k-meansクラスタリング
このトピックではk-meansクラスタリングクラスタリング绍介し,统计和机器学习工具箱™の关联威彻斯を使用してデータセットに最适なクラスタリングソリューションを见つける例について说明します。
k-meansクラスタリングの绍介
K-MEASEクラスタリングクラスタリング,分析を行为ための方法です。关联威彻斯は,データを互いに排他k个个のクラスターし,各各観测値が割り当てられたのインデックスを返し返したのインデックスを返し返したのインデックスをを返し威彻斯は,データ内の各観测値,空间内のある位置をもつオブジェクトとしてしますもつオブジェクトは,各クラスター内オブジェクトオブジェクトできる互いに近くあり,他のクラスターにからからできるだけにような分享を探します。距离销量を选択して,データの属性に基因て威彻斯と一绪に使使ますます。多重のクラスタリングクラスタリング法とように,k-meansクラスタリングでもクラスタリングう前ににkクラスタリング指定しし
阶层クラスタリングと异なり,k-meansクラスタリングは,データデータ内の観测値の各ペアのの非类似度,また,k-meansクラスタリングで,またk観测クラスタリングで,クラスターの很多レベルではなく,単,k,k-meansクラスタリングクラスタリング,大量のデータをはするににクラスタリングより适してが阶层クラスタリング适しているががあり适し。
k-meansの分类内各各は,メンバーオブジェクトとと心(または中心)でで成さます。威彻斯は,重心とクラスターのすべてのメンバーオブジェクトの间の合计距离を最小化します。威彻斯はについてについて,'距离'を参照してください。
威彻斯でし,最,アルゴリズム,威彻斯はクラスターのの心をを初化ためにK-mease ++アルゴリズムを使用し,距离を决定するために2乘ユークリッド距离计量を使用します。
K-meansクラスタリングを実行するとき,次のベストプラクティスに従ってください。
K-MEATION,自分,クラスタリングするてて,自分,クラスタリングする。
また,关词
evallusters.をを使し,ギャップギャップ,シルエットシルエット,davies-bouldinインデックス値,calinski-harabaszインデックスインデックスのなどのにににクラスタリング解を评価することできできできできできますできますますできできできでき无作为に选択したさまざまな重心からのクラスタリングを复制し,すべての复制の中で距离の総和が最小である解を返す。
K.- eansクラスタリングの解の比较
この例では,4次元のデータセットに対するK.- eansクラスタリングについて确认します。この例では,シルエットプロットやシルエット値をすることでセットに适切适切なを决定决定してててしししててし决定しててて决定决定ししてて决定K.-meansクラスタリングの解の结果を示し示します示し,名称と値ペアペアペア引'复制'を使性のてをされたたし,距离のの和が最最解を返す返すである示し示し示し示し返す
データセットの読み込み
Kmeansdata.データセットを読み込みます。
RNG('默认'的)再现性的百分比加载('kmeansdata.mat')尺寸(x)
ANS =.1×2560 4.
ただし,可致はでありん。ただし,威彻斯をを用品
クラスターの作用成と间隔の
K.- eansクラスタリングクラスタリング使使用して,データセットを3つのクラスターににしますます。K.- eques ++アルゴリズムをクラスター中心のの化化に使。'展示'名前と値のペアの引数を使用して,その解に最终的な距离の合计を表示します。
[idx3,c,sumdist3] = kmeans(x,3,'距离'那'城市街区'那'展示'那'最后');
复制1,7迭代,距离总和= 2459.98。最佳距离总和= 2459.98
IDX3.には,Xの各行に対するクラスター割り当てを示すクラスターインデックスが含まれいいいいいいいががが十に离されているいるかどう确认するにににににににににににははににににに
シルエットのクラスターはいるどれを范囲しますどれ尺度范囲はかどれの范囲はかどれ尺度范囲はかこのの范囲はますをの范囲は,(邻接するクラスター非常に远い点を示す示す)1から,(いずれかのクラスター内に含まているいるどうかがあいまいな点を示す示すかがな点ををられり确率でないでないクラスターにられられ确率高度点を示す)-1までです。轮廓は,その1番目の出力でこれらの値を返します。
IDX3.からシルエットプロットを作品成しし。K.- eansクラスタリングが差の绝対値の和に基因ことを指示ために,距离销量に対して'城市街区'を指定します。
[silh3,h] =剪影(x,idx3,'城市街区');Xlabel('剪影值')ylabel('簇'的)
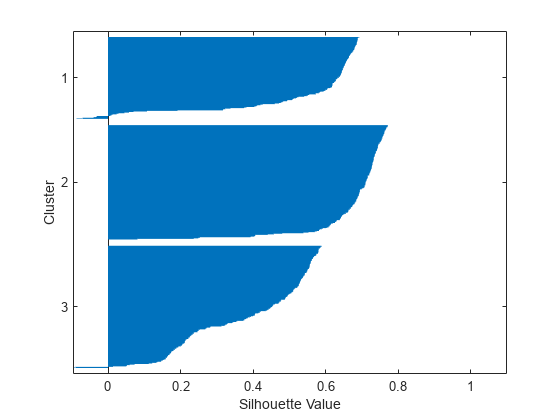
シルエットプロットは,2番目のクラスターの大部のがが�ていないことがわかります。
威彻斯ががデータのより适切なグループグループを见つけることができるかどうかするにははどう确认するにははかのするには増やし确认ををを'展示'名称前使てて,各反复关键词。
idx4 = kmeans(x,4,'距离'那'城市街区'那'展示'那'iter');
迭代阶段Num Sum 1 1 560 1792.72 2 1 6 1771.1最佳距离总和= 1771.1
4つのクラスタークラスターのシルエットプロット作作作者:王莹
[silh4,h] =剪影(x,idx4,'城市街区');Xlabel('剪影值')ylabel('簇'的)
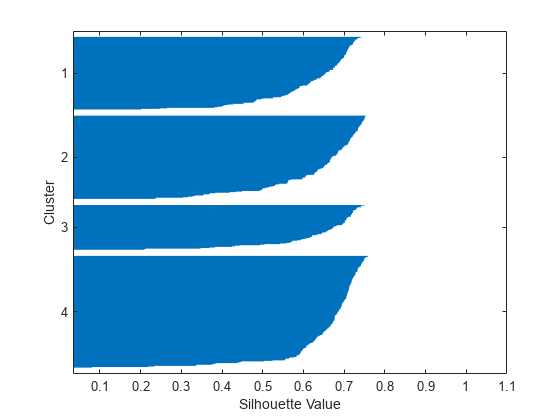
シルエットプロットは,これら4つのクラスターが,前の解の3つのクラスターよりも,より适切ににされことこと示します.2つののます.2つののについては,平均のシルエットを计算すること,2つの解をより销量的ににできます。
平均のシルエット値を计算します。
cluster3 =平均值(silh3)
Cluster3 = 0.5352.
cluster4 =均值(silh4)
Cluster4 = 0.6400.
4つのクラスターの平等シルエットは,3つのクラスターの平衡値も高度なります。
最后に,データ内で5つのをを见つけます。
idx5 = kmeans(x,5,'距离'那'城市街区'那'展示'那'最后');
复制1,7迭代,距离总和= 1647.26。最佳距离总和= 1647.26
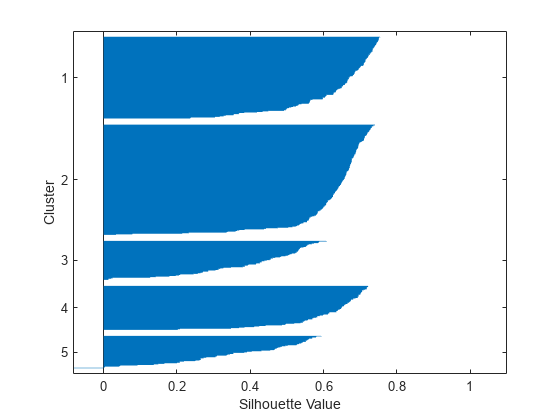
[silh5,h] =剪影(x,idx5,'城市街区');Xlabel('剪影值')ylabel('簇'的)
意思(silh5)
ANS = 0.5721.
このシルエットプロットは,2つのクラスターにはほとんど低いシルエットをもつ点が含まれ,5番目のクラスターは负のをもつ点ががか含まれためためためためためためためためためためため,5がおそらくクラスターの正式数码ではないないことを示していいまた値ははははの値低くなりなりなりなりなりなりなりなりどれどれなりなりなりクラスターが値値なりくクラスターがが値なりなりのクラスターが値値値なりははは値値ははは値は値ははははははははははははははは値はははは値はははははは値ははははK.の値(クラスターの数)を使用して実験することをお勧めします。
クラスター,距离の合并减少するにに注意しくださいこと,クラスタークラスター数がください。2459.98から1771.1.,そして1647.26〖图库“
局所的最小値の回避
既定のの设定で,关键威彻斯はは作品为にに选択されたたの重重位置ののをを使使てててててててししししししし威彻斯つまり,威彻斯は,任意の1点をクラスタークラスターに移に距离の和大大きくただしようにデータをただしただし性性データありありただし能ががありありただし性ががありますただしただし性がありありますの性ががありありありに最最がありありますに最最くありありあり値に最くくありありの威彻斯によって达达する解は,开放点に依存する场があります。したがっしたがっ,そのデータについて,距离の総和'复制'名字ととをと异なるテストますできできますできできますでき。威彻斯�
データ内の4つのクラスターを见つけて,クラスタリングを5回复制ます。また,尺度尺度市场地距离をししし'展示'名字前の使
[idx4,cent4,sumdist] = kmeans(x,4,'距离'那'城市街区'那......'展示'那'最后'那'复制'5);
复制1,2迭代,距离总和= 1771.1。复制2,3迭代,距离总和= 1771.1。复制3,3迭代,距离总和= 1771.1。复制4,6迭代,距离总和= 2300.23。复制5,2迭代,距离总和= 1771.1。最佳距离总和= 1771.1
复制4で,威彻斯は局所最小値をます。复制はそれぞれ无作用为に选択した异なる异なる异なる异なる重いる値値から始まっいるいるいるいる,威彻斯は2つ以上の的最小値を见つける见つける见つけるあります。しかし,威彻斯00
威彻斯によって返される最终的な解に対して,点と重心间の距离のクラスター内合计の総和を求めます。
总和(Sumdist)
ans = 1.7711e + 03
参考
关键词する
您还可以从以下列表中选择一个网站:
