このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
kmeans
k - meansクラスタリング
構文
説明
idx= kmeans (X,k)Xの観測をkクラスターに分割し,観測ごとにクラスターインデックスを含むn行1列のベクトル(idx)を返します。Xの行は観測に対応し,列は変数に対応します。
既定の設定では,kmeansはクラスター中心の初期化に二乗ユークリッド距離計量とk - means + +アルゴリズムを使用します。
例
k——クラスタリングアルゴリズムの学習
k——クラスタリングを使用してデータをクラスター化し,クラスター領域をプロットします。
フィッシャーのアヤメのデータセットを読み込みます。花弁の長さと幅を予測子として使用します。
负载fisheririsX =量(:,3:4);图;情节(X (: 1) X (:, 2),“k *’,“MarkerSize”5);标题“费舍尔的虹膜数据”;包含“花瓣长度(厘米)”;ylabel“花瓣宽度(cm)”;

大きいクラスターは,分散がより低い領域とより高い領域に分割されているように見えます。つまり,大きなクラスターは,2つのクラスターがオーバーラップしている可能性があります。
データをクラスタリングします。k= 3クラスターを指定します。
rng (1);%的再现性[idx C] = kmeans (X, 3);
idxは,Xに含まれている観測値に対応する,予測したクラスターのインデックスのベクトルです。Cは,最終的な重心位置が格納される3行2列の行列です。
kmeansを使用して各重心からグリッド上の点までの距離を計算します。これを行うには,重心(C)およびグリッド上の点をkmeansへ渡し,そのアルゴリズムの1反復を実装します。
x1 = min (X(: 1)): 0.01:马克斯(X (: 1));x2 = min (X(:, 2)): 0.01:马克斯(X (:, 2));[x1G, x2G] = meshgrid (x1, x2);XGrid = [x1G (:), x2G (:));在plot上定义一个精细的网格idx2Region = kmeans (XGrid 3“麦克斯特”,1,“开始”C);
警告:在1次迭代中收敛失败。
%将网格中的每个节点分配到最近的质心
kmeansは,アルゴリズムが収束しないことを示す警告を表示します。これは,反復が1回のみ実行されることから予想できます。
クラスターの領域をプロットします。
图;gscatter (XGrid (: 1) XGrid (:, 2), idx2Region,...[0, 0.75, 0.75, 0.75, 0, 0.75, 0.75, 0.75, 0],“. .”);持有在;情节(X (: 1) X (:, 2),“k *’,“MarkerSize”5);标题“费舍尔的虹膜数据”;包含“花瓣长度(厘米)”;ylabel“花瓣宽度(cm)”;传奇(“地区1”,《区域2》,区域3的,“数据”,“位置”,“东南”);持有从;
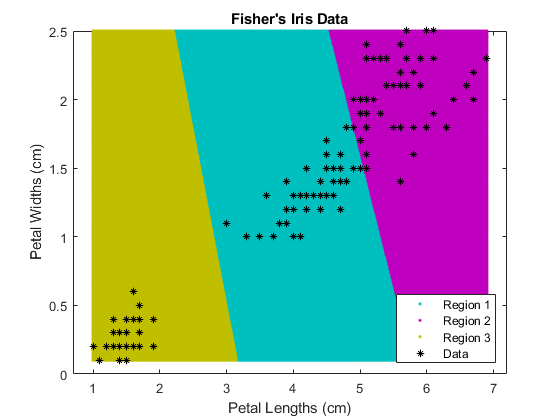
2つのクラスターにデータを分割
標本データを無作為に生成します。
rng默认的;%的再现性X = [randn(100 2) * 0.75 +(100 2)的;randn(100 2) * 0.5的(100 2)];图;情节(X (: 1) X (:, 2),“。”);标题随机生成的数据的;

データ内に2つのクラスターが存在するように見えます。
データを2つのクラスターに分割し,5つの初期値から最適な割り当てを選択します。最終出力を表示します。
选择= statset (“显示”,“最后一次”);[idx C] = kmeans (X, 2,“距离”,“cityblock”,...“复制”5,“选项”、选择);
重复1,3次迭代,总距离之和= 201.533。重复2,5次迭代,总距离之和= 201.533。重复3,3次迭代,总距离之和= 201.533。重复4,3次迭代,总距离之和= 201.533。重复5次,2次迭代,总距离之和= 201.533。距离的最佳总和= 201.533
既定では,k——+ +を使用して複製が個別に初期化されます。
クラスターとクラスター重心をプロットします。
图;情节(X (idx = = 1,1) X (idx = = 1、2),“r”。,“MarkerSize”, 12)在情节(X (idx = = 2, 1), X (idx = = 2, 2),“b”。,“MarkerSize”12)情节(C (: 1), C (:, 2),“kx”,...“MarkerSize”15岁的“线宽”3)传说(“集群1”,《集群2》,“重心”,...“位置”,“西北”)标题“集群分配和质心”持有从

idxを轮廓へ渡すことで,クラスターがどの程度適切に分離されたかを判断できます。
並列計算を使用するクラスターデータ
大きなデータセットのクラスタリングでは,特にオンライン更新(既定で設定されている)を使用すると時間がかかる場合があります。并行计算工具箱™のライセンスがある場合に並列計算のオプションを設定すると,kmeansは各クラスタリングタスク(または複製)を並列的に実行します。さらに,复制> 1である場合,並列計算により収束までの時間が短くなります。
混合ガウスモデルから大きなデータセットを無作為に生成します。
μ= bsxfun (@times(20、30),(1:20)');%高斯混合均值rn30 = randn(30、30);σ= rn30 ' * rn30;%对称正定协方差Mdl = gmdistribution(μ、σ);定义高斯混合分布rng (1);%的再现性X =随机(Mdl, 10000);
Mdlは20個の成分をもつ30次元のgmdistributionモデルです。Xは,Mdlから生成されたデータが含まれている10000行30列の行列です。
並列計算のオプションを指定します。
流= RandStream (“mlfg6331_64”);%随机数流选择= statset (“UseParallel”,1,“UseSubstreams”,1,...“流”、流);
RandStreamの入力引数“mlfg6331_64”は,乗法ラグフィボナッチ発生器アルゴリズムを使用するよう指定します。选项は,推定を制御するためのオプションを指定するフィールドをもつ構造体配列です。
k——クラスタリングを使用してデータをクラスター化します。データにk= 20個のクラスターがあることを指定し,反復回数を増やします。通常,目的関数には局所的最小値が含まれます。10個の複製を指定して、より低い局所的最小値の検出に役立てます。
抽搐;启动秒表计时器(sumd idx, C, D) = kmeans (X, 20,“选项”选项,“麦克斯特”, 10000,...“显示”,“最后一次”,“复制”10);
使用“local”配置文件启动并行池(parpool)…连接到6个工人。复制5,72次迭代,总距离之和= 7.73161e+06。重复1,64次迭代,总距离之和= 7.72988e+06。重复3,68次,总距离之和= 7.72576e+06。重复4,84次,总距离之和= 7.72696e+06。重复6,82次迭代,总距离之和= 7.73006e+06。重复7,40次迭代,总距离之和= 7.73451e+06。重复2,194次迭代,总距离之和= 7.72953e+06。重复9,105次迭代,总距离之和= 7.72064e+06。 Replicate 10, 125 iterations, total sum of distances = 7.72816e+06. Replicate 8, 70 iterations, total sum of distances = 7.73188e+06. Best total sum of distances = 7.72064e+06
toc终止秒表计时器
运行时间为61.915955秒。
6つのワーカーが利用可能であることがコマンドウィンドウに示されます。ワーカーの数はシステムにより異なる場合があります。コマンドウィンドウは,各複製の反復回数および最終的な目的関数値を表示します。複製9は距離の総和が最小なので,その結果が出力引数に含まれます。
既存クラスターへの新しいデータの割り当てとC / c++コードの生成
kmeansは,k——クラスタリングを実行して,データをk個のクラスターに分割します。新しいデータセットをクラスター化するときに,kmeansを使用して,既存のデータと新しいデータが含まれる新しいクラスターを作成できます。関数kmeansはC / c++コード生成をサポートするので,学習データを受け入れてクラスター化の結果を返すコードを生成してから,コードをデバイスに展開できます。このワークフローでは学習データを渡さなければなりませんが,サイズが非常に大きい可能性があります。デバイスのメモリを節約するため,kmeansとpdist2をそれぞれ使用して,学習と予測を分離することができます。
kmeansを使用してMATLAB®でクラスターを作成し,生成されたコードでpdist2を使用して新しいデータを既存のクラスターに割り当てます。コード生成用に,クラスターの重心位置と新しいデータセットを受け入れて最も近いクラスターのインデックスを返すエントリポイント関数を定義します。次に,エントリポイント関数のコードを生成します。
C / c++コードの生成にはMATLAB®编码器™が必要です。
k——クラスタリングの実行
3つの分布を使用して,学習データセットを生成します。
rng (“默认”)%的再现性X = [randn(100 2) * 0.75 +(100 2)的;randn(100 2) * 0.5的(100 2);randn (100 2) * 0.75);
kmeansを使用して,学習データを3つのクラスターに分割します。
[idx C] = kmeans (X, 3);
クラスターとクラスター重心をプロットします。
图gscatter (X (: 1), (:, 2), idx,“bgm”)举行在情节(C (: 1), C (:, 2),“kx”)传说(“集群1”,《集群2》,“集群3”,聚类质心的)
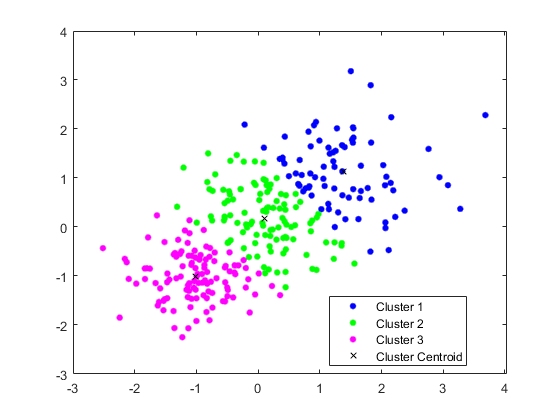
既存クラスターへの新しいデータの割り当て
検定データセットを生成します。
Xtest = [randn(10, 2) * 0.75 +的(10,2);randn(10, 2) * 0.5的(10,2);randn (10, 2) * 0.75);
既存のクラスターを使用して,検定データセットを分類します。pdist2を使用して,各検定データ点から最も近い重心を求めます。
[~, idx_test] = pdist2 (C Xtest“欧几里得”,“最小”1);
gscatterを使用して検定データをプロットします。idx_testを使用して検定データにラベルを付けます。
gscatter (Xtest (: 1) Xtest (:, 2), idx_test,“bgm”,“哦”)传说(“集群1”,《集群2》,“集群3”,聚类质心的,...“数据分类为第一组”,“数据分类为第二组”,...“数据分类为第3组”)

コードの生成
新しいデータを既存のクラスターに割り当てるCコードを生成します。C/C++ コードの生成には MATLAB® Coder™ が必要であることに注意してください。
重心位置と新しいデータを受け入れてから,pdist2を使用して最も近いクラスターを求める,findNearestCentroidという名前のエントリポイント関数を定義します。
MATLABのアルゴリズムについてのコードを生成しようとしていることを指示するため,コンパイラ命令% # codegen(またはプラグマ)をエントリポイント関数のシグネチャの後に追加します。この命令を追加すると,コード生成時にエラーになる違反の診断と修正をMATLAB代码分析器が支援します。
类型findNearestCentroid%显示findNearestCentroid.m的内容
函数idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'欧几里得','最小',1);找到最近的质心
メモ:このページの右上にあるボタンをクリックしてこの例をMATLAB®で開くと,MATLAB®で例のフォルダーが開きます。このフォルダーには,エントリポイント関数のファイルが含まれています。
codegen(MATLAB编码器)を使用してコードを生成します。CおよびC++ は静的な型の言語なので、エントリポイント関数内のすべての変数のプロパティをコンパイル時に決定しなければなりません。findNearestCentroidの入力のデータ型と配列サイズを指定するため,arg游戏オプションを使用して,特定のデータ型および配列サイズをもつ一連の値を表すMATLAB式を渡します。詳細については,コード生成用の可変サイズ引数の指定を参照してください。
codegenfindNearestCentroidarg游戏{C, Xtest}
代码生成成功。
codegenは,プラットフォームに依存する拡張子をもつ墨西哥人関数findNearestCentroid_mexを生成します。
生成されたコードを検証します。
myIndx = findNearestCentroid (C, Xtest);myIndex_mex = findNearestCentroid_mex (C, Xtest);verifyMEX = isequal (idx_test myIndx myIndex_mex)
verifyMEX =逻辑1
isequalは,すべての入力が等しいことを意味する逻辑1 (真正的)を返します。この比較により,同じインデックスを関数pdist2、関数findNearestCentroid,および墨西哥人関数が返すことを確認します。
GPU编码器™を使用して,最適化されたCUDA®コードを生成することもできます。
cfg = coder.gpuConfig (墨西哥人的);codegen配置cfgfindNearestCentroidarg游戏{C, Xtest}
コード生成の詳細については,一般的なコード生成のワークフローを参照してください。GPU编码器の詳細については,GPU编码器入門(GPU编码器)とサポートされる関数(GPU编码器)を参照してください。
入力引数
出力引数
詳細
アルゴリズム
kmeansは2つのフェーズの反復アルゴリズムを使用して,すべてのkクラスターにわたって合計される点と重心間距離の総計を最小化します。1番目のフェーズでは,“バッチ更新”を使用します。つまり,各反復で,最も近いクラスターの重心に点を再割り当てするという操作をすべて同時に行ってから,クラスターの重心を再計算します。このフェーズでは,局所的最小値となる解に収束されないこともあります。つまり1つの点を他のクラスターに移動するデータ分割がと距離の総和を増大させます。これは,規模の小さなデータセットでよく発生します。バッチフェーズは高速ですが,2番目のフェーズの開始点となる解だけが概算される可能性があります。
2番目のフェーズでは,“オンライン更新”を使用します。この更新では,点を個別に再割り当てし,再割り当てすることで距離の合計が減少する場合は,各再割り当ての後にクラスター重心を再計算します。このフェーズでの各反復は,すべての点を経過する1つの引き渡しで構成されます。このフェーズは局所的最小値に収束されます。ただし,距離の総和がより低い局所的最小値が他にある可能性もあります。一般に大域的最小値の検出は,開始点を網羅的に選択することで解決します。しかし,通常は無作為な開始点をもつ複製を複数使用すると,結果的に解は大域的最小値になります。
复制= r > 1および开始が+(既定値)の場合,k - means + +アルゴリズムに従って,さまざまなシードの集合rが選択される可能性もあります。选项のUseParallelオプションを有効にし,复制> 1とした場合,各ワーカーはシードの選択とクラスター化を並列で行います。
参照
亚瑟,大卫和塞吉·瓦西里维茨基。" K-means++:小心播种的好处"第18届ACM-SIAM离散算法年会论文集,2007,第1027-1035页。
[2] Lloyd, Stuart P. < PCM中的最小二乘量化>IEEE信息理论汇刊。1982年第28卷,129-137页。
多变量观测。John Wiley & Sons, Inc., 1984。
聚类分解与分析:理论,FORTRAN程序,实例。J.戈德施密特(J. Goldschmidt)翻译。纽约:霍尔斯特德出版社,1985年。
拡張機能
参考
链接|clusterdata|轮廓|parpool(并行计算工具箱)|statset|gmdistribution|kmedoids
你也可以从以下列表中选择一个网站:
