机器学习模型通常被称为“黑匣子”,因为它们的知识表示不直观,而且,因此,很难理解他们的工作原理。可解释的机器学习是指克服大多数机器学习算法的黑匣子性质的技术。通过揭示各种功能如何为预测贡献(或不贡献),您可以验证该模型正在使用正确的证据,以获得其预测,并找到在培训期间不明显的模型偏差。
实践者寻求模型的可解释性主要有三个原因:
- 指导方针:“黑盒”模型违反了许多公司技术最佳实践和个人偏好。
- 验证:理解预测在哪里或为什么会出错,并运行“假设”场景,以提高模型的鲁棒性和消除偏差,这是很有价值的。
- 法规:需要模型的可解释性,以符合敏感应用(如金融、公共卫生和交通)的政府法规。
可解释的机器学习解决了这些问题,并在预测解释的情况下增加了模型的信任,这是重要的或要求的。
可解释机器学习工作在三个层次:
本地:解释个人预测背后的因素,比如为什么贷款申请被拒绝
队列:演示一个模型如何在一个训练或测试数据集中对特定人群或组进行预测,例如为什么一组制造产品被归类为错误的下载188bet金宝搏
全球:了解机器学习模型是如何在整个训练或测试数据集上工作的,比如一个模型对放射图像进行分类需要考虑哪些因素
一些机器学习模型,如线性回归和决策树,本质上是可解释的。然而,可解释性往往是以牺牲权力和准确性为代价的。

图1:模型性能与解释性之间的权衡。
使用MATLAB®对机器学习,您可以应用技术来解释和解释最受欢迎和高度准确的机器学习模型,该模型并不固有地解释。
局部可解释的模型不可知解释(LIME):用简单的可解释模型(例如线性模型或决策树)近似于对兴趣预测的邻域的复杂模型,并将其作为代理以解释原始(复杂)模型的工作原理。下面的图2说明了涂抹石灰的三个主要步骤。
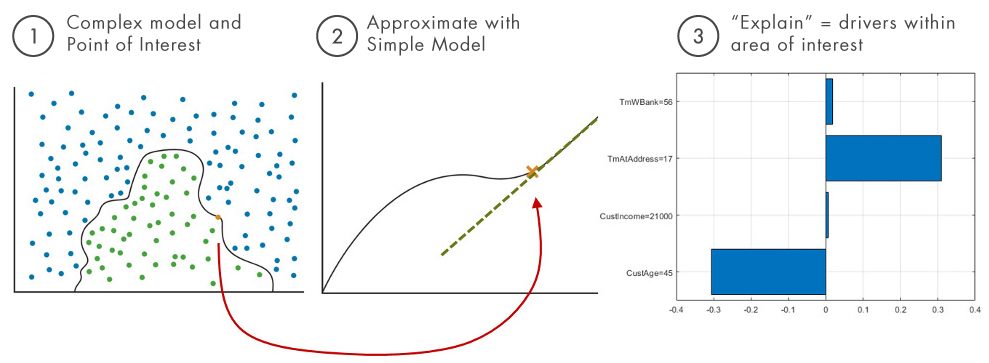
图2:如何获取本地可解释的模型 - 不可知的解释(石灰)。
部分依赖和个人有条件期望地块:通过在所有可能的特征值上平均模型的输出来检查一个或两个预测器对整体预测的影响
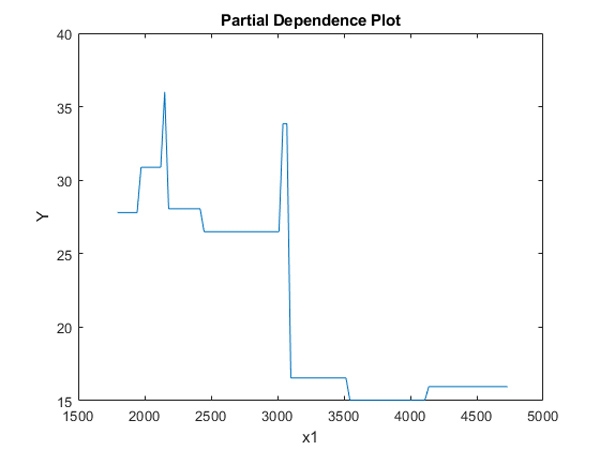
图3:显示X1是否高于或低于3000的部分依赖性图,这对预测产生了很大差异
您可以使用MATLAB为其他流行的可解释性方法,包括:
- 交换预测的重要性:查看测试或训练数据集上的模型预测错误,并洗牌预测器的值。对预测器的值进行洗牌所引起的误差变化的大小与预测器的重要性相对应。
- 福利价值:Shapley值源于合作博弈论,是特定特征对所有可能的“联盟”即特征组合的平均边际贡献。评估所有的特征组合通常需要很长的时间,因此在实践中,Shapley值是用蒙特卡罗模拟来近似的。
| 当地的 | 队列 | 全球 | |
| 解释: | 个人预测 | 对总体子集的行为建模 | 模型的行为“任何地方” |
| 用例 | 当个人预测出错时 预测似乎是反直观的 什么 - 如果分析 |
防止偏见 验证特定组的结果 |
演示模型如何工作 比较不同的部署模型 |
| 适用的解释性方法 | 酸橙 局部决策树 有条理的价值 |
数据子集上的全局方法 | PDP /冰 全球决策树 功能的重要性 |
可解释性方法有其自身的局限性。当您将这些算法应用于各种用例时,最好的实践是了解这些限制。可解释性工具可以帮助你理解为什么机器学习模型会做出预测,这是验证和验证人工智能应用的关键部分。认证机构目前正在研究一个为自动交通和医药等敏感应用的人工智能认证框架。
