이번역페이지는최신내용을담고있지않습니다。최신내용을영문으로보려면여기를클릭하십시오。
생성적적대신경망(GAN)훈련시키기
이예제에서는생성적적대신경망을훈련시켜서영상을생성하는방법을보여줍니다。
생성적적대신경망(GAN)은입력값인실제데이터와비슷한특징을갖는데이터를생성할수있는딥러닝신경망의한종류입니다。
氮化镓은함께훈련되는다음과같은두개의신경망으로구성됩니다。
생성기-입력값으로난수로구성된벡터(잠재입력값)가주어지면이신경망은훈련데이터와동일한구조를갖는데이터를생성합니다。
판별기-두훈련데이터의관측값을포함하는데이터의배치(批)와생성기에서생성된데이터가주어지면이신경망은관측값을
“真正的”과“生成”로분류하려고시도합니다。

氮化镓을훈련시키려면두신경망의성능을극대화할수있도록다음과같이두신경망을동시에훈련시키십시오。
판별기를”속이”는데이터를생성하도록생성기를훈련시킵니다。
실제데이터와생성된데이터를구분하도록판별기를훈련시킵니다。
생성기의성능을최적화하려면,생성된데이터가주어졌을때의판별기손실을최대화하십시오。즉,생성기의목적은판별기가“真正的”로분류하는데이터를생성하는것입니다。
판별기의성능을최적화하려면,실제데이터의배치와생성된데이터의배치가둘다주어졌을때의판별기손실을최소화하십시오。즉,판별기의목적은생성기에”속”지않는것입니다。
이상적으로는이전략의결과로실제처럼보이는그럴싸한데이터를생성하는생성기와훈련데이터의특징인강한특징표현을학습한판별기가생성됩니다。
훈련데이터불러오기
花데이터세트[1]를다운로드하여추출합니다。
url =“http://download.tensorflow.org/example_images/flower_photos.tgz”;downloadFolder = tempdir;文件名= fullfile (downloadFolder,“flower_dataset.tgz”);imageFolder = fullfile (downloadFolder,“flower_photos”);如果~存在(imageFolder“dir”) disp (下载花卉数据集(218mb)…) websave(文件名,url);解压(文件名,downloadFolder)结束
꽃사진을포함하는영상데이터저장소를만듭니다。
datasetFolder = fullfile (imageFolder);imd = imageDatastore (datasetFolder,...“IncludeSubfolders”,真正的);
무작위가로뒤집기를포함하도록데이터를증대하고,영상의크기가64×64가되도록크기를조정합니다。
增量= imageDataAugmenter (“RandXReflection”,真正的);augimds = augmentedImageDatastore([64 64],imds,“DataAugmentation”、增压器);
생성기신경망정의하기
100年크기가인확률벡터에서영상을생성하는다음과같은신경망아키텍처를정의합니다。

이신경망은다음을수행합니다。
사영및형태변경계층을사용하여,크기인가100확률벡터를7×7×128배열로변환합니다。
일련의전치된컨벌루션계층,배치정규화계층,ReLU계층을사용하여,결과로생성된배열을64×64×3배열로업스케일링합니다。
이신경망아키텍처를계층그래프로정의하고다음과같은신경망속성을지정합니다。
전치된컨벌루션계층에대해,각계층에대한내림차순개수의필터로구성된5×5필터를지정하고,스트라이드로를2지정하고,각가장자리에서출력값의자르기를지정합니다。
전치된마지막컨벌루션계층에대해,생성된영상의RGB채널3개에대응되는3개의5×5필터를지정하고,출력값크기를직전계층의크기로지정합니다。
신경망끝부분에双曲正切계층을삽입합니다。
잡음입력값을사영및형태변경하려면사용자지정계층projectAndReshapeLayer를사용하십시오。이계층은이예제의마지막부분에지원파일로첨부되어있습니다。projectAndReshapeLayer객체는완전연결연산을사용하여입력값을업스케일링하고출력값을지정된크기로형태변경합니다。
filterSize = 5;numFilters = 64;numLatentInputs = 100;projectionSize = [4 4 512];layersGenerator = [featureInputLayer(numLatentInputs,“名字”,“在”) projectAndReshapeLayer (projectionSize numLatentInputs,“名字”,“项目”);transposedConv2dLayer (filterSize 4 * numFilters,“名字”,“tconv1”) batchNormalizationLayer (“名字”,“bnorm1”) reluLayer (“名字”,“relu1”) transposedConv2dLayer (2 * numFilters filterSize,“步”,2,“种植”,“相同”,“名字”,“tconv2”) batchNormalizationLayer (“名字”,“bnorm2”) reluLayer (“名字”,“relu2”) transposedConv2dLayer (filterSize numFilters,“步”,2,“种植”,“相同”,“名字”,“tconv3”) batchNormalizationLayer (“名字”,“bnorm3”) reluLayer (“名字”,“relu3”) transposedConv2dLayer (filterSize 3“步”,2,“种植”,“相同”,“名字”,“tconv4”) tanhLayer (“名字”,的双曲正切));lgraphGenerator = layerGraph (layersGenerator);
사용자지정훈련루프를사용하여신경망을훈련시키고자동미분을활성화하려면계층그래프를dlnetwork객체로변환하십시오。
dlnetGenerator = dlnetwork (lgraphGenerator);
판별기신경망정의하기
실제및생성된64×64영상을분류하는다음과같은신경망을정의합니다。

64×64×3영상을받아서일련의컨벌루션계층,배치정규화계층,漏ReLU계층을사용하여스칼라예측점수를반환하는신경망을만듭니다。드롭아웃을사용하여입력영상에잡음을추가합니다。
드롭아웃계층에대해,드롭아웃확률을0.5로지정합니다。
컨벌루션계층에대해,각계층에대한오름차순개수의필터로구성된5×5필터를지정합니다。스트라이드로를2지정하고출력값의채우기를지정합니다。
漏水的ReLU계층에대해,스케일을0.2로지정합니다。
마지막계층에대해,하나의4×4필터를갖는컨벌루션계층을지정합니다。
[0, 1]범위의확률로출력하기위해예제의모델기울기함수섹션에있는modelGradients함수의乙状结肠함수를사용합니다。
dropoutProb = 0.5;numFilters = 64;规模= 0.2;inputSize = [64 64 3];filterSize = 5;layersDiscriminator = [imageInputLayer(inputSize,“归一化”,“没有”,“名字”,“在”) dropoutLayer (dropoutProb“名字”,“辍学”) convolution2dLayer (filterSize numFilters,“步”,2,“填充”,“相同”,“名字”,“conv1”) leakyReluLayer(规模、“名字”,“lrelu1”) convolution2dLayer (2 * numFilters filterSize,“步”,2,“填充”,“相同”,“名字”,“conv2”) batchNormalizationLayer (“名字”,“bn2”) leakyReluLayer(规模、“名字”,“lrelu2”) convolution2dLayer (filterSize 4 * numFilters,“步”,2,“填充”,“相同”,“名字”,“conv3”) batchNormalizationLayer (“名字”,“bn3”) leakyReluLayer(规模、“名字”,“lrelu3”) convolution2dLayer (filterSize 8 * numFilters,“步”,2,“填充”,“相同”,“名字”,“conv4”) batchNormalizationLayer (“名字”,“bn4”) leakyReluLayer(规模、“名字”,“lrelu4”1) convolution2dLayer(4日,“名字”,“conv5”));lgraphDiscriminator = layerGraph (layersDiscriminator);
사용자지정훈련루프를사용하여신경망을훈련시키고자동미분을활성화하려면계층그래프를dlnetwork객체로변환하십시오。
dlnetDiscriminator = dlnetwork (lgraphDiscriminator);
모델기울기와손실함수정의하기
이예제의모델기울기함수섹션에나와있는함수modelGradients를만듭니다。이함수는생성기신경망과판별기신경망,입력데이터로구성된미니배치,난수값으로구성된배열과뒤집기인자를입력값으로받습니다。그런다음신경망의학습가능한파라미터에대한손실의기울기와두신경망의점수를반환합니다。
훈련옵션지정하기
128年时代500회에대해크기가인미니배치를사용하여훈련시킵니다。크기가큰데이터세트의경우에는이렇게많은时代횟수만큼훈련하지않아도될수있습니다。
numEpochs = 500;miniBatchSize = 128;
亚当최적화에대한옵션을지정합니다。두신경망에대해다음을지정합니다。
학습률0.0002
기울기감쇠인자0.5
제곱기울기감쇠인자0.999
learnRate = 0.0002;gradientDecayFactor = 0.5;squaredGradientDecayFactor = 0.999;
판별기가실제영상과생성된영상을구분하는방법을지나치게빨리학습하는경우생성기훈련이실패할수있습니다。판별기와생성기의학습균형을맞추려면레이블을무작위로뒤집어서실제데이터에잡음을추가하십시오。
flipFactor0.3값을으로지정하여실제레이블의30%(총레이블의15%)를뒤집습니다。그러나생성된모든영상에는여전히올바른레이블이적용되어있으므로이로인해생성기의성능이저하되지는않습니다。
flipFactor = 0.3;
100회의반복마다,생성된검증영상을표시합니다。
validationFrequency = 100;
모델훈련시키기
minibatchqueue를사용하여영상미니배치를처리하고관리합니다。각미니배치에대해다음을수행합니다。
(이예제의마지막부분에서정의되는)사용자지정미니배치전처리함수
preprocessMiniBatch를사용하여영상을[1]범위로다시스케일링합니다。128개관측값이미만인부분미니배치를모두무시합니다。
각각공간(空间),공간(空间),채널(频道),배치(批)를뜻하는차원레이블
“SSCB”를사용하여영상데이터의형식을지정합니다。기본적으로minibatchqueue객체는기본유형单을사용하여데이터를dlarray객체로변환합니다。사용가능GPU한가있으면GPU에서훈련시킵니다。
minibatchqueue의“OutputEnvironment”옵션이“汽车”이면minibatchqueue는GPU를사용할수있는경우각출력값을gpuArray로변환합니다。GPU를사용하려면并行计算工具箱™와计算能力3.0이상의CUDA®지원NVIDIA GPU®가필요합니다。
augimds。MiniBatchSize = MiniBatchSize;executionEnvironment =“汽车”;兆贝可= minibatchqueue (augimds,...“MiniBatchSize”miniBatchSize,...“PartialMiniBatch”,“丢弃”,...“MiniBatchFcn”@preprocessMiniBatch,...“MiniBatchFormat”,“SSCB”,...“OutputEnvironment”, executionEnvironment);
사용자지정훈련루프를사용하여모델을훈련시킵니다。루프를사용해훈련데이터를순회하고각반복에서신경망파라미터를업데이트합니다。훈련진행상황을모니터링하려면,생성기에입력할,난수값으로구성된홀드아웃배열을사용하여생성된영상배치를표시하고,점수플롯도표시하십시오。
亚当에대한파라미터를초기화합니다。
trailingAvgGenerator = [];trailingAvgSqGenerator = [];trailingAvgDiscriminator = [];trailingAvgSqDiscriminator = [];
훈련진행상황을모니터링하려면,생성기에입력된,고정확률벡터의홀드아웃배치를사용하여생성된영상배치를표시하고,신경망점수도플로팅하십시오。
홀드아웃난수값으로구성된배열을만듭니다。
numValidationImages = 25;ZValidation = randn (numLatentInputs numValidationImages,“单一”);
데이터를dlarray객체로변환하고각각채널(频道),배치(批)를뜻하는차원레이블“CB”를지정합니다。
dlZValidation = dlarray (ZValidation,“CB”);
GPU훈련을위해데이터를gpuArray객체로변환합니다。
如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”dlZValidation = gpuArray (dlZValidation);结束
훈련진행상황플롯을초기화합니다。图를만들고너비가두배가되도록크기를조정합니다。
f =图;f.Position (3) = 2 * f.Position (3);
생성된영상과신경망점수를표시할서브플롯을만듭니다。
imageAxes =情节(1、2、1);scoreAxes =情节(1、2、2);
점수플롯에대해애니메이션선을초기화합니다。
lineScoreGenerator = animatedline (scoreAxes,“颜色”0.447 - 0.741 [0]);lineScoreDiscriminator = animatedline (scoreAxes,“颜色”, [0.85 0.325 0.098]);传奇(“发电机”,鉴频器的);ylim([0 1])包含(“迭代”) ylabel (“分数”网格)在
氮化镓을훈련시킵니다。각时代에대해,데이터저장소를섞고루프를사용해데이터의미니배치를순회합니다。
각미니배치에대해다음을수행합니다。
dlfeval과modelGradients함수를사용하여모델기울기를평가합니다。adamupdate함수를사용하여신경망파라미터를업데이트합니다。두신경망의점수를플로팅합니다。
validationFrequency회의반복마다,고정된홀드아웃생성기입력값에대해생성된영상배치를표시합니다。
훈련을실행하는데다소시간이걸릴수있습니다。
迭代= 0;开始=抽搐;%循环纪元。为时代= 1:numEpochs重置和洗牌数据存储。洗牌(兆贝可);%循环小批。而Hasdata (mbq) iteration = iteration + 1;%读取小批数据。dlX =下一个(兆贝可);为发电机网络产生潜在的输入。转换为% dlarray,并指定尺寸标签'CB'(通道,批次)。%如果在GPU上训练,则将潜在输入转换为gpuArray。Z = randn (numLatentInputs miniBatchSize,“单一”);dlZ = dlarray (Z,“CB”);如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”dlZ = gpuArray (dlZ);结束%评估模型梯度和生成器状态使用的% dlfeval和模型梯度函数%的例子。[gradientsGenerator, gradientsDiscriminator, stateGenerator, scoreGenerator, scoreDiscriminator] =...dlfeval(@modelGradients, dlnetGenerator, dlnetDiscriminator, dlX, dlZ, flipFactor);dlnetGenerator。状态= stateGenerator;%更新标识器网络参数。[dlnetDiscriminator, trailingAvgDiscriminator trailingAvgSqDiscriminator] =...adamupdate (dlnetDiscriminator gradientsDiscriminator,...trailingAvgDiscriminator trailingAvgSqDiscriminator,迭代,...learnRate、gradientDecayFactor squaredGradientDecayFactor);%更新生成器网络参数。[dlnetGenerator, trailingAvgGenerator trailingAvgSqGenerator] =...adamupdate (dlnetGenerator gradientsGenerator,...trailingAvgGenerator trailingAvgSqGenerator,迭代,...learnRate、gradientDecayFactor squaredGradientDecayFactor);%每次validationFrequency迭代,使用%保留发电机输入。如果mod(iteration,validationFrequency) == 0 || iteration == 1%生成图像使用保留发生器输入。dlXGeneratedValidation =预测(dlnetGenerator dlZValidation);在[0 1]范围内平铺并重新缩放图像。我= imtile (extractdata (dlXGeneratedValidation));I =重新调节(我);%显示图像。次要情节(1、2、1);图像(imageAxes,我)xticklabels ([]);yticklabels ([]);标题(“生成的图像”);结束%更新分数图。次要情节(1、2、2)addpoints (lineScoreGenerator,迭代,...双(收集(extractdata (scoreGenerator))));addpoints (lineScoreDiscriminator迭代,...双(收集(extractdata (scoreDiscriminator))));%用培训进度信息更新标题。D =持续时间(0,0,toc(开始),“格式”,“hh: mm: ss”);标题(...”时代:“+时代+", "+...“迭代:“+迭代+", "+...”经过:“+ drawnow字符串(D))结束结束
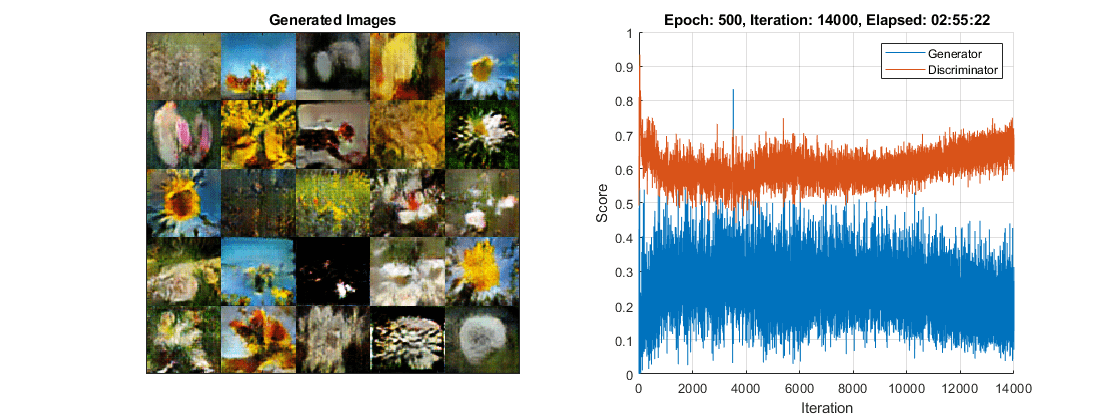
여기서,판별기는생성된영상중에서실제영상을식별하는강한특징표현을학습했습니다。생성기는훈련데이터와유사한영상을생성할수있는,마찬가지로강한특징표현을학습했습니다。
훈련플롯에생성기신경망과판별기신경망의점수가나와있습니다。신경망점수를해석하는방법에대한자세한내용은监控GAN培训进度,识别常见故障模式항목을참조하십시오。
새영상생성하기
새영상을생성하려면,预测함수를확률벡터배치를포함하는dlarray객체와함께생성기에사용하십시오。영상을함께표시하려면imtile함수를사용하고,重新调节함수를사용하여영상을다시스케일링하십시오。
생성기신경망에입력할,25개의확률벡터배치를포함하는dlarray객체를만듭니다。
numObservations = 25;ZNew = randn (numLatentInputs numObservations,“单一”);dlZNew = dlarray (ZNew,“CB”);
GPU를사용하여영상을생성하려면데이터를gpuArray객체로도변환하십시오。
如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”dlZNew = gpuArray (dlZNew);结束
생성기및입력데이터와함께预测함수를사용하여새영상을생성합니다。
dlXGeneratedNew =预测(dlnetGenerator dlZNew);
영상을표시합니다。
我= imtile (extractdata (dlXGeneratedNew));I =重新调节(我);数字图像(I)轴从标题(“生成的图像”)

모델기울기함수
함수modelGradients는생성기및판별기dlnetwork객체dlnetGenerator와dlnetDiscriminator,입력데이터로구성된미니배치dlX,난수값으로구성된배열dlZ,뒤집을실제레이블의백분율flipFactor를입력값으로받습니다。그런다음신경망의학습가능한파라미터에대한손실의기울기,생성기상태,두신경망의점수를반환합니다。판별기출력값이[0,1]범위에있지않으므로modelGradients함수는乙状结肠함수를적용하여출력값을확률로변환합니다。
函数[gradientsGenerator, gradientsDiscriminator, stateGenerator, scoreGenerator, scoreDiscriminator] =...模型梯度(dlnetGenerator, dlnetDiscriminator, dlX, dlZ, flipFactor)%用鉴别器网络计算真实数据的预测。dlYPred = forward(dlnetDiscriminator, dlX);%用鉴别器网络计算生成数据的预测。向前(dlXGenerated stateGenerator] = (dlnetGenerator, dlZ);dlYPredGenerated = forward(dlnetDiscriminator, dlXGenerated);%将鉴别器输出转换为概率。probGenerated =乙状结肠(dlYPredGenerated);probReal =乙状结肠(dlYPred);%计算鉴别器的得分。scoreDiscriminator = (mean(probReal) + mean(1-probGenerated)) / 2;%计算生成器的得分。scoreGenerator =意味着(probGenerated);%随机翻转真实图像的一部分标签。numObservations =大小(probReal 4);idx = randperm(numObservations,floor(flipFactor * numObservations));%翻转标签。proreal (:,:,:,idx) = 1 - proreal (:,:,:,idx);%计算氮化镓损耗。[lossGenerator, lossDiscriminator] = ganLoss(probReal,probGenerated);%对于每个网络,计算相对于损失的梯度。gradientsGenerator = dlgradient(lossGenerator, dlnetGenerator。可学的,“RetainData”,真正的);gradientsDiscriminator = dlgradient(lossDiscriminator, dlnetDiscriminator.Learnables);结束
氮化镓손실함수와점수
생성기의목적은판별기가“真正的”로분류하는데이터를생성하는것입니다。생성기에서나온영상이판별기에의해실제영상으로분류될확률을극대화하려면음의로그가능도함수를최소화하십시오。
판별기의출력값 가주어진경우:
는입력영상이클래스
“真正的”에속할확률입니다。은입력영상이클래스
“生成”에속할확률입니다。
시그모이드연산
는modelGradients함수에서수행됩니다。생성기에대한손실함수는다음과같이지정됩니다。
여기서 는생성된영상에대한판별기출력확률을포함합니다。
판별기의목적은생성기에”속”지않는것입니다。판별기가실제영상과생성된영상을성공적으로판별해낼확률을극대화하려면해당하는음의로그가능도함수합을최소화하십시오。
판별기에대한손실함수는다음과같이지정됩니다。
여기서 은실제영상에대한판별기출력확률을포함합니다。
생성기와판별기가각각의목표를얼마나잘달성하는지0를부터1까지의척도로측정하기위해점수개념을사용할수있습니다。
생성기점수는생성된영상에대한판별기출력값에대응되는확률의평균입니다。
판별기점수는실제영상과생성된영상에대한판별기출력값에대응되는확률의평균입니다。
점수는손실에반비례하지만실질적으로동일한정보를포함합니다。
函数[lossGenerator, lossDiscriminator] = ganLoss(probReal,probGenerated)%计算鉴别器网络的损耗。lossDiscriminator = -mean(log(probReal)) -mean(log(1-probGenerated));%计算发电机网络的损耗。lossGenerator =意味着(日志(probGenerated));结束
미니배치전처리함수
preprocessMiniBatch함수는다음단계를사용하여데이터를전처리합니다。
입력되는셀형배열에서영상데이터를추출하여숫자형배열로결합합니다。
영상이
[1]범위내에있도록다시스케일링합니다。
函数X = preprocessMiniBatch(数据)%连接mini-batchX =猫(4、数据{:});%在[-1 1]范围内重新缩放图像。X =重新调节(X, 1, 1,“InputMin”0,“InputMax”, 255);结束
참고문헌
TensorFlow团队。花http://download.tensorflow.org/example_images/flower_photos.tgz
雷德福,亚历克,卢克·梅茨,和苏史密斯·钦塔拉。基于深度卷积生成对抗网络的无监督表示学习。预印本,2015年11月19日提交。http://arxiv.org/abs/1511.06434。
참고항목
dlnetwork|向前|预测|dlarray|dlgradient|dlfeval|adamupdate|minibatchqueue
관련항목
你也可以从以下列表中选择一个网站:
