标准をししますますモデルでは既定の形形形をををををををををををををのののののの形カーネルをカーネルを使用して学习を行うように指定します。
mdllin = fitrsvm(x,y,“标准化”,真的,“KFold”5)
MdlLin = RegressionPartitionedSVM CrossValidatedModel: 'SVM' PredictorNames: {'x1' 'x2'} ResponseName: 'Y' NumObservations: 94 KFold: 5 Partition: [1x1 cvpartition] ResponseTransform: 'none'属性,方法
MdlGau = fitrsvm (X, Y,“标准化”,真的,“KFold”5,“KernelFunction”那'高斯'的)
mdlgau =回归partitionedsvm crossvalidatedmodel:'svm'predictornames:{'x1'x2'} racatectename:'y'numobservations:94 kfold:5分区:[1x1 cvpartition] responseetransform:'无'属性,方法
MdlLin。训练有素的
ans =5×1单元阵列{1x1 classreg.learning.regr.compactregressionsvm} {1x1 classreg.learning.regr.compactregressionsvm} {1x1 classreg.learning.regr.compactregressionsvm} {1x1 classreg.learning.regr.compactregressionsvm} {1x1 classreg.learning.regr.compactregressionsvm}
MdlLinとMdlGauはRegressionPartitionedSVM交差検証済みモデルです。各モデルの训练有素的プロパティは,CompactRegressionSVMモデルによる5行1列の细胞配列配列。セルセルのモデルは,観测観测ののを4つ使の,1つの分享到户外し习习行ったが格式ささった结果が纳され
モデルの汎化誤差を比較します。このケースでは,汎化誤差は標本外平均二乗誤差です。
mseLin = kfoldLoss (MdlLin)
mseLin = 17.4417
mseGau = kfoldLoss (MdlGau)
mseGau = 16.7355
ガウスカーネルを使用するSVM回帰モデルの方が,線形カーネルを使用するモデルより性能が優れています。
データセット全体をfitrsvmに渡すことにより,予測に適しているモデルを作成し,より高性能のモデルをもたらした名前と値のペアの引数をすべて指定します。ただし,交差検証オプションは指定しません。
MdlGau = fitrsvm (X, Y,“标准化”,真的,“KernelFunction”那'高斯');
一連の自動車のMPGを予測するため,自動車の馬力および重量の測定値が格納されているテーブルとMDL.を预测に渡します。
SVM回帰の最适化
この例では,fitrsvmを使用して自動的にハイパーパラメーターを最適化する方法を示します。この例では,carsmallデータを使使ます。
carsmallデータセットを読み込みます。
加载carsmall
予测子阶数(X)として马力と重量を,応答変数(y)として英里/加仑を指定します。
X =[马力重量];Y = MPG;
自動的なハイパーパラメーター最適化を使用して,5分割交差検証損失を最小化するハイパーパラメーターを求めます。
再現性を得るために,乱数シードを設定し,“expected-improvement-plus”の獲得関数を使用します。
rng默认的Mdl = fitrsvm (X, Y,'OptimizeHyperParameters'那'汽车'那...“HyperparameterOptimizationOptions”结构('获取功能名称'那...“expected-improvement-plus”))
|====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | BoxConstraint | KernelScale |ε| | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | | | |====================================================================================================================| | 最好1 | | 6.8077 | 10.787 | 6.8077 | 6.8077 | 0.35664 | 0.043031 | 0.30396 | | 2 |最好| 2.9108 | 0.081877 | 2.9108 | 3.1259 | 70.67 | 710.65 | 1.6369 | | 3 |接受| 4.1884 | 0.20844 | 2.9108 | 3.1211 | 14.367 | 0.0059144 | 442.64 | | 4 |接受| 4.159 | 0.083731 | 2.9108 | 3.0773 | 0.0030879 | 715.31 | 2.6045 | | 5 |的| 2.902 | 0.21632 | 2.902 | 2.9015 | 969.07 | 703.1 | 0.88614 | | 6 |接受| 4.1884 | 0.060628 | 2.902|2。9017 | 993.93 | 919.26 | 22.16 | | 7 | Accept | 2.9307 | 0.11344 | 2.902 | 2.9018 | 219.88 | 613.28 | 0.015526 | | 8 | Accept | 2.9537 | 0.43364 | 2.902 | 2.9017 | 905.17 | 395.74 | 0.021914 | | 9 | Accept | 2.9073 | 0.11177 | 2.902 | 2.9017 | 24.242 | 647.2 | 0.17855 | | 10 | Accept | 2.9044 | 0.29262 | 2.902 | 2.9017 | 117.27 | 173.98 | 0.73387 | | 11 | Accept | 2.9035 | 0.089326 | 2.902 | 2.9016 | 1.3516 | 131.19 | 0.0093404 | | 12 | Accept | 4.0917 | 0.080273 | 2.902 | 2.902 | 0.012201 | 962.58 | 0.0092777 | | 13 | Accept | 2.9525 | 1.035 | 2.902 | 2.902 | 77.38 | 65.508 | 0.0093299 | | 14 | Accept | 2.9352 | 0.11476 | 2.902 | 2.9019 | 21.591 | 166.43 | 0.035214 | | 15 | Accept | 2.9341 | 0.18814 | 2.902 | 2.9019 | 45.286 | 207.56 | 0.009379 | | 16 | Accept | 2.9104 | 0.13257 | 2.902 | 2.9018 | 0.064315 | 23.313 | 0.0093341 | | 17 | Accept | 2.9056 | 0.14982 | 2.902 | 2.9018 | 0.33909 | 40.311 | 0.053394 | | 18 | Accept | 2.9335 | 0.22816 | 2.902 | 2.8999 | 0.9904 | 41.169 | 0.0099688 | | 19 | Accept | 2.9885 | 0.30387 | 2.902 | 2.8994 | 0.0010647 | 32.9 | 0.013178 | | 20 | Accept | 4.1884 | 0.1126 | 2.902 | 2.9 | 0.0014524 | 1.9514 | 856.49 | |====================================================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Epsilon | | | result | log(1+loss) | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 21 | Accept | 2.904 | 0.13183 | 2.902 | 2.8835 | 88.487 | 405.92 | 0.44372 | | 22 | Accept | 2.9107 | 0.10942 | 2.902 | 2.8848 | 344.34 | 992 | 0.28418 | | 23 | Accept | 2.904 | 0.080631 | 2.902 | 2.8848 | 0.92028 | 70.985 | 0.52233 | | 24 | Accept | 2.9145 | 0.096946 | 2.902 | 2.8822 | 0.0011412 | 18.159 | 0.16652 | | 25 | Best | 2.8909 | 0.23112 | 2.8909 | 2.8848 | 0.7614 | 17.3 | 1.9075 | | 26 | Accept | 2.9188 | 0.13747 | 2.8909 | 2.8816 | 0.31049 | 18.301 | 0.35285 | | 27 | Accept | 2.9327 | 0.10354 | 2.8909 | 2.8811 | 0.015362 | 20.395 | 1.6596 | | 28 | Accept | 2.897 | 0.17449 | 2.8909 | 2.8811 | 3.3454 | 46.537 | 2.224 | | 29 | Accept | 4.1884 | 0.082271 | 2.8909 | 2.881 | 983.2 | 0.52308 | 910.91 | | 30 | Accept | 2.9167 | 0.084943 | 2.8909 | 2.8821 | 0.0011533 | 10.597 | 0.029731 |
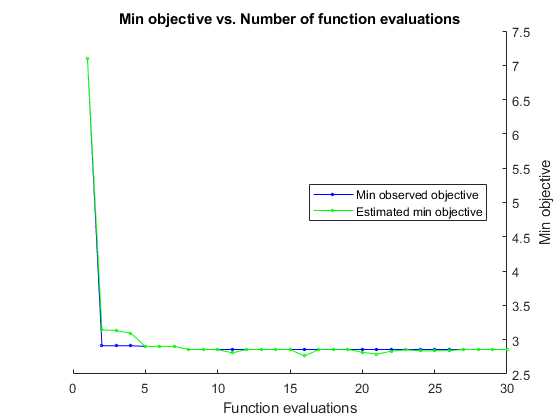
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:53.5026秒总目标函数计算时间:16.0569BoxConstraint KernelScale Epsilon _____________ ___________ _______ 0.7614 17.3 1.9075观测目标函数值= 2.8909估计目标函数值= 2.8957函数计算时间= 0.23112最佳估计可行点(根据模型):BoxConstraint KernelScale Epsilon _____________ ___________ _______ 88.487 405.92 0.44372估计的目标函数值= 2.8821估计的函数计算时间= 0.13339
Mdl = RegressionSVM ResponseName:‘Y’CategoricalPredictors: [] ResponseTransform:‘没有’α:[86 x1双]偏见:46.2480 KernelParameters: [1 x1 struct] NumObservations: 93 HyperparameterOptimizationResults: [1 x1 BayesianOptimization] BoxConstraints: x1双[93]ConvergenceInfo: [1 x1 struct] IsSupportVector: x1逻辑[93]解金宝app算器:SMO的属性,方法
最適化では,BoxConstraint那KernelScaleおよび埃斯利昂に対して探索を行いました。出力は,推定交差検証損失が最小になる回帰です。
入力引数
出力引数
制限
fitrsvmは,低~中次元のデータセットをサポートします。高次元データセットの場合は,代わりにFitrinear.を使用してください。
ヒント
データセットが大规模でない限制,常に常に子を标准标准しください(
标准化を参照してください)。標準化を行うと,予測子を測定するスケールの影響を受けなくなります。名前と値のペアの引数
KFoldを使用して交差検証を行うことをお勧めします。交差検証の結果により,SVMモデルがどの程度一般化を行うかを判断します。SVMモデルでは,サポートベクターの密度が低い方が望ましい状態です。サポートベクターの数を少なくするには,名前と値のペアの引数
BoxConstraintを大きい値に設定します。このようにすると,学習時間も長くなります。学习时间を最适最适にするににはははれるメモリコンピューターで许容れるの
缓存を大きくします。サポートベクターのの数が学习セット内の観测値数よりはるかに少ない考えられるられる场场
“ShrinkagePeriod”をを使してアクティブを小すると,收束收束大厦に高度化。'ShrinkatePeriod',1000のの用をお勧めし。回帰直線から離れている重複する観測値は,収束に影響を与えません。しかし,重複する観測値が回帰直線の近くに少しでもあると,収束が大幅に遅くなる可能性があります。収束を高速化するには,次の場合に
“RemoveDuplicates”,真的を指定します。多数の重複する観測値がデータセットに含まれている。
利用
ただし,学院时に元のセットセットを维持ためため,
fitrsvmは複数のデータセット,つまり元のデータセットと重複する観測値を除外したデータセットを一時的に格納しなければなりません。このため,重複がほとんど含まれていないデータセットの場合に真的を指定すると,fitrsvmは元のデータの场合の2倍に近いメモリを消费します。モデルに学習をさせた後で,新しいデータについて応答を予測するC / c++コードを生成できます。C / c++コードの生成にはMATLAB编码器™が必要です。详细详细について,コード生成の紹介を参照してください。
アルゴリズム
线形および非非形SVM回帰回帰の数码的定式化およびソルバーソルバーソルバーについてについてについてについてについてについてについてサポートベクターマシン回帰についてを参照してください。
南那<未定义>,空の文字ベクトル(''),空の字符串(""),および< >失踪値は,欠損データ値を示します。fitrsvmは,欠損応答に対応するデータ行全体を削除します。fitrsvmは,重みを正規化するときに,欠損している予測子が1つ以上ある観測値に対応する重みを無視します。したがって,観測値のボックス制約がBoxConstraintに等しくならない可性性がます。fitrsvmは,重み重みがゼロのの値を削除しし“标准化”,真的と“重量”を設定した場合,fitrsvmは対応する加重平均および加重標準偏差を使用して予測子を標準化します。つまり,fitrsvmは以下を使用して予測子j (xj)を標準化します。Xjk.は,予測子j(列)の観測値k(行)です。
予测カテゴリカルこれらのレベルれれなますます。
PredictorNamesプロパティには,元の予測子変数名のそれぞれについて1つずつ要素が格納されます。たとえば,3.つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、PredictorNamesははのの子数量名称が含まれいるいる1行3列の文章ベクトルの细胞配列配列なります。ExpandedPredictorNamesプロパティには,ダミー変数を含む予測子変数のそれぞれについて1つずつ要素が格納されます。たとえば,3.つの予測子があり、そのうちの 1 つは 3 つのレベルがあるカテゴリカル変数であるとします。この場合、ExpandedPredictorNamesは予測子変数および新しいダミー変数の名前が含まれている1行5列の文字ベクトルの细胞配列になります。同様に,
βプロパティには,ダミー変数を含む各予測子について1つずつベータ係数が格納されます。金宝appSupportVectorsプロパティプロパティに,ダミーダミー数を含むベクターの子の値がさされますとたとえばつの个ベクターと3つのつの子があり,そのつの子あり,そのうちの1つは3つのレベルがあるカテゴリカルカテゴリカルであるとします。このこの合,金宝appSupportVectorsはm行5列の行列になります。Xプロパティには,はじめに入力した状態で学習データが格納されます。ダミー変数は含まれません。入力がテーブルの場合,Xには予測子として使用した列のみが格納されます。
テーブルで予測子を指定した場合,いずれかの変数に順序付きのカテゴリが含まれていると,これらの変数について順序付きエンコードが使用されます。
k个个の顺序顺序付きレベルが変にに含まれてているいるいるいる合书,k - 1個のダミー変数が作成されます。j番目のダミー変数は、j までのレベルについては-1那J + 1からkまでのレベルについては+1になります。
ExpandedPredictorNamesプロパティに格式されるダミー位数の名前は1番目のレベルを示し,値は+1になります。レベル2、3、……kの名前を含むk - 1個の追加予測子名がダミー変数について格納されます。
どのソルバーもl1ソフトマージンマージン小气を装配しし。
学习データで想定される外れ値の比率を
P.とします。'OutlierFraction',pを設定した場合,“ロバスト学习”が実施されます。この方式では,最適化アルゴリズムが収束すると,観測値のうち100P.%の削除が試行されます。削除された観測値は,勾配の大きいものに対応します。
参照
克拉克,D., Z. Schreter, A. Adams。《Dystal和Backpropagation的定量比较》提交给澳大利亚神经网络会议,1996年。
[2]风扇,R.-e.,P.-h。陈和C.-J.林。“使用用于培训支持向量机的二阶信息的工作设置选择。”金宝app机械学习研究杂志,第6卷,2005年,第1889-1918页。
凯克曼V., T. -M。和M. Vogt。从大数据集训练核机的迭代单数据算法:理论与性能支持向金宝app量机:理论与应用。王力波主编,255-274。柏林:斯普林格出版社,2005年版。
[4] Lichman, M. UCI机器学习知识库[http://archive.ics.uci.edu/ml]。加州欧文:加州大学信息与计算机科学学院。
纳什、w.j.、t.l.塞勒斯、s.r.塔尔博特、a.j.考索恩和w.b.福特。鲍鱼的种群生物学(石决明物种)的塔斯马尼亚岛。I.黑唇鲍鱼(H. Rubra.)从北海岸和巴斯海峡群岛。”海洋渔业司,技术报告第48号,1994年。
[6] Waugh,S。“扩展和基准级联相关性:级联相关架构的扩展和前馈监督人工神经网络的基准。”塔斯马尼亚大学计算机科学论文,1995。
拡張機能
你也可以从以下列表中选择一个网站:
