图片对图片회귀를위해데이터저장소준비하기
이예제에서는image-to-image회귀신경망을훈련시키기위해ImageDatastore의变换함수와结合함수를사용하여데이터저장소를준비하는방법을보여줍니다。
이예제에서는잡음제거신경망훈련에적합한파이프라인을사용하여데이터를전처리하는방법을보여줍니다。그런다음전처리된잡음데이터를사용하여영상잡음을제거하도록간단한컨벌루션오토인코더신경망을훈련시킵니다。
전처리파이프라을사용하여데이터준비하기
이예제에서는입력상픽셀중일부가0또는1(각각검은색과흰색)로설정된점잡음모델을사용합니다。잡음이있는상은신경망입력값으로기능합니다。잡음이빠진원본상은예상신경망응답변수로기능합니다。신경망은점잡음을검출하고제거하는것을학습합니다。
숫자데이터세트에있는원본상을imageDatastore로서불러옵니다。이데이터저장소에는0부터9까지숫자를나타내는합성상10000개가있습니다。이、상은서로다른글꼴로만들어진숫자、이、상에무작위변환을적용하여생성됩니다。각숫자상은28×28픽셀입니다。이데이터저장소에는범주당동일한개수의상이포함되어있습니다。
digitDatasetPath = fullfile(matlabroot,“工具箱”,“nnet”,...“nndemos”,“nndatasets”,“DigitDataset”);imds = imageDatastore(digitDatasetPath,...IncludeSubfolders = true, LabelSource =“foldernames”);
파일I/O비용을최소화할수있도록읽기크기를큰값으로지정하십시오。
洛桑国际管理发展学院。ReadSize = 500;
훈련에앞서洗牌함수를사용하여숫자데이터를섞습니다。
Imds = shuffle(Imds);
splitEachLabel함수를사용하여洛桑国际管理发展学院를훈련,검증및테스트를위한원래그대로의영상을포함하는세개의영상데이터저장소로나눕니다。
[imdsTrain,imdsVal,imdsTest] = splitEachLabel(imds,0.95,0.025);
变换함수를사용하여각입력、상에잡음을추가한、함수를사용하여각입력、상을만듭니다。이상은신경망입력값이됩니다。变换함수는기본데이터저장소에서데이터를읽어들인후(이예제의끝부분에정의된)헬퍼함수addNoise에정의된연산을사용하여데이터를처리합니다。变换함수의출력값은TransformedDatastore입니다。
dstrainnoise = transform(imdsTrain,@addNoise);dsvalnoise = transform(imdsVal,@addNoise);dstestnoise = transform(imdsTest,@addNoise);
结合함수를사용하여잡음이있는영상과원래그대로의영상을단일데이터저장소로결합하는데,이데이터저장소가trainNetwork에데이터를입력하게됩니다。이결합된데이터저장소는데이터배치를trainNetwork에필한것과같이2열셀형배열로읽어들입니다。结合함수의출력값은CombinedDatastore입니다。
dsTrain = combine(dstrainnoise,imdsTrain);dsVal = combine(dsvalnoise,imdsVal);dsTest = combine(dstestnoise,imdsTest);
变换함수를사용하여입력데이터저장소와응답데이터저장소양쪽에공통적인전처리연산을추가로수행합니다。이예제의끝부분에정의된commonPreprocessing헬퍼함수는입력영상과응답영상을신경망의입력크기와일치하도록32×32픽셀로크기조정한후각영상의데이터를[0,1]범위로정규화합니다。
dsTrain = transform(dsTrain,@ common预处理);dsVal = transform(dsVal,@ common预处理);dsTest = transform(dsTest,@ common预处理);
마지막으로,变换함수를사용하여훈련세트에무작위대를적용합니다。이예제의끝부분에정의된augmentImages헬퍼함수는데이터에무작위로90도회전을적용합니다。신경망입력값과이에대응하는예상응답변수에동일한회전이적용됩니다。
dsTrain = transform(dsTrain,@augmentImages);
대는과적합을줄이고훈련된신경망에존재하는회전에강성을더해줍니다。검데이터세트나테스트데이터세트에는무작위대가필하지않습니다。
전처리된데이터미리보기
훈련데이터를준비하려면몇가지전처리연산이필요하므로전처리된데이터를미리봄으로써훈련에앞서데이터가올바른지확인합니다。预览함수를사용하여데이터를미리봅니다。
잡음이있는、상과원래그대로의、잡음이있는、상으로이루어진쌍의예를蒙太奇(图像处理工具箱)함수를사용하여시각화합니다。훈련데이터가올바르게보입니다。왼쪽열에있는입력상에서점잡음이보입니다。잡음이더해진것외에는입력、상과응답、잡음이더해진것외에는입력、상이동일합니다。입력상과응답상양쪽에모두무작위90도회전이동일하게적용되었습니다。
exampleData =预览(dsTrain);input = exampleData(:,1);responses = exampleData(:,2);Minibatch = cat(2,输入,响应);蒙太奇(minibatch',Size=[8 2])“输入(左)和响应(右)”)

컨벌루션오토코더신경망정의하기
컨벌루션오토코더는상잡음제거를위해자주사용되는아키텍처입니다。컨벌루션오토코더는코더와디코더라는두단계로구성됩니다。인코더는원본입력영상을너비와높이는줄어들었으나원본입력영상에비해공간위치당특징맵이많다는점에서보다심층적인기저의표현으로압축합니다。압축된기저의표현은원본영상에있는고주파특징을복원하는능력에서어느정도의공간분해능을잃게되지만,한편으로는원본영상을인코딩할때잡음이있는아티팩트를포함시키지않아야한다는사실을학습합니다。디코더는인코딩된신호를반복적으로업샘플링하여원래의너비,높이,채널개수로되돌려놓습니다。인코더가잡음을제거하기때문에디코딩된최종영상에는잡음아티팩트가줄어들어있습니다。
이예제에서는다음과같은深度学习工具箱™의계층을사용하여컨벌루션오토인코더신경망을정의합니다。
imageInputLayer—상입력계층convolution2dLayer-컨벌루션신경망의컨벌루션계층reluLayer- ReLU(整流线性单元)계층maxPooling2dLayer- 2차원최댓값풀링계층transposedConv2dLayer-전치된컨벌루션계층clippedReluLayer-剪辑ReLU(整流线性单元)계층regressionLayer-회귀출력계층
상입력계층을만듭니다。2배로다운샘플링및업샘플링을하면서생기는채우기문제를단순화하기위해입력크기를32×32로선택합니다。32는2,4,8로나누어떨어지기때문입니다。
imageLayer = imageInputLayer([32,32,1]);
코딩계층을만듭니다。인코더에서의다운샘플링은풀크기를2로하고스트라이드로를2하는최댓값풀링을통해이루어집니다。
encodingLayers = [...convolution2dLayer(3 8填充=“相同”),...reluLayer,...maxPooling2dLayer(2,填充=“相同”步= 2),...convolution2dLayer(3、16、填充=“相同”),...reluLayer,...maxPooling2dLayer(2,填充=“相同”步= 2),...convolution2dLayer(3、32、填充=“相同”),...reluLayer,...maxPooling2dLayer(2,填充=“相同”步= 2);
디코딩계층을만듭니다。디코더는전치된인코딩된신호를스트라이드2가인컨벌루션계층을사용하여업샘플링하며,2배업샘플링합니다。신경망은clippedReluLayer를마지막활성화계층으로사용하여출력값이[0,1]범위내에오도록강제합니다。
decodingLayers = [...transposedConv2dLayer(2 32步= 2),...reluLayer,...transposedConv2dLayer(2 16步= 2),...reluLayer,...transposedConv2dLayer(2, 8,跨步= 2),...reluLayer,...convolution2dLayer(1, - 1,填充=“相同”),...clippedReluLayer (1.0),...regressionLayer];
영상입력계층,인코딩계층및디코딩계층을결합하여컨벌루션오토인코더신경망아키텍처를형성합니다。
layers = [imageLayer,encodingLayers,decodingLayers];
훈련옵션정의하기
亚当최적화를사용하여신경망을훈련시킵니다。trainingOptions함수를사용하여하이퍼파라미터설정을지정합니다。훈련을纪元50회수행합니다。
选项= trainingOptions(“亚当”,...MaxEpochs = 50,...MiniBatchSize = imd。ReadSize,...ValidationData = dsVal,...ValidationPatience = 5,...情节=“训练进步”,...OutputNetwork =“best-validation-loss”,...Verbose = false);
신경망훈련시키기
이제데이터소스와훈련옵션이구성되었으니trainNetwork함수를사용하여컨벌루션오토코더신경망을훈련시킵니다。
사용가능한gpu가있으면gpu에서훈련시킵니다。GPU를사용하려면并行计算工具箱™와CUDA®지원NVIDIA®GPU가필합니다。자세한내용은릴리스별gpu지원(并行计算工具箱)항목을참조하십시오。훈련은NVIDIA Titan XP에서15분정도걸립니다。
net = trainNetwork(dsTrain,layers,options);modelDateTime = string(datetime(“现在”格式=“yyyy-MM-dd-HH-mm-ss”));保存(“trainedImageToImageRegressionNet——”+ modelDateTime +“.mat”,“净”);
잡음제거신경망의성능평가하기
预测함수를사용하여테스트세트에서출력상을얻습니다。
ypred = predict(net,dsTest);
预览함수를사용하여테스트세트에서잡음이있는영상과원래그대로의영상으로이루어진쌍을얻습니다。
testBatch =预览(dsTest);
잡음제거가얼마나잘작동하는지가늠해볼수있도록샘플입력영상과이에연관되어예측된신경망의출력값을시각화합니다。예상과같이신경망의출력영상에서는입력영상의잡음아티팩트가대부분제거되었습니다。잡음제거된상은코딩및디코딩과정의결과로약간흐릿합니다。
Idx = 1;Y = ypred(:,:,:,idx);x = testBatch{idx,1};ref = testBatch{idx,2};蒙太奇({x, y})
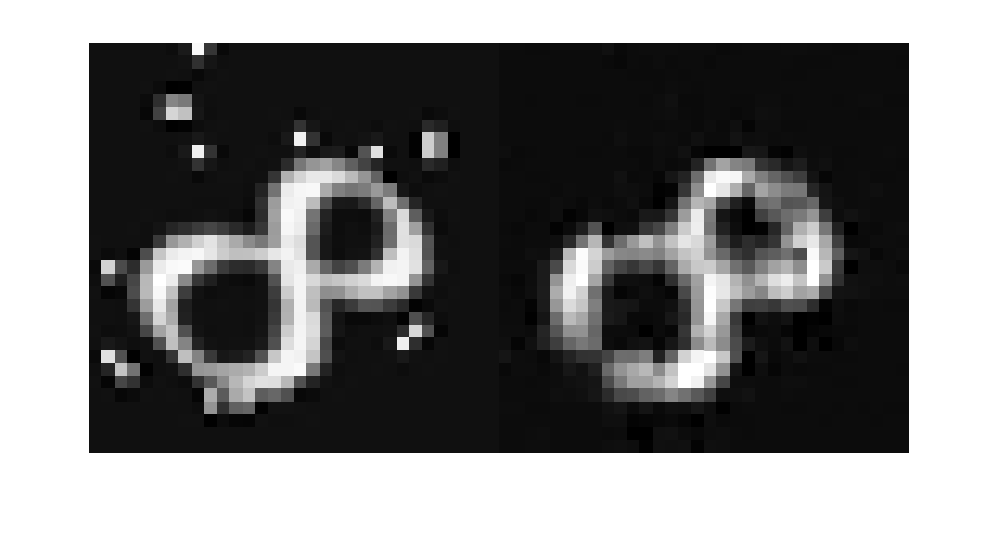
피크신호대잡음비(psnr)를분석하여신경망의성능을평가합니다。
psnrnoise = (x,ref)
psnrNoisy =单19.6457
psnrDenoised = psnr(y,ref)
psnrDenoised =单20.6994
예상과같이출력상의psnr이잡음이있는입력상보다높습니다。
지원 함수
addNoise헬퍼함수는imnoise(图像处理工具箱)함수를사용하여상에점잡음을추가합니다。addNoise함수를사용하려면입력데이터의형식이상데이터로구성된셀형배열이어야합니다。이는ImageDatastore의读함수가반환하는데이터의형식과일치합니다。
函数dataOut = addNoise(data);为idx = 1:size(data,1) dataOut{idx} = imnoise(data{idx},“盐和胡椒”);结束结束
commonPreprocessing헬퍼함수는훈련,검및테스트세트에공통적전처리를정의합니다。헬퍼함수는다음의전처리단계를수행합니다。
헬퍼함수를사용하려면입력데이터의형식이영상데이터로구성열된2셀형배열이어야합니다。이는CombinedDatastore의读함수가반환하는데이터의형식과일치합니다。
函数dataOut = common预处理(数据)dataOut = cell(大小(数据));为Col = 1:size(data,2)为Idx = 1:size(data,1) temp = single(data{Idx,col});Temp = imresize(Temp,[32,32]);Temp = rescale(Temp);dataOut{idx,col} = temp;结束结束结束
augmentImages헬퍼함수는rot90함수를사용하여데이터에무작위로90도회전을적용합니다。신경망입력값과이에대응하는예상응답변수에동일한회전이적용됩니다。이함수를사용하려면입력데이터의형식이영상데이터로구성열된2셀형배열이어야합니다。이는CombinedDatastore의读함수가반환하는데이터의형식과일치합니다。
函数dataOut = augmentImages(数据)dataOut = cell(大小(数据));为idx = 1:size(data,1) rot90Val = randi(4,1,1)-1;dataOut(idx,:) = {rot90(data{idx,1},rot90Val),...rot90(数据{idx 2}, rot90Val)};结束结束
참고 항목
trainNetwork|trainingOptions|变换|结合|imageDatastore
관련 예제
세부 정보
您也可以从以下列表中选择一个网站: