강화학습은컴퓨터에이전트가역동적인환경에서반복적인시행착오상호작용을통해작업수행방법을학습하는머신러닝기법의한유형입니다。이학습접근법을통해에이전트는인간개입또는작업수행을위한명시적인프로그래밍없이작업에대한보상메트릭을최대화하는결정을내릴수있습니다。
강화학습으로교육된AI프로그램은바둑과체스뿐만아니라비디오게임에서도사람을상대로승리했습니다。강화학습은새로운개념이아니지만최근딥러닝및계산능력의발전으로인해인공지능분야에서매우뛰어난성과를거뒀습니다。
강화학습,머신러닝및딥러닝
강화학습은머신러닝의한부류입니다(그림1)。비지도및지도머신러닝과다르게강화학습은정적데이터셋에의존하는것이아니라역동적인환경에서동작하며수집된경험으로부터학습합니다。데이터점또는경험은훈련하는동안환경과소프트웨어에이전트간의시행착오상호작용을통해수집됩니다。강화학습의이런점은지도및비지도머신러닝에서는필요한훈련전데이터수집,전처리및레이블지정에대한필요성을해소하기때문에중요합니다。이는실질적으로적절한인센티브가주어지면강화학습모델은인간의개입없이학습행동을자체적으로시작할수있다는것을의미합니다。
3딥러닝은가지머신러닝모두를포함합니다。강화학습과딥러닝은상호배타적이지않습니다。복잡한강화학습문제는주로심층강화학습이라고알려진분야인심층신경망에의존합니다。
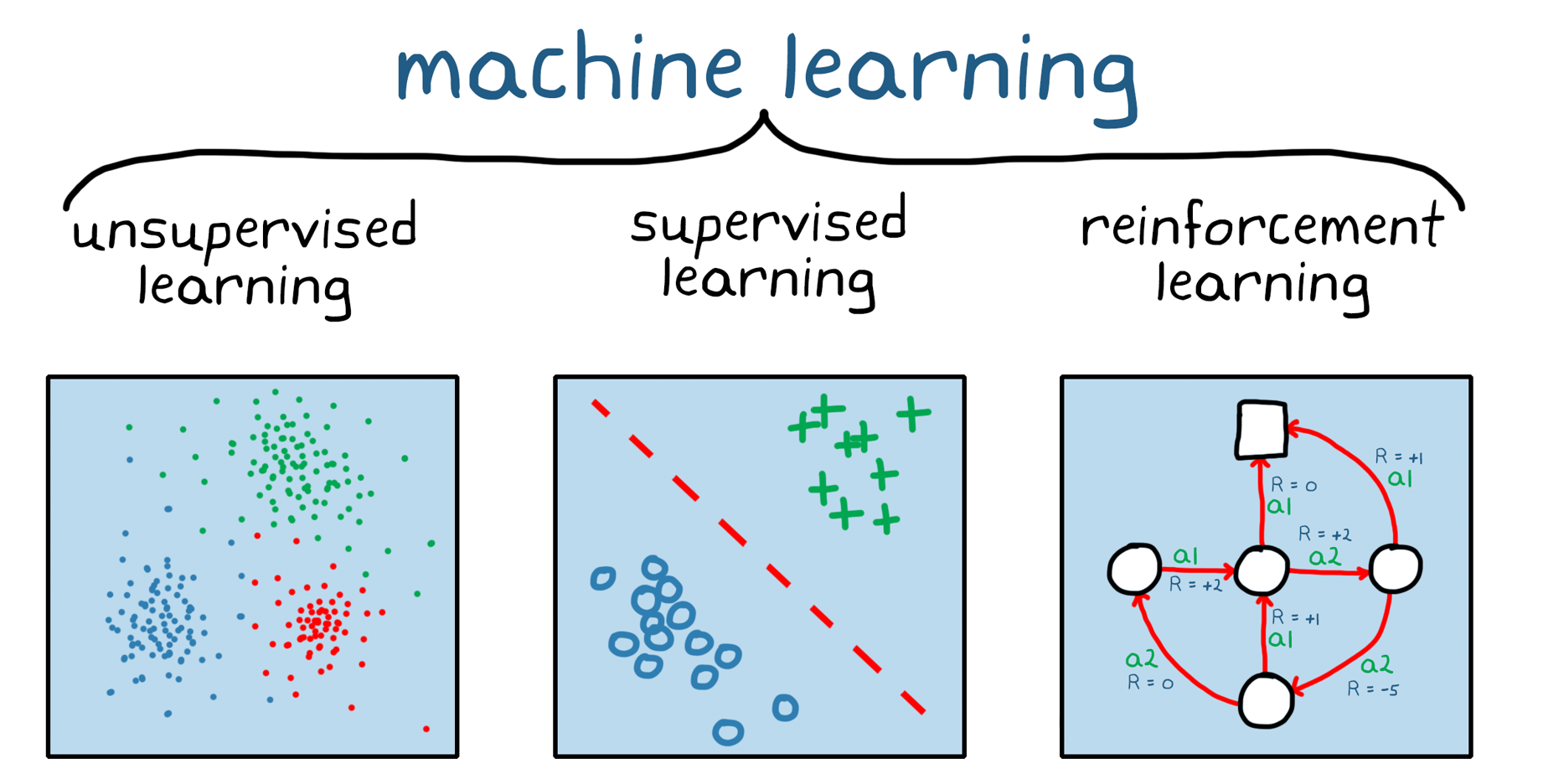
그림1。세가지머신러닝:비지도학습,지도학습및강화학습。



강화학습응용분야의예
강화학습으로훈련된심층신경망은복잡한행동을표현할수있습니다。이를통해기존방법으로는해결하기매우까다롭거나다루기어려운응용분야에대안적인방식으로접근할수있습니다。예를들어,자율주행에서신경망은운전자를대신하여카메라프레임,라이다측정값등다양한센서를동시에살펴보고핸들을어떻게돌릴지결정할수있습니다。신경망이없었다면이문제는카메라프레임에서특징추출,라이다측정값필터링,센서출력값통합,센서출력값을기반으로”주행”결정내리기등의여러개의작은문제들로세분화됐을것입니다。
생산시스템에서의강화학습은아직증명이되지않은접근법이지만일부산업응용분야는강화학습을활용하기좋은조건을갖추고있습니다。
고급제어:비선형시스템을제어하는것은매우까다로운문제로서이는주로다양한동작점에서시스템을선형화하여해결합니다。강화학습은비선형시스템에바로적용할수있습니다。
자율주행:카메라입력값을기반으로주행결정을내리는이분야는심층신경망이이미지응용분야에서거둔성공을고려하면강화학습에잘맞는분야입니다。
로봇공학:강화학습은픽앤플레이스응용분야에서로봇팔로다양한사물을다루는방법을학습시키는등로봇파지와같은응용분야에서사용될수있습니다。다른로봇공학응용분야로는인간-로봇,로봇-로봇협업이있습니다。
스케줄링:스케줄링문제는신호등제어,특정목표를위해공장현장의리소스편성등다양한시나리오에존재합니다。강화학습은이와같은조합최적화문제해결에있어진화적방법을대체할수있는좋은수단입니다。
보정: ECU(电子控制单元)보정과같이파라미터의수동보정이필요한응용분야는강화학습을활용하기좋은조건을갖추고있습니다。
강화학습의훈련메커니즘은다양한실제시나리오를반영합니다。긍정강화를통한반려동물훈련을예시로들어보겠습니다。

그림2。강아지훈련의강화학습。
강화학습용어(그림2)를사용해서설명하자면이사례의학습목표는강아지(에이전트)가강아지를둘러싼환경과훈련사를포함한환경에서행동을완료하도록강아지를훈련하는것입니다。먼저훈련사가강아지에게명령또는신호를보내고강아지는이를관찰합니다(관측값)。그런다음강아지는행동을취하여응답합니다。취한행동이원하는행동과근접한경우훈련사는간식또는장난감과같은보상을제공할것입니다。그렇지않다면보상이제공되지않습니다。훈련초반에강아지는특정관측값을행동및보상과연관짓기위해서”앉”아라는명령에구르는등무작위행동을더많이취할것입니다。이러한관측값과행동사이의연관성또는매핑을정책이라고합니다。강아지의관점에서최적의시나리오는모든신호에올바르게응답하여최대한많은간식을획득하는것입니다。즉,강화학습훈련의의미는강아지가보상을최대화하는목표행동을배울수있도록강아지의정책을”조”정하는데있습니다。훈련이완료되면강아지는자신이개발한내부정책을사용하여보호자의”앉”아라는명령을관찰하고적절한행동을취할수있게됩니다。 이 시점에는 간식이 제공되면 좋지만 필수적이지 않습니다.
강아지훈련예시를떠올리면서자율주행시스템을사용한자동차주차작업의예시를살펴보겠습니다(그림3)。목표는강화학습을활용하여자동차컴퓨터(에이전트)에게올바른주차위치에주차하도록가르치는것입니다。강아지훈련사례와동일하게환경은에이전트를제외한모든것을의미하며차량의동특성,근처에있는다른차량,날씨등이포함될수있습니다。훈련동안에이전트는카메라,GPS및라이다등센서의판독값(관측값)을사용하여운전,제동및가속명령(행동)을생성합니다。관측값으로부터올바른행동을생성하는방법을학습(정책조)정하기위해에이전트는시행착오절차를통해차량의주차를반복해서시도합니다。시행의적합성을평가하고학습과정을인도하기위해보상신호가제공될수있습니다。

그림3。자율주차의강화학습。
강아지훈련예시에서훈련은강아지뇌속에서이뤄졌습니다。자율주행예시에서는훈련알고리즘이훈련을담당합니다。훈련알고리즘은수집된센서판독값,행동및보상을기반으로에이전트의정책조정을책임집니다。훈련이완료되면차량의컴퓨터는조정된정책과센서판독값으로만주차를할수있습니다。
유념해야될점은강화학습은샘플효율적이지않다는점입니다。이는훈련을위한데이터를수집하려면에이전트와환경사이에수많은상호작용이필요하다는것을의미합니다。예를들어세계바둑챔피언을상대로승리한최초의컴퓨터프로그램인AlphaGo는며칠동안쉬지않고훈련하여수백만판의대국을둬서수천년간의인간지식을축적하였습니다。비교적간단한응용분야에대해서도훈련시간은몇분에서몇시간,며칠까지소요됩니다。또한내려야할수많은설계결정이있는데이런모든결정을올바르게내리기위해서는몇번의시도가필요할수도있기때문에문제를제대로설정하는것또한까다로울수있습니다。이런결정에는적절한신경망아키텍처선,택하이퍼파라미터조정및보상신호형성등이있습니다。
강화학습워크플로
강화학습을사용한에이전트훈련의일반적인워크플로는다음과같은단계를포함합니다(그림4)。

그림4。강화학습워크플로。
1.환경생성
먼저에이전트와환경간인터페이스등의강화학습에이전트가운영될환경을정의해야합니다。이환경은시뮬레이션모델또는실제물리적시스템일수있으나더욱안전하고실험이가능한시뮬레이션환경이일반적으로더좋은첫단계입니다。
2.보상정의
다음으로에이전트가성과를작업목표와비교하기위해사용할보상신호및이신호를환경으로부터계산하는방법을명시해야합니다。보상을형성하는것은까다로운작업이며올바르게설정하기위해몇번의시도가필요할수도있습니다。
3.에이전트생성
그런다음정책과강화학습훈련알고리즘으로구성된에이전트를생성합니다。그러기위해선다음을완료해야합니다。
一)정책을나타낼방법선택(신경망또는룩업테이블사용등)。
b)적절한훈련알고리즘선택。각각의표현방식은대개각각의특정훈련알고리즘의범주와연결되어있습니다。그러나일반적으로대부분의최신강화학습알고리즘은대규모상태/행동공간및복잡한문제에적합한신경망에의존합니다。
4.에이전트훈련및검증
훈련옵션(중지기준등)을설정하고에이전트를훈련해정책을조정합니다。훈련이종료된후에는훈련된정책을꼭검증하여야합니다。필요에따라보상신호및정책아키텍처등의설계선택을다시검토하고재훈련합니다。강화학습은일반적으로샘플비효율적으로알려져있습니다。훈련은응용분야에따라몇분에서며칠까지소요됩니다。복잡한응용분야의경우여러CPU、GPU및컴퓨터클러스터에서훈련을병렬처리하여가속할수있습니다(그림5)。
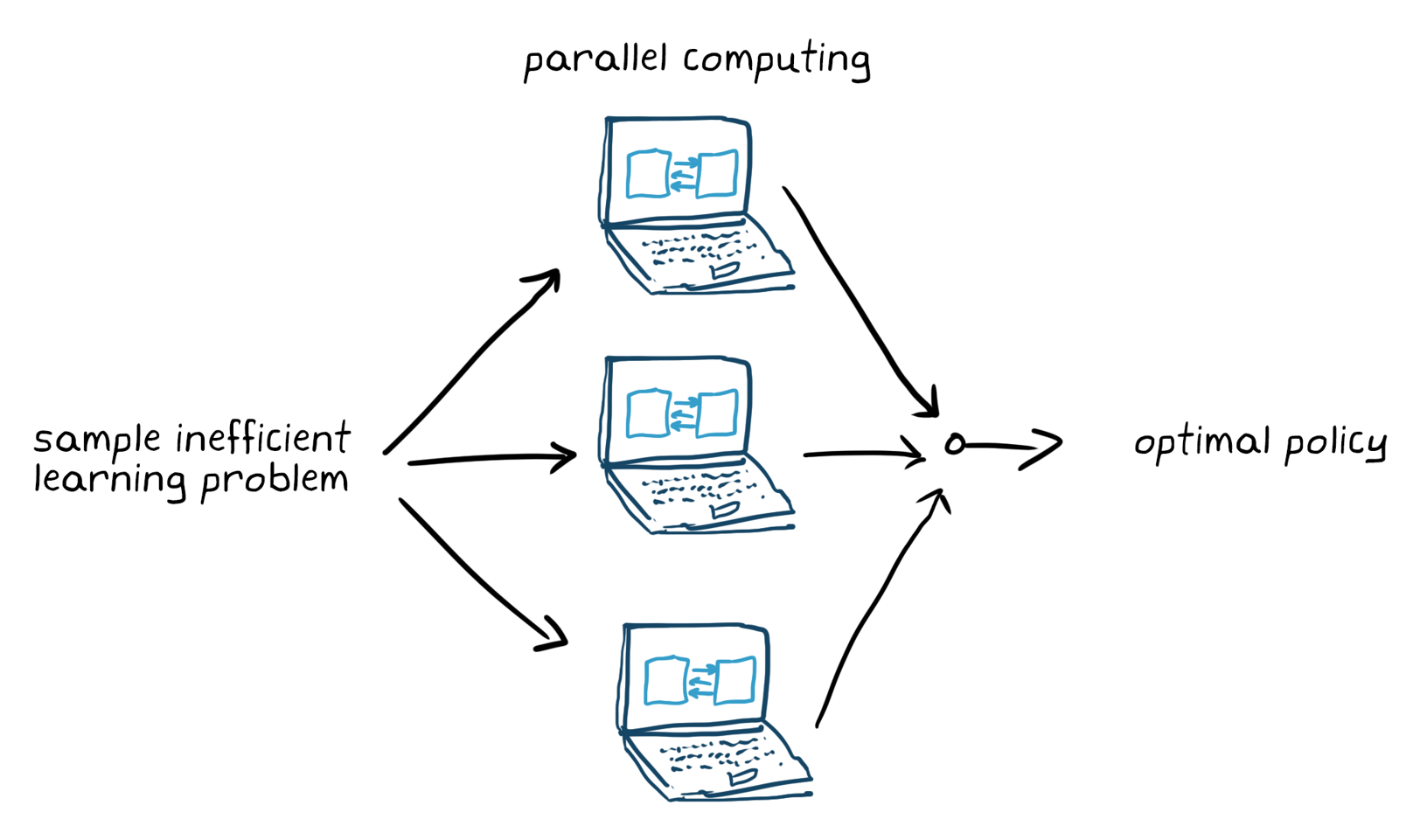
그림5。병렬연산으로샘플비효율적인학습문제훈련。
5.정책배포
훈련된정책표현을C / c++또는CUDA코드로생성하여배포합니다。이시점에서정책은독립된의사결정시스템입니다。
강화학습을사용하여에이전트를훈련하는절차는반복적인과정입니다。추후단계의결정및결과로인해학습워크플로의이전단계로다시돌아와야할수있습니다。예를들어훈련과정에서합리적인시간안에최적의정책으로수렴하지않는경우에이전트를재훈련하기전에다음과같은사항을업데이트해야할수있습니다。
- 훈련설정
- 강화학습알고리즘구성
- 정책표현
- 보상신호정의
- 행동및관측값신호
- 환경동특성
MATLAB®및强化学习工具箱™는강화학습작업을간소화합니다。강화학습워크플로의모든단계를거치면로봇및자율주행과같은복잡한시스템을위한컨트롤러및의사결정알고리즘을구현할수있습니다。구체적으로다음과같은단계를수행할수있습니다。
1.MATLAB및仿真金宝app软件®를사용하여환경및보상함수생성
2.심층신경망,다항식,룩업테이블을사용하여강화학습정책정의
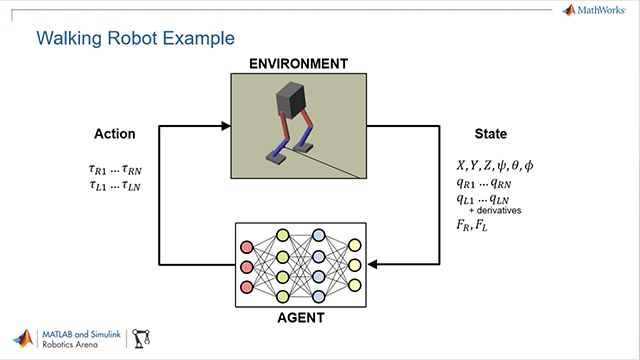
그림6。强化学习工具箱™로이족보행로봇에게보행가르치기
3.약간의코드변경만으로DQN, DDPG, PPO및囊와같은널리쓰이는강화학습알고리즘을전환,평가및비교또는나만의사용자지정알고리즘생성
4.并行计算工具箱™및MATLAB并行服务器™를사용해여러GPU、CPU컴퓨터클러스터및클라우드리소스를활용하여강화학습정책을더욱빠르게훈련
5.MATLAB编码器™및GPU编码器™를통해코드를생성하고임베디드기기로강화학습정책배포
6.참조예제를사용하여강화학습시작
강화학습에대해자세히알아보기







30일무료평가판

관련문의
你也可以从以下列表中选择一个网站: