이번역페이지는최신내용을담고있지않습니다。최신내용을영문으로보려면여기를클릭하십시오。
장단기기억신경망을사용하여심전도신호분류하기
이예제에서는딥러닝과신호처리를사용하여生理网2017年挑战의심전도(ECG)데이터를분류하는방법을보여줍니다。특히,이예제에서는장단기기억신경망과시간-주파수분석을사용합니다。
소개
심전도는일정시간동안사람심장의전기적활성을기록합니다。의사들은심전도를사용하여환자의심박이정상인지불규칙적인지를시각적으로판단합니다。
심방세동(AFIB)은심장의심방이심실과다른주기로뛸때발생하는불규칙적인심박입니다。
이예제에서는生理网2017挑战1],[2],[3.]의심전도데이터사용용。이데이터는https://physionet.org/challenge/2017/에서확인할수있습니다。데이터는300Hz로샘플링되고가그룹이네가지클래스클래스로분류한심전도신호로구성되어이들네가지클래스는(n),afib(a),기타기타(o),잡음이있는기록(〜)입니다。이예제에서는딥러닝을사용하여하여분류과정을자동화하는방법을보여이절차에서는정상심전도를afib증상을보이는신호신호와구분할수이진분류기분류기를를를분류기를를
이예제에서는시퀀스데이터와시계열데이터를연구하는데적합한일종의순환신경망(RNN)인장단기기억(LSTM)신경망을사용합니다。LSTM신경망은시퀀스의시간스텝간의장기적인종속성을학습할수있습니다。LSTM계층(lstmLayer(深度学习工具箱))은순방향의시간시퀀스를살펴볼수있고,양방향LSTM계층(bilstmLayer(深度学习工具箱))은순방향과역방향의시간시퀀스를살펴볼수있습니다。이예제에서는양방향LSTM계층을사용합니다。
훈련과정을가속화하려면GPU가있는시스템에서이예제를실행하십시오。시스템에GPU와并行计算工具箱™가있는경우MATLAB®은자동으로훈련에GPU를사용하고,그렇지않은경우CPU를사용합니다。
데이터를불러오고검토하기
ReadPhysionetData스크립트를실행하여生理网웹사이트에서데이터를다운로드하고적절한형식의심전도신호를포함하는垫파일(PhysionetData.mat)을생성합니다。데이터를다운로드하는데몇분정도걸릴수있습니다。PhysionetData.mat가아직현재폴더에없는경우에만스크립트를실행하는조건문을사용하십시오。
如果~ isfile (“PhysionetData.mat”) ReadPhysionetData结束负载PhysionetData
불러오기불러오기작업은작업작업공간에두개의信号와标签를추가합니다。信号는는심전도신호신호를하는셀형배열배열标签는신호의대응되는실측레이블을포함하는直言형배열입니다。
信号(1:5)
ans =5×1单元阵列{1×9000 double} {1×9000 double} {1×18000 double} {1×9000 double} {1×18000 double}
标签(1:5)
ans =5×1分类N N N a
总结함수를사용하여데이터에몇개의AFib신호와정상신호가있는지확인합니다。
总结(标签)
A 738 n 5050
신호길이에대한히스토그램을생성합니다。대부분의신호의길이가9000개샘플입니다。
L = cellfun (@length,信号);h =直方图(左);xticks (0:3000:18000);xticklabels (0:3000:18000);标题(“信号长度”)包含(“长度”) ylabel (“数”)

각클래스별로신호하나의세그먼트를시각화합니다。AFib심박은불규칙한간격으로샘플이배치되는반면정상심박은규칙적인간격을갖습니다。AFib심박신호에는정상심박신호에서QRS복합파전에뛰P파는가없는경우가많습니다。정상신호의플롯에서는P파와QRS복합파를볼수있습니다。
正常={1}信号;aFib ={4}信号;次要情节(2,1,1)情节(正常的)标题(“正常的节奏”) xlim((4000、5200))ylabel (“振幅(mV)”)文本(4330、150、“P”,“HorizontalAlignment”,“中心”)文本(4370、850、“QRS”,“HorizontalAlignment”,“中心”) subplot(2,1,2) plot(aFib) title(心房纤维性颤动的) xlim((4000、5200))包含(“样本”) ylabel (“振幅(mV)”)

훈련을위해데이터준비하기
훈련중에trainNetwork함수는데이터를미니배치로분할합니다。이함수는그런다음동일한미니배치의신호가모두동일한길이를갖도록채우거나자릅니다。추가되었거나제거된정보를기반으로하여신경망에서신호를올바르지않게해석할수있기때문에너무많이채우거나자르면신경망성능이저하될수있습니다。
과도한채우기나자르기를방지하려면심전도신호의길이가모두개9000샘플이되도록심전도신호에segmentSignals함수를적용하십시오。9000개이함수는샘플이미만인신호를무시합니다。9000개신호의샘플이보다많은경우segmentSignals는신호를분할해9000개샘플크기의세그먼트가가능한한가장많이생성되게하고나머지샘플은무시합니다。예를들어18500개의샘플로구성된신호는9000개의샘플로구성된신호2개가되고나머지500개의샘플은무시됩니다。
[信号,标签]= segmentSignals(信号,标签);
信号배열의처음5개요소를보고각항목의길이가이제9000개샘플이된것을확인합니다。
信号(1:5)
ans =5×1单元阵列{1×9000 double} {1×9000 double} {1×9000 double} {1×9000 double} {1×9000 double}
원시신호데이터를사용하여분류기훈련시키기
분류기를설계하려면이전섹션에서생성된원시신호를사용하십시오。신호를분류기훈련을위한훈련세트와새데이터에대한분류기의정확도테스트를위한테스트세트로분할합니다。
总结함수를사용하여AFib신호와정상신호의비가718:4937또는약1:7임을확인합니다。
总结(标签)
A 718 n 4937
신호의이7/8정상신호이므로분류기는모든신호를정상으로분류하면높은정확도를달성할수있음을학습하게됩니다。이러한편향을방지하려면정상신호와AFib신호의개수가같아지도록데이터셋에서AFib신호를복제하여AFib신호의개수를늘리십시오。일반적으로오버샘플링이라고하는이러한복제기법은딥러닝에서사용되는데이터증대의한가지형태입니다。
신호를클래스에따라분할합니다。
afibX(标签= = =信号“一个”);afibY =标签(标签= =“一个”);normalX(标签= = =信号“N”);= = =饱和标签(标签“N”);
다음으로,dividerand를사용하여각클래스의목표값을훈련세트와세트로무작위로나눕니다。
[trainIndA, ~, testIndA] = dividerand(718年,0.9,0.0,0.1);[trainIndN, ~, testIndN] = dividerand(4937年,0.9,0.0,0.1);XTrainA = afibX (trainIndA);YTrainA = afibY (trainIndA);XTrainN = normalX (trainIndN);YTrainN =饱和(trainIndN);XTestA = afibX (testIndA);YTestA = afibY (testIndA);XTestN = normalX (testIndN);YTestN =饱和(testIndN);
이제훈련에사용할646개의AFib신호와4443개의정상신호가있습니다。각클래스에서동일한개수의신호가있도록하려면처음4438개의정상신호를사용한다음repmat.634개를사용하여처음의AFib신호가7번반복되도록복제하십시오。
테스트에사용할신호는72개의AFib신호와494개의정상신호가있습니다。처음490개의정상신호를사용한다음repmat.70개를사용하여처음의AFib신호가7번반복되도록복제하십시오。기본적으로,신경망은연속된신호가모두동일한레이블을갖지않도록하기위해훈련전에데이터를무작위로섞습니다。
XTrain = [repmat (XTrainA(1:634), 7日,1);XTrainN (1:4438)];YTrain = [repmat (YTrainA(1:634), 7日,1);YTrainN (1:4438)];XTest = [repmat (XTestA(1:70), 7日,1);XTestN (1:490)];欧美= [repmat (YTestA(1:70), 7日,1);YTestN (1:490);];
이제훈련세트와테스트세트에서정상신호와AFib신호사이의분포가균일합니다。
总结(YTrain)
A 4438 n 4438
总结(欧美)
A 490 n 490
LSTM신경망아키텍처정의하기
LSTM신경망은시퀀스데이터의시간스텝간의장기적인종속성을학습할수있습니다。이예제에서는순방향과역방향의시퀀스를모두살펴보므로양방향LSTM계층bilstmLayer를사용합니다。
입력신호가각각1개의차원을가지므로입력크기가크기로1구성된시퀀스가되도록지정합니다。100年출력크기가인양방향LSTM계층을지정하고시퀀스의마지막요소를출력합니다。다음명령은입력시계열을100개의특징으로매핑하도록양방향LSTM계층에지시하고완전연결계층에대한출력값을준비합니다。마지막으로,크기인가2완전연결계층을포함하여2개의클래스를지정하고,이어서소프트맥스계층과분류계층을지정합니다。
层= [...sequenceInputLayer (1) bilstmLayer (100“OutputMode”,“最后一次”(2) softmaxLayer classificationLayer
Layer = 5x1 Layer array with layers: 1 '' Sequence Input Sequence Input with 1 dimensions 2 '' BiLSTM BiLSTM with 100 hidden units 3 '' Fully Connected 2 Fully Connected Layer 4 '' Softmax Softmax 5 '' Classification Output crossentropyex
다음은분류기의훈련옵션을지정합니다。신경망이훈련데이터를10번통과하도록“MaxEpochs”를10으로설정합니다。신경망이한번에150개의훈련신호를살펴보도록“MiniBatchSize”150年를으로설정합니다。“InitialLearnRate”를0.01로설정하면훈련과정속도를이는데도움에이됩니다。시스템이한번에지나치게많은이터를살펴봄으로써메모리가부족부족않도록“SequenceLength”1000年를으로지정하여신호를더작은조각으로분할합니다。기울기가지나치게커지지않도록”GradientThreshold“로를1설정하여훈련과정을안정화합니다。“阴谋”를“训练进步”로지정하여반복횟수가늘어남에따라훈련진행상황을그래픽으로표시하는플롯을생성합니다。“详细”를假로설정하여플롯에표시되는데이터에대응되는표의형태로출력값이표시되지않도록합니다。이표를보려면“详细”를真正的로설정하십시오。
亚当(적이예제에서는응적모멘트추정)솔버를사용합니다。亚当은LSTM과같은RNN에서디폴트값인모멘텀을사용한확률적경사하강법(个)솔버보다더나은성능을보입니다。
选择= trainingOptions (“亚当”,...“MaxEpochs”10...“MiniBatchSize”, 150,...“InitialLearnRate”, 0.01,...“SequenceLength”, 1000,...“GradientThreshold”, 1,...“ExecutionEnvironment”,“汽车”,...“阴谋”,“训练进步”,...“详细”、假);
LSTM신경망훈련시키기
trainNetwork를사용하여지정된훈련옵션과계층아키텍처로LSTM신경망을훈련시킵니다。훈련세트가크기때문에훈련과정에몇분정도걸릴수있습니다。
net = trainnetwork(xtrain,ytrain,图层,选项);

훈련진행과정플롯의상단서브플롯은훈련정확도,즉각미니배치의분류정확도를나타냅니다。훈련이성공적으로진행되면이값은일반적으로를100%향해늘어납니다。하단서브플롯에는훈련손실,즉각미니배치의교차엔트로피손실이표시됩니다。훈련이성공적으로진행되면이값은일반적으로0을향해줄어듭니다。
훈련이수렴되지않을경우플롯이특정상향또는하향방향으로진행되는대신특정값사이를진동할수있습니다。이러한진동은훈련정확도가증가하지않고있으며훈련손실이감소하지않고있음을의미합니다。이상황은훈련시작부터발생할수도있고,또는훈련정확도가초기에는개선되다가이어서플롯이일정해진경우일수도있습니다。대부분의경우,훈련옵션을변경하면신경망이수렴하는데도움이됩니다。MiniBatchSize를줄이거나InitialLearnRate를줄이면훈련시간이늘어나긴하지만신경망이더욱잘학습하는데도움이될수있습니다。
분류기의훈련정확도는약50%와약60%사이를진동합니다。그리고10회의时代를마친후에이미훈련에수분이소요된것을볼수있습니다。
훈련및테스트정확도시각화하기
훈련이진행된신호에대한분류기의정확도를나타내는훈련정확도를계산합니다。먼저훈련데이터를분류합니다。
XTrain trainPred =分类(净,“SequenceLength”, 1000);
분류문제에서는실제값이알려져있는데이터세트에대한분류기의성능을시각화하기위해정오분류표가사용됩니다。목표클래스는신호의실측레이블이고,출력클래스는신경망이신호에할당한레이블입니다。좌표축레이블은클래스레이블,즉AFib (A)와정상(N)을나타냅니다。
confusionchart명령을사용하여테스트데이터예측값에대한전체적인분류정확도를계산합니다。“RowSummary”를'行标准化'로지정하여행요약에참양성률과거짓양성률을표시합니다。또한“ColumnSummary”를“column-normalized”로지정하여열요약에양성예측도와오발견율을표시합니다。
LSTMAccuracy = sum(trainPred == YTrain)/numel(YTrain)*100
LSTMAccuracy = 61.7283
图confusionchart (YTrain trainPred,“ColumnSummary”,“column-normalized”,...“RowSummary”,'行标准化','标题',“LSTM混淆图”);

이번에는같은신경망을사용하여테스트데이터를분류합니다。
XTest testPred =分类(净,“SequenceLength”, 1000);
테스트정확도를계산하고,분류성능을정오분류표로시각화합니다。
LSTMAccuracy = sum(testPred == YTest)/numel(YTest)*100
LSTMAccuracy = 66.2245
图confusionchart(欧美、testPred“ColumnSummary”,“column-normalized”,...“RowSummary”,'行标准化','标题',“LSTM混淆图”);

특징추출을사용하여성능개선하기
데이터에서특징을추출하여분류기의훈련및테스트정확도를개선할수있습니다。어느특징을추출할지판단하기위해이예제에서는스펙트로그램과같은시간-주파수영상을계산하는방법을조정하며,이를사용하여컨벌루션신경망(CNN)을훈련시킵니다(4],[5].
각신호유형의스펙트로그램을시각화합니다。
fs = 300;图次要情节(2,1,1);pspectrum(正常,fs,的谱图,'timeresolution', 0.5)标题('正常信号'次要情节(2,1,2);pspectrum (aFib fs,的谱图,'timeresolution', 0.5)标题(“AFib信号”)
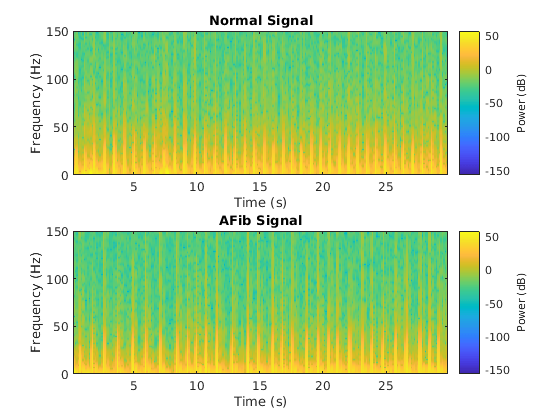
CNN이예제에서는대신LSTM을사용하므로접근방법을1차원신호에적용되도록변환하는것이중요합니다。시간-주파수(TF)모멘트는스펙트로그램에서정보를추출합니다。각모멘트는LSTM에입력할1차원특징으로사용할수있습니다。
시간영역에서두개의모特遣部队멘트를검토합니다。
순시주파수(
instfreq)스펙트럼엔트로피(
pentropy)
instfreq함수는신호의시간종속주파수를파워스펙트로그램1차의모멘트로추정합니다。함수는시간윈도우에대해단시간푸리에변환을사용하여스펙트로그램을계산합니다。이예제에서는255개의시간윈도우를사용합니다。함수의시간출력값은시간윈도우의중앙에대응됩니다。
각신호유형에대해순시주파수를시각화합니다。
[instFreqA, tA] = instfreq (aFib fs);[instFreqN, tN] = instfreq(正常,fs);图次要情节(2,1,1);情节(tN, instFreqN)标题('正常信号')包含(“时间(s)”) ylabel (瞬时频率的次要情节(2,1,2);instFreqA情节(tA)标题(“AFib信号”)包含(“时间(s)”) ylabel (瞬时频率的)

cellfun을사용하여하여훈련훈련세트와테스트세트의모든셀셀instfreq함수를적용합니다。
instfreqTrain = cellfun (@ (x) instfreq (x, fs), XTrain“UniformOutput”、假);instfreqTest = cellfun (@ (x) instfreq (x, fs), XTest“UniformOutput”、假);
스펙트럼엔트로피는신호의스펙트럼이얼마나뾰족하거나평탄한지측정합니다。정현파의합과같이스펙트럼이뾰족한신호는스펙트럼엔트로피가낮습니다。백색잡음과같이스펙트럼이평탄한신호는스펙트럼엔트로피가높습니다。pentropy함수는파워스펙트로그램을바탕으로스펙트럼엔트로피를추정합니다。순시주파수추정의경우와마찬가지로,pentropy는255개의시간윈도우를사용하여스펙트로그램을계산합니다。함수의시간출력값은시간윈도우의중앙에대응됩니다。
각신호유형에대해스펙트럼엔트로피를시각화합니다。
[pentropyA, tA2] = pentropy (aFib fs);[pentropyN, tN2] = pentropy(正常,fs);图subplot(2,1,1) plot(tN2,pentropyN) title('正常信号') ylabel (“谱熵”) subplot(2,1,2) plot(tA2,pentropyA) title(“AFib信号”)包含(“时间(s)”) ylabel (“谱熵”)

cellfun을사용하여하여훈련훈련세트와테스트세트의모든셀셀pentropy함수를적용합니다。
pentropyTrain = cellfun (@ (x) pentropy (x, fs), XTrain“UniformOutput”、假);pentropyTest = cellfun (@ (x) pentropy (x, fs), XTest“UniformOutput”、假);
새훈련세트와테스트세트의각셀이2개의차원,즉2개의특징을갖도록특징들을결합합니다。
XTrain2 = cellfun (@ (x, y) (x, y), instfreqTrain, pentropyTrain,“UniformOutput”、假);XTest2 = cellfun (@ (x, y) (x, y), instfreqTest, pentropyTest,“UniformOutput”、假);
새입력값의형식을시각화합니다。각셀은더이상길이가샘플9000개인신호를포함하지않습니다。이제각길이가샘플255개인2개의특징을포함합니다。
XTrain2 (1:5)
ans =5×1单元阵列{2×255 double} {2×255 double} {2×255 double} {2×255 double} {2×255 double}
아이터표준표준화
순시주파수와스펙트럼엔트로피의평균값은거의10배차이가납니다。또한,순시주파수의평균은LSTM이효과적으로학습을진행하기에는지나치게높을수있습니다。신경망이평균이크고값의범위가큰데이터에대해피팅된경우,큰입력값은신경망의학습과수렴속도를저하할수있습니다(6].
意思是(instFreqN)
ans = 5.5615
意思是(pentropyN)
ans = 0.6326
훈련세트의평균과표준편차를사용하여훈련세트와테스트세트를표준화합니다。표준화(z -점수화)는훈련중에신경망성능을개선하는방법으로널리사용됩니다。
十五= [XTrain2 {}):;μ=意味着(十五,2);sg =性病(十五,[],2);XTrainSD = XTrain2;XTrainSD = cellfun (@ (x)(即xμ)。/ sg, XTrainSD,“UniformOutput”、假);XTestSD = XTest2;XTestSD = cellfun (@ (x)(即xμ)。/ sg, XTestSD,“UniformOutput”、假);
표준화된순시주파수와스펙트럼엔트로피의평균을표시합니다。
instfreqnsd = xtrainsd {1}(1,:);pentropynsd = xtrainsd {1}(2,:);意思(instfreqnsd)
ans = -0.3211
意思是(pentropyNSD)
ans = -0.2416
LSTM신경망아키텍처수정하기
이제신호가각각2개의차원을갖습니다。따라서입력시퀀스의크기를2로지정하여신경망아키텍처를수정해야합니다。100年출력크기가인양방향LSTM계층을지정하고시퀀스의마지막요소를출력합니다。2크기가인완전연결계층을포함하여2개의클래스를지정하고,이어서소프트맥스계층과분류계층을지정합니다。
层= [...sequenceInputLayer (2) bilstmLayer (100“OutputMode”,“最后一次”(2) softmaxLayer classificationLayer
Layer = 5x1 Layer array with layers: 1 " Sequence Input Sequence Input with two dimensions 2 " BiLSTM BiLSTM with 100 hidden units 3 " Fully Connected 2 Fully Connected Layer 4 " Softmax Softmax 5 " Classification Output crossentropyex
훈련옵션을지정합니다。신경망이훈련데이터를30번통과하도록최대时代횟수를30으로설정합니다。
选择= trainingOptions (“亚当”,...“MaxEpochs”30岁的...“MiniBatchSize”, 150,...“InitialLearnRate”, 0.01,...“GradientThreshold”, 1,...“ExecutionEnvironment”,“汽车”,...“阴谋”,“训练进步”,...“详细”、假);
시간-주파수특징으로LSTM신경망훈련시키기
trainNetwork를사용하여지정된훈련옵션과계층아키텍처로LSTM신경망을훈련시킵니다。
net2 = trainNetwork (XTrainSD、YTrain层,选择);

훈련정확도가크게개선되었습니다。교차엔트로피손실은0을향해가고있습니다。또한,TF모멘트가원시시퀀스보다짧기때문에훈련에필요한시간이줄어듭니다。
훈련및테스트정확도시각화하기
업데이트된LSTM신경망을사용하여훈련데이터를분류합니다。분류성능을정오분류표로시각화합니다。
trainPred2 =分类(net2 XTrainSD);LSTMAccuracy = sum(trainPred2 == YTrain)/numel(YTrain)*100
LSTMAccuracy = 83.5962
图confusionchart (YTrain trainPred2,“ColumnSummary”,“column-normalized”,...“RowSummary”,'行标准化','标题',“LSTM混淆图”);

업데이트된신경망을사용하여테스트데이터를분류합니다。정오분류표를플로팅하여테스트정확도를검토합니다。
testpred2 =分类(net2,xtestsd);lstmaccuracy = sum(testpred2 == ytest)/ numel(ytest)* 100
LSTMAccuracy = 80.1020
图confusionchart(欧美、testPred2“ColumnSummary”,“column-normalized”,...“RowSummary”,'行标准化','标题',“LSTM混淆图”);

결론
이예제에서는LSTM신경망을사용하여심전도신호에서심방세동을검출하는분류기를만드는방법을소개했습니다。이절차에서는주로건강한환자로구성된데이터에서이상조건을검출하고자할때발생하는분류편향을방지하기위해오버샘플링을사용했습니다。원시신호데이터를사용하여LSTM신경망을훈련시키면분류정확도가매우낮아집니다。각신호에대해2개의시간-주파수모멘트특징을사용하여신경망을훈련시키면분류성능이크게개선되고훈련시간도줄어듭니다。
참고문헌
[1]基于短单导联心电图记录的心房颤动分类:物理网络/计算在心脏病学中的挑战,2017。https://physionet.org/challenge/2017/
[2] Clifford, Gari, Chengyu Liu, Benjamin Moody, Li-wei H. Lehman, Ikaro Silva, Qiao Li, Alistair Johnson, Roger G. Mark。基于单导联心电图记录的心房颤动分类:物理网络计算在心脏病学中的挑战2017计算在心脏病学(雷恩:IEEE)。2017年第44卷,第1-4页。
A. L. Goldberger, A. L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. Ch. Ivanov, R. G. Mark, J. E. miietus, G. B. Moody, C.-K。彭,还有h·e·斯坦利。“PhysioBank, PhysioToolkit和PhysioNet:复杂生理信号新研究资源的组成部分”。循环.第101卷,第23卷,2000年6月13日,页e215-e220。http://circ.ahajournals.org/content/101/23/e215.full
[4] Pons Jordi Thomas Lidy和Xavier Serra。“实验音乐驱动的卷积神经网络”。第十四届基于内容的多媒体索引国际研讨会.2016年6月。
[5], D。“深度学习彻底改造了助听器,”IEEE频谱, Vol. 54, No. 3, 2017年3月,32-37页。doi: 10.1109 / MSPEC.2017.7864754。
[6] Brownlee,杰森。如何在Python中扩展长短期内存网络的数据.2017年7月7日。https://machinelearningmastery.com/how-to-scale-data-for-long-short-term-memory-networks-in-python/。
참고항목
함수
instfreq|pentropy|trainingOptions(深度学习工具箱)|trainNetwork(深度学习工具箱)|bilstmLayer(深度学习工具箱)|lstmLayer(深度学习工具箱)
관련항목
- 장단기기억신경망(深度学习工具箱)
你也可以从以下列表中选择一个网站:
