神经网络(也称人工神经网络)是一种自适应系统,它通过类似人脑的分层结构,使用相互连接的节点或神经元进行学习。神经网络可以从数据中学习,因此可以训练它识别模式,对数据进行分类,并预测未来事件。
神经网络将输入分解成抽象层。例如,它可以像人类大脑一样,通过许多例子训练来识别语言或图像中的模式。它的行为是由其各个元素的连接方式以及这些连接的强度或权重来定义的。在训练过程中,这些权重会根据指定的学习规则自动调整,直到人工神经网络正确地执行所需的任务。
神经网络尤其适合执行模式识别在语音,视觉和控制系统中识别和分类对象或信号。它们还可用于执行时间序列预测和建模。
以下是一些人工神经网络如何使用的示例:
- 检测存在音频中的语音命令通过培训深入学习模式。
- 将一个图像的风格外观应用于第二种图像的场景内容神经风格转移。
- 将手写的日本字符转换为数字文本。
- 检测癌症通过指导病理学家在分类肿瘤中作为良性或恶性的良性或恶性,基于细胞大小,团块厚度,有丝分裂和其他因素的均匀性。


神经网络结合了多个处理层,使用并联操作的简单元件和由生物神经系统的启发。它由输入层,一个或多个隐藏层和输出层组成。在每层中,有几个节点或神经元,每个层使用前一层的输出作为其输入,所以神经元互连不同的层。每个神经元通常具有在学习过程中调节的权重,随着重量减少或增加,它会改变该神经元的信号的强度。

典型的神经网络架构。
分类
分类是一种监督机器学习,其中算法“学习”以从标记数据的示例对新的观测分类。
回归
回归模型描述一个响应(输出)变量和一个或多个预测(输入)变量之间的关系。
模式识别
模式识别是计算机视觉,雷达处理,语音识别和文本分类中的人工神经网络应用的重要组成部分。它通过将输入数据分类为基于关键功能,使用监督或无监督的分类对对象或类进行分类。
例如,在计算机视觉中,监督模式识别技术用于光学字符识别(OCR),面部检测,面部识别,对象检测和对象分类。在图像处理和计算机视觉中,无监督的模式识别技术用于对象检测和图像分割。
无人监督的学习
无监督的神经网络通过让神经网络不断调整自己以适应新的输入来训练。它们被用来从没有标记响应的输入数据组成的数据集中得出推论。您可以使用它们来发现数据中的自然分布、类别和类别关系。
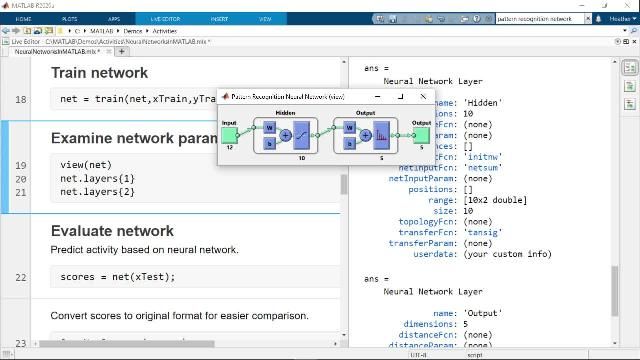
聚类
聚类是一种无监督的学习方法,其中人工神经网络可用于探索数据分析,以查找数据中的隐藏模式或分组。此过程涉及通过相似性对数据进行分组。应用程序聚类分析包括基因序列分析,市场研究和对象识别。
使用工具和功能来管理大数据集,马铃薯®提供专门的工具箱,用于使用机器学习,人工神经网络,深度学习,计算机视觉和自动驾驶。
只需几行代码,MATLAB就可以让您开发神经网络,而无需成为专家。快速入门,创建并可视化模型,并将模型部署到服务器和嵌入式设备。
使用MATLAB,您可以将结果集成到现有的应用程序中。MATLAB自动部署在企业系统,集群,云和嵌入式设备上的人工神经网络模型。
典型的神经网络设计流程
每个神经网络应用程序都是唯一的,但开发网络通常遵循以下步骤:
- 获取并准备您的数据
- 创建人工神经网络
- 配置网络的输入和输出
- 调整网络参数(权重和偏见)以优化性能
- 训练网络
- 验证网络的结果
- 将网络集成到生产系统中
浅网络的分类和聚类
Matlab和Deep Learing Toolbox提供用于创建,培训和模拟浅神经网络的命令行功能和应用程序。该应用程序可以轻松开发神经网络,以实现分类,回归(包括时间序列回归)和聚类。在这些工具中创建网络后,您可以自动生成MATLAB代码以捕获您的工作和自动化任务。
预处理,后处理和改进网络
预处理网络输入和目标提高了浅层神经网络训练的效率。后处理能够详细分析网络性能。matlab和金宝app®提供帮助您的工具:
- 使用主成分分析减少输入向量的尺寸
- 在网络响应和相应的目标之间执行回归分析
- 缩放输入和目标使它们落在范围内[-1,1]
- 对训练数据集的均值和标准差进行归一化
- 创建网络时使用自动数据预处理和数据分部
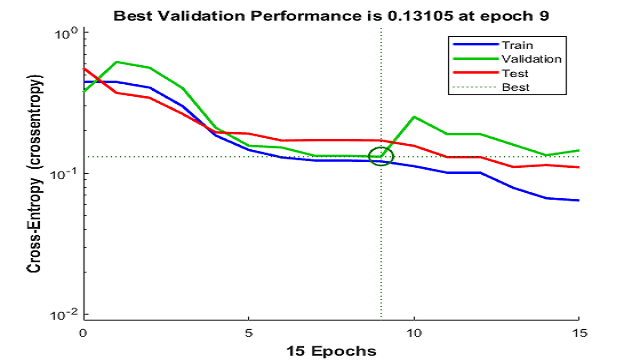
提高网络泛化的能力有助于防止过度装备,是人工神经网络设计中的常见问题。当网络存储训练集时,会发生过度装备,但尚未学会概括为新输入。过度装箱在训练集上产生相对较小的错误,但在向网络呈现新数据时,更大的错误。了解有关你的方式使用交叉验证以避免过度装备。
改善泛化金宝搏官方网站的两个解决方案包括:
- 正则化修改网络的性能函数(培训过程最小化的错误措施)。通过包括权重和偏差的大小,正规化产生与训练数据很好的网络,并且当呈现新数据时表现出更平滑的行为。
- 早期停止使用两个不同的数据集:培训集,更新权重和偏置,以及验证集,以停止培训网络开始过度提供数据

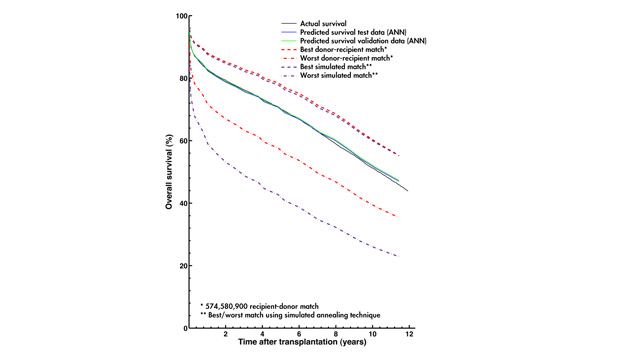
用于分析网络性能的后处理图,包括连续训练时期(左上角),错误直方图(右上角)和混淆矩阵(底部)的均方误差验证性能,用于训练,验证和测试阶段。
应用使用神经网络







30天免费试用

问题?
您还可以从以下列表中选择一个网站: