主要内容
extractSummary
从文档中提取摘要
描述
例子
总结文件
创建一个标记化文档数组。
str = [“那只敏捷的棕色狐狸跳过了那只懒狗。”“狐狸跳过了狗。”“懒狗看见一只狐狸在跳。”“好像有动物在跳别的动物。”有敏捷的动物,也有懒惰的动物];文件= tokenizedDocument (str);
属性提取文档的摘要extractSummary函数。默认情况下,该函数选择输入文档的1/10,进行四舍五入。
摘要= extractSummary(文档)
那只敏捷的棕色狐狸跳过了那只懒狗。
要指定更大的摘要,请使用“SummarySize”选择。提取一个包含三个文档的摘要。
摘要= extractSummary(文档,“SummarySize”3)
那只敏捷的棕色狐狸跳过了那只懒狗。7令牌:狐狸跳过了狗。9记号:似乎有动物跳来跳去。
评估文件的重要性
创建一个标记化文档数组。
str = [“那只敏捷的棕色狐狸跳过了那只懒狗。”“狐狸跳过了狗。”“懒狗看见一只狐狸在跳。”“好像有动物在其他动物身上跳来跳去。”有敏捷的动物,也有懒惰的动物];文件= tokenizedDocument (str);
提取一个包含三个文档的摘要。第二个输出分数包含摘要文档重要性分数。
(总结,成绩)= extractSummary(文档,“SummarySize”3)
那只敏捷的棕色狐狸跳过了那只懒狗。10个标记:似乎有动物跳过其他动物。7令牌:狐狸跳过了狗。
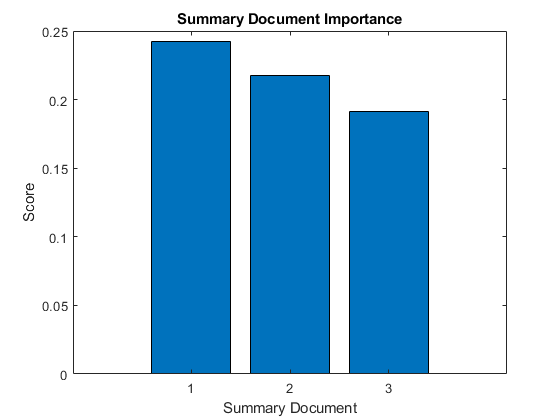
成绩=3×10.2426 0.2174 0.1911
用条形图将分数形象化。
图酒吧(分数)包含(“总结文件”) ylabel (“分数”)标题(“总结文档的重要性”)
句子层面上总结
要对单个文档进行总结,请将文档拆分为一个句子数组,并使用extractSummary函数。
创建包含文档的字符串标量。
str =...“有一只敏捷的狐狸。狐狸是棕色的。有一只狗+...”是懒惰。这只狗很懒。狐狸跳过了狗。”+...“那只敏捷的棕色狐狸跳过了那只懒狗。”;
将字符串分割成句子splitSentences函数。
str = splitSentences (str)
str =6 x1字符串“有一只敏捷的狐狸。”“狐狸是棕色的。”“有一只懒狗。”“这只狗很懒。”“狐狸跳过了狗。”“那只敏捷的棕色狐狸跳过了那只懒狗。”
创建包含句子的标记化文档数组。
文件= tokenizedDocument (str)
documents = 6x1 tokenizedDocument: 6 tokens:有一个quick fox。5代币:狐狸是棕色的。8代币:有一只懒惰的狗。这只狗很懒。7令牌:狐狸跳过了狗。10代币:那只敏捷的棕色狐狸跳过了这只懒狗。
从使用的句子中提取摘要extractSummary函数。要返回包含三个文档的摘要,请设置“SummarySize”选项3。要确保摘要文档以与输入文档相同的顺序出现,请设置“OrderBy”选项“位置”.
摘要= extractSummary(文档,“SummarySize”,3,“OrderBy”,“位置”)
summary = 3x1 tokenizedDocument: 6 token:有一个quick fox。7令牌:狐狸跳过了狗。10代币:那只敏捷的棕色狐狸跳过了这只懒狗。
要将这些句子重新构建为单个文档,请使用joinWords功能,并用the连接句子加入函数。
句子= joinWords(总结);summaryStr =加入(句子)
“有一只敏捷的狐狸。狐狸从狗身上跳过去。那只敏捷的棕色狐狸跳过了那只懒狗。”
要删除周围的标点符号,请使用取代函数。
punctuationRight = [“。””、““”“)””:““?”“啊!”];summaryStr =取代(summaryStr,”“+ punctuationRight punctuationRight);punctuationLeft = [”(““”];替换(summaryStr,punctuationLeft + .”“punctuationLeft)
“有一只敏捷的狐狸。狐狸从狗身上跳过去。那只敏捷的棕色狐狸跳过了那只懒狗。”
输入参数
输出参数
另请参阅
tokenizedDocument|bleuEvaluationScore|rougeEvaluationScore|bm25Similarity|cosineSimilarity|textrankScores|lexrankScores|mmrScores|rakeKeywords|textrankKeywords
介绍了R2020a
你也可以从以下列表中选择一个网站:
