このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
多重比較
はじめに
分散分析(方差分析)手法では,一連のグループの平均(処理効果)が等しいかどうかを検定します。帰無仮説が棄却された場合,すべてのグループの平均が等しいわけではないという結論が得られます。しかし,この結果からはどのグループの平均が異なるかに関する詳しい情報は得られません。
どの平均のペアが有意に異なるかを判別するために一連のt検定を実行することは推奨されません。複数のt検定を実行した場合,平均が有意であると考えられる確率と有意差の結果は,多数の検定を行ったことが原因かもしれません。これらのt検定は,同じ標本のデータを使用するので,独立していません。このため,複数の検定の有意水準を定量化することがより困難になります。
実際には真である帰無仮説(H01)が回のt検定で棄却される確率が小さい値(たとえば0.05)であるとします。そして,独立したt検定を6回行ったとします。0.05各検定の有意水準がの場合,H0が各ケースについて真であるとすると,H0が検定により棄却できないという正しい結果になる確率は(0.95)6= 0.735です。そして,いずれかの検定により帰無仮説が誤って棄却される確率は1 - 0.735 = 0.265になります。これは,0.05よりはるかに大きい値です。
複数検定の補正には,多重比較法が使用できます。年代tatistics and Machine Learning Toolbox™ の関数multcompareは,グループの平均(処理効果)を多重対比較します。オプションとして,テューキーのHSD法の基準(既定のオプション),ボンフェローニの方法,シェッフェの方法,フィッシャーの最小有意差(LSD)法,およびt検定に対するダンとシダックのアプローチがあります。
グループの平均の多重比較を実行するには,構造体统计数据をmultcompareの入力引数として指定します。统计数据は,次の関数のいずれかから取得できます。
kruskalwallis- 1因子レイアウトについてのノンパラメトリック手法弗里德曼- 2因子レイアウトについてのノンパラメトリック手法
反復測定の多重比較法のオプションについては,multcompare(RepeatedMeasuresModel)を参照してください。
1因子方差分析による多重比較
標本データを読み込みます。
负载carsmall
英里/加仑は各自動車のガロンあたりの走行マイル数,气缸は各自動車の気筒の数(4,6または8)を表します。
気筒数が異なる自動車ではガロンあたりの走行マイル数(mpg)の平均が異なるかどうかを検定します。また,多重比較検定に必要な統計量も計算します。
[p ~统计]= anova1 (MPG,气缸,“关闭”);p
p = 4.4902 e-24
p値は約0という小さい値なので,気筒数が異なる自動車ではガロンあたりの走行マイル数の平均が有意に異なることが強く示されます。
ボンフェローニの方法を使用して多重比較検定を実行し,どの気筒数で自動車の性能が異なるかを判別します。
[结果,意味着]= multcompare(统计数据,“CType”,“bonferroni”)
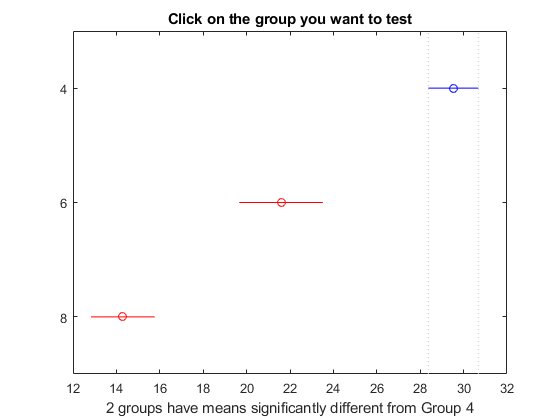
结果=3×61.0000 2.0000 4.8605 7.9418 11.0230 0.0000 1.0000 3.0000 12.6127 15.2337 17.8548 0.0000 2.0000 3.0000 3.8940 7.2919 10.6899 0.0000
意味着=3×229.5300 0.6363 21.5882 1.0913 14.2963 0.8660
行列结果で1、2および3はそれぞれ気筒数が4、6および8の自動車に対応しています。初めの2列には,どのグループを比較したかが示されています。たとえば,1行目では 4 気筒の自動車と 6 気筒の自動車を比較しています。4 列目には、比較したグループにおける平均 mpg の差が示されています。3 列目と 5 列目には、グループ平均の差に関する 95% の信頼区間の下限と上限が示されています。最後の列には、検定のp値が示されています。すべてのp値がゼロなの,ですべてのグループの平均mpgがすべてのグループで異なっていることがわかります。
図の青いバーは4気筒の自動車のグループを表しています。赤いバーは,他のグループを表しています。自動車の平均mpgについてどの赤い比較区間も重なっていないので,気筒数が4、6または8の車では平均mpgが有意に異なることがわかります。
行列意味着の1列目には,自動車の各グループについて平均mpgの推定値が格納されます。2列目には,推定値の標準誤差が格納されます。
3因子方差分析の多重比較
標本データを読み込みます。
Y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]';G1 = [1 2 1 2 1 2];g2 = {“嗨”;“嗨”;“罗”;“罗”;“嗨”;“嗨”;“罗”;“罗”};g3 = {“可能”;“可能”;“可能”;“可能”;“6月”;“6月”;“6月”;“6月”};
yは応答ベクトル,g1、g2およびg3はグループ化変数(因子)です。各因子には2つのレベルがあり,yのすべての観測値は因子のレベルの組み合わせによって識別されます。たとえば,観測値y (1)は,因子g1のレベル1,因子g2のレベル“嗨”および因子g3のレベル“可能”に関連付けられています。同様に,観測値y (6)は,因子g1のレベル2,因子g2のレベル“嗨”および因子g3のレベル“6月”に関連付けられています。
すべての因子レベルについて応答が同じであるか検定します。また,多重比較検定に必要な統計量も計算します。
[~,~,stats] = anovan(y,{g1 g2 g3}),“模型”,“互动”,...“varnames”,{g1的,“g2”,“g3”});
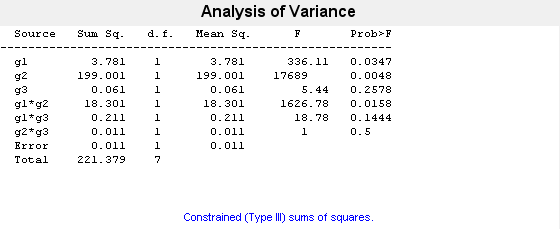
0.2578というp値は,因子g3のレベル“可能”および“6月”について平均応答が有意には異なっていないことを示しています.0.0347というp値は,因子g1のレベル1および2について平均応答が有意に異なっていることを示しています。同様に,0.0048というp値は,因子g2のレベル“嗨”および“罗”について平均応答が有意に異なっていることを示しています。
多重比較検定を実行し,因子g1およびg2についてどのグループが有意に異なるかを調べます。
结果= multcompare(统计,“维度”[1, 2])
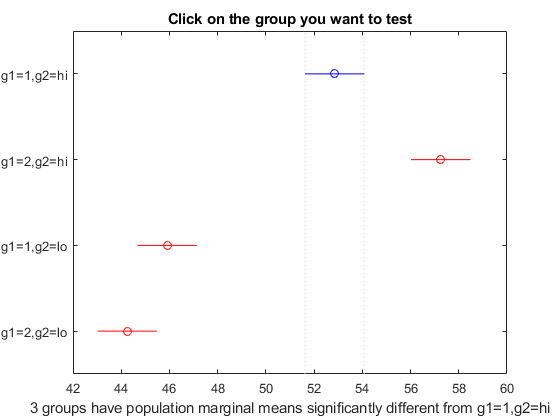
结果=6×61.0000 2.0000 -6.8604 -4.4000 -1.9396 0.0272 1.0000 3.0000 4.4896 6.9500 9.4104 0.0170 1.0000 4.0000 6.1396 8.6000 11.0604 0.0136 2.0000 3.0000 8.8896 11.3500 13.8104 0.0101 2.0000 4.0000 10.5396 13.0000 15.4604 0.0087 3.0000 4.0000 -0.8104 1.6500 4.1104 0.0737
multcompareは2つのグループ化変数g1およびg2についてグループ(レベル)の組み合わせを比較します。行列结果1はで,数値g1のレベル1とg2のレベル嗨の組み合わせに,数値2はg1のレベル2とg2のレベル嗨の組み合わせに対応しています。同様に3という数値はg1のレベル1とg2のレベル罗の組み合わせに4という数値はg1のレベル2とg2のレベル罗の組み合わせに対応しています。この行列の最後の列には,p値が格納されています。
たとえば,この行列の1行目は,g1のレベル1とg2のレベル嗨の組み合わせがg1のレベル2とg2のレベル嗨の組み合わせと同じ平均応答値になっていることを示しています。この検定に対応するp値は0.0280なので,平均応答が有意に異なっていることがわかります。この結果は,図からもわかります。青いバーは,g1のレベル1とg2のレベル嗨の組み合わせについて平均応答の比較区間を示しています。赤いバーは,他のグループの組み合わせについて平均応答の比較区間を示しています。どの赤いバーも青いバーと重なっていないので,g1のレベル1とg2のレベル嗨の組み合わせの平均応答が他のグループの組み合わせの平均応答と有意に異なっていることがわかります。
対応するグループの比較区間をクリックすると,他のグループについて検定を行うことができます。クリックしたバーは青になります。有意に異なるグループのバーは,赤になります。有意には異ならないグループのバーは,灰色になります。たとえば,g1のレベル1とg2のレベル罗の組み合わせの比較区間をクリックすると,g1のレベル2とg2のレベル罗の組み合わせの比較区間は重なるので灰色になります。逆に,他の比較区間は赤になり,有意に異なることを示します。
多重比較法
multcompareで行う多重比較法を指定するには,“CType”という名前と値のペアの引数を使用します。multcompareでは,次の手順を使用できます。
テューキーのHSD法
テューキーのHSD法を指定するには,“CType”、“Tukey-Kramer”または“CType”、“hsd”という名前と値のペアの引数を使用します。検定は,スチューデント化された範囲分布に基づいて行われます。H0:α我=αjは次の場合に棄却されます。
ここで, は,パラメーターkおよび自由度N - kでスチューデント化された範囲分布の上位100 *(1 -α)番目の百分位数です。kはグループ数(処理数または周辺平均),Nは観測値の総数です。
テューキーのHSD法は,平衡型の1因子方差分析および標本サイズが等しい同様の手順に最適です。サイズの異なる標本による1因子方差分析の場合も,標準的であることが実証されています。まだ証明されていないテューキークレーマーの推測によると,不平衡共変量値をもつ共分散の分析に見られるように,比較対象の数量が相関をもつ問題に対しても正確です。
ボンフェローニの方法
ボンフェローニの方法を指定するには,“CType”、“bonferroni”という名前と値のペアを使用します。この方法では,多重比較を補正するように調整した後でスチューデントt分布の棄却限界値を使用します。H0:α我=αjは
という有意水準で棄却されます。kは次の場合のグループ数です。
ここでNは観測値の総数,kはグループ数(周辺平均)です。このアルゴリズムは保守的ですが,通常,矫正アルゴリズムほど保守的ではありません。
ダンとシダックのアプローチ
ダンとシダックのアプローチを指定するには,“CType”、“dunn-sidak”という名前と値のペアの引数を使用します。このアプローチでは,ダンにより提唱されシダックにより証明された調整を多重比較に対して行った後でt分布の棄却限界値を使用します。H0:α我=αjは次の場合に棄却されます。
ここで
kはグループ数です。この過程は,ボンフェローニのアルゴリズムに似ていますが,それほど保守的ではありません。
最小有意差
最小有意差法を指定するには,“CType”、“迷幻药”という名前と値のペアの引数を使用します。この検定では次の検定統計量を使用します。
H0:α我=αjは次の場合に棄却されます。
フィッシャーは,帰無仮説H0:α1=α2=……=αkが方差分析のF検定によって棄却された場合のみLSDを実行し,多重比較を防ぐことを提案しています。この場合でも,LSDではどの仮説も棄却されない可能性があります。また,一部のグループの平均に差がある場合でも,方差分析ではH0が棄却されない可能性がありますこのような状況になるのは,残りのグループ平均が等しいためF検定統計量が有意でなくなる可能性があるからです。他の条件がないと,LSDでは多重比較の問題を防止できません。
シェッフェの方法
シェッフェの方法を指定するには,“CType”、“矫正”という名前と値のペアの引数を使用します。棄却限界値はF分布から導き出されます。H0:α我=αjは次の場合に棄却されます。
この方法では,平均のすべての線形結合の比較について同時信頼度が与えられます。ペアの間の単純な差を比較するための,保守的なアルゴリズムです。
参照
米利肯g.a.和d。e。约翰逊。杂乱数据分析。第一卷:设计实验。佛罗里达州博卡拉顿:查普曼和霍尔/CRC出版社,1992年。
Neter J., M. H. Kutner, C. J. Nachtsheim, W. Wasserman.第4版。应用线性统计模型。欧文出版社,1996年。
Hochberg Y.和a.c. Tamhane。多重比较程序。霍博肯:约翰·威利父子公司,1987。
参考
multcompare|anova1|anova2|anovan|aoctool|kruskalwallis|弗里德曼
関連するトピック
你也可以从以下列表中选择一个网站:
