
函数实现susceptible-infected-removed fitVirusCV19(先生)流行病模型估计列病评估。假设的模型是一个合理的描述单程流行病。特别是人口模型假定一个常数,均匀混合的人,同样可能removalof感染。模型是数据驱动的,所以它的预测数据。用新的或变更的数据预测的变化。正式宣布疫情的流行和暴发流行,因为它报告的程序彼此无关。程序显示数据时开始日期足以计算初始近似值。
对于那些不熟悉流行病模型,我们建议以下文章:https://en.wikipedia.org/wiki/Compartmental_models_in_epidemiolog,
http://www.maths.usyd.edu.au/u/marym/populations/hethcote.pdf,https://web.stanford.edu/ jhj1 / teachingdocs / Jones-on-R0.pdf。
模型的参数是通过最小化目标函数,即残差的平方和值和残差的平方和值差异。的重量加式自动选择。优化工具箱函数fminsearch是用来计算未知模型参数的最优值。如果计算失败只有数据绘制。
冠状病毒的贡献包含数据为阿根廷、奥地利、比利时、巴西、加拿大、克罗地亚、中国、捷克共和国、丹麦、德国、匈牙利、法国、冰岛、印度、印尼、伊朗、意大利、日本、荷兰、挪威、波兰、葡萄牙、罗马尼亚、俄罗斯、斯洛伐克、塞尔维亚、斯洛文尼亚、韩国、西班牙、瑞士、土耳其、英国、美国和世界(28. april.2020)
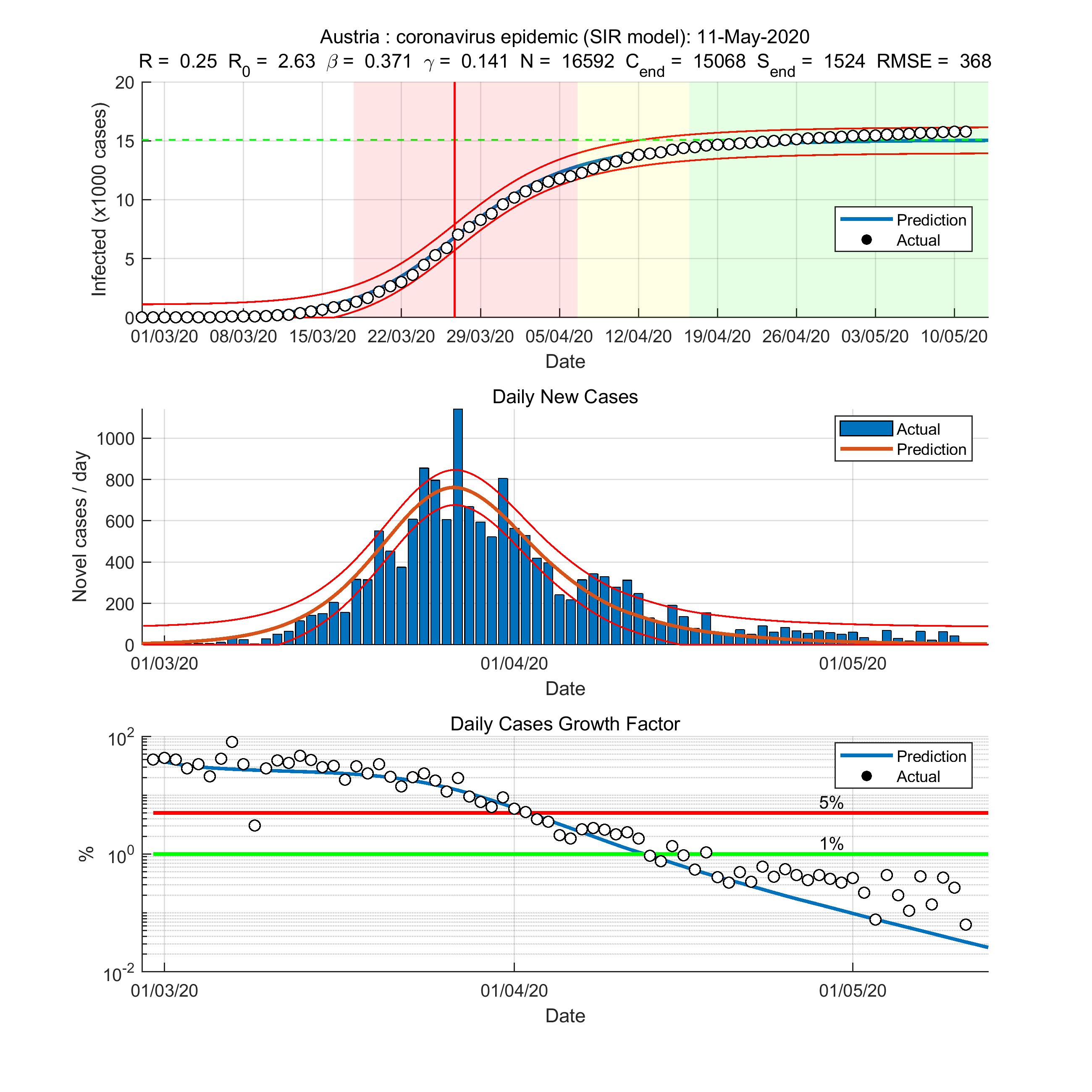
列病评价图,区域颜色单独列病阶段(这些都不是标准但任意选择为了方便):
红色——快速增长阶段
黄色——过渡到稳态阶段
绿色——结束阶段(高原阶段)
总用例图,利润+ / 3 * RMSE;每天新病例图,利润+ / dRMSE。
日常情况下生长因子图上两行1%(绿色)和5%(红色)所示仅为取向的原因。
结果保存在结构物(见功能fiVirusCV19头)。可选的结果可以印制
fitVirusCV19 (@getDataXXX,“打印”,“上”)
在XXX代表这个国家的名字。当回归失败然后只有数据绘制。12绪人口规模是有限的。你可以改变名称/值对的上限:
fitVirusCV19 (@getDataXXX nmax, nmax)
使用这个选项如果最终预测太高或超过全国人口。
排除增长率从图使用的图(def值是3)
fitVirusCV19 (@getDataXXX nsp, 2)
analyseCV功能块图评价的联系电话(σ),Cend(流行大小)、N(初始易感人口规模)。为国家XXX分析数据从10天的流行开始使用
analyseCV19 (@getDataXXX, 10)
免责声明:教育软件和数据,而不是医疗或商业用途。模型在某些情况下可能会失败。特别是,该模型可能不足;模型可能会失败在初始阶段和额外的流行或暴发阶段(不是先生所描述的模型)。使用它在你自己的自由裁量权。
展示的数据只是fitVirusCV19的操作。FitVirus,演示数据只用于教育和学术目的,不应该用于医学目的和商业。他们提供任何明示或默示的保证,包括但不限于隐含保证的适销性和健身为特定目的是否认的。
数据来源
https://ourworldindata.org/coronavirus-source-data。
https://www.worldometers.info/coronavirus/coronavirus-cases/ case-tot-outchina
https://en.wikipedia.org/wiki/2019%E2%80%9320_coronavirus_pandemic_by_country_and_territory
一个实际的数据来源是每个国家在相应的getData函数。
新:importTotalCases函数从< ourworldindata >数据文件读取并生成数据(Igor Podlubny)
可以找到更详细的描述
https://www.researchgate.net/publication/339311383_Estimation_of_the_final_size_of_the_coronavirus_epidemic_by_the_SIR_model
可以在示例
https://www.researchgate.net/publication/339912313_Forecasting_of_final_COVID-19_epidemic_size_200318
引用作为
米兰巴蒂斯塔(2020)。fitVirusCOVID19(//www.tatmou.com/matlabcentral/fileexchange/74658-fitviruscovid19), MATLAB中央文件交换。检索。
评论和评级(208年)
更新
| 5.2.1 | 微小的变化 |
|
| 5.2.0 | 添加函数fitVirusCV19R对待日常情况下刚刚删除的情况下,而不是新感染病例。 |
|
| 5.1.0 | 添加“滴答”选项来控制轴扁虱和“数据”选项来显示所有数据(参见readMe。使用m)。正确的每日新病例转向+ 1天(由于Burak)。改变analysisCV19:现在的天数是当前日期。 |
|
| 5.0.3 | 更新描述。改变恢复删除。 |
|
| 正式 | 微小的修改。添加统计每天的新病例。 |
|
| 5.0.1 | 添加参数analyseCV19阴谋。添加importTotalCasesR15对于那些只有MATLAB R2015a(由于舍伍德Samn) |
|
| 5.0.0 | 正确的南病例。变化范围。添加计算疫情结束(5例左) |
|
| 4.3.6 | 正确的报告 |
|
| 4.3.5 | 削减数据对某些国家(印度、印尼、阿根廷、克罗地亚) |
|
| 4.3.4 | 一些国家的数据 |
|
| 4.3.3 | 微小的修改。 |
|
| 4.3.2 | 改变形象 |
|
| 4.3.1 | 优素福建议的更新Kursat Tuncel正确显示日期和价值。添加版本fitVirusCOVID19cs更改图x轴(由于基督教希弗)datetime值。 |
|
| 4.2.1 | 更新描述 |
|
| 4.2.0 | 添加函数impoertTotalCases自动化的下载数据 |
|
| 4.1.4 | 更新数据。添加R0 > 1(基本众议员数)和R < = R0(众议员人数)标题和分析功能。 |
|
| 4.1.3 | 更新美国人民解放军文件夹中的数据(由帕特里克·安德森)。微小的修改。 |
|
| 4.1.2 | 微小的修改 |
|
| 以下4.4.1 | 正确fitVirusCV19 calcR0支持。金宝app对日本来说更新数据。 |
|
| 4.1.0 | 添加一个可选的图的增长率。更新数据(4.4.2020) |
|
| 4.0.9 | 更新描述 |
|
| 4.0.8 | 微小的修改 |
|
| 4.0.7 | 更新数据。改变图文本:现在它包含联系方式,联系时间和传染性。添加函数来计算R0。 |
|
| 4.0.6 | 改变形象 |
|
| 你 | 更新回归算法。默认情况下,解决方案与最小选择N(乐观的方法)。添加冰岛和瑞典。更新数据(2.4.2020) |
|
| 4.0.4 | 改变形象 |
|
| 4.0.3 | 更小的变化 |
|
| 4.0.2 | 微小的修改 |
|
| 4.0.1 | 添加检查数据文件夹(由于Rolf Boelens)。解放军在文件夹中添加两个实用程序(由于帕特里克·安德森) |
|
| 4.0.0 | 主要的修改。为那些没有SMTbx添加flambertw。添加importData函数。 |
|
| 3.0.6 | 更新描述 |
|
| 3.0.5 | 更新描述 |
|
| 3.0.4 | 更新描述 |
|
| 3.0.3 | 更新analyseCV19 |
|
| 3.0.2 | 更微小的修改 |
|
| 3.0.1 | 微小的修改 |
|
| 3.0.0 | 添加analyseCV19。更新数据,添加捷克、日本,斯洛伐克 |
|
| 2.0.05 | 改变图像与今天的预测在伦巴蒂大区 |
|
| 2.0.04 | 提高初始数据削减。添加数据对巴西、印度和波兰。 |
|
| 2.0.03 | 正确的描述 |
|
| 2.0.02 | 添加地址数据源 |
|
| 2.0.01 | 添加数据对加拿大(多亏了雷米Boisse)、印度尼西亚(由于Maldiku Servinu)和塞尔维亚。升级描述。 |
|
| 1.0.14 | 更新描述 |
|
| 1.0.13 | 更新描述 |
|
| 1.0.12 | 更新数据。添加匈牙利和纽约的状态 |
|
| 1.0.11 | 正确的数据 |
|
| 1.0.10 | 添加新数据 |
|
| 1.0.9 | 为NYState添加数据。添加的选项控制的迭代次数。 |
|
| 1.0.8 | 丹麦和挪威的添加数据。现在数据自动修剪。重量现在自动选择。微小的修改。 |
|
| 1.0.7 | 删除重复的例子 |
|
| 1.0.6 | 微小的修改。添加数据为克罗地亚和英国 |
|
| 1.0.5 | 正确的图 |
|
| 1.0.4 | 微小的修改 |
|
| 1.0.3 | 正确的描述 |
|
| 1.0.2中 | 改善印刷和初始猜测功能。为伦巴蒂大区添加数据。 |
|
| 1.0.1 | 编辑描述 |
MATLAB版本兼容性
平台的兼容性
窗户 macOS Linux标签
确认
启发:类Covid,fitVirusCV19varW(爵士的变权拟合模型),fitVirusCV19_state先生(美国COVID-19模型),fitVirusCV19v3 (COVID-19先生模型)
徐汇杨(查看配置文件)
米兰巴蒂斯塔(查看配置文件)
importTotalCasesWM的函数。从< m,读取数据https://www.worldometers.info/coronavirus/>并将其存储在数据文件夹现在可以作为fitVirusXX计划的一部分。
米兰巴蒂斯塔(查看配置文件)
得到的参数最小二乘方法。方法的描述可以在标准文本中找到回归分析例如seb,野生,非线性回归。
男孩巴贾杰(查看配置文件)
φ阮(查看配置文件)
你好,米兰,谢谢你的工作。对于那些新MatLab建模提供了一个良好的开端。您能推荐任何阅读资源了解获取参数的过程吗?
本的长袍(查看配置文件)
谢谢你!
米兰巴蒂斯塔(查看配置文件)
先生和物流模型适用于评估流行病的发展在国家相对严格的封锁。在其他国家,艾滋病不能由一个妖冶的描述。这样的国家,一个新程序称为fitVirusXX更合适。程序实现双物流曲线模型与识别第三和第四波的可能性。它是可用的
//www.tatmou.com/matlabcentral/fileexchange/76956-fitvirusxx
本的长袍(查看配置文件)
你能更新的例子包括最新的数据吗?
米兰巴蒂斯塔(查看配置文件)
是的,”流行(5例)的终结”意味着将会有剩余的5例,直到结束的流行病。
圣战Aldallal(查看配置文件)
谢谢你的伟大的工作。我注意到的定义“流行(5例)的终结”一天,每天将会有5例。然而,当我分析代码,我觉得代码发现的一天将会有剩余的5例到流行病。这是正确的吗?
为澄清这是一个小例子:
假设我们有以下#最后的病例
8月1日,6例
8月2日,5例
8月3日,3例
8月4日,4例
8月5日,1例
8月6日0
基于代码:流行结束(5例):8月4(因为剩下的是4 + 1 + 0)
基于“应该”定义:流行结束(5例):8月2(第一天只有5例/天)
Vigro深(查看配置文件)
曲线趋平
ANCA-DIANA POPOVICI(查看配置文件)
米兰巴蒂斯塔(查看配置文件)
如果数据是在C_end + / - RMSE这可能是好的。如果不是那么你先生不能安装的数据模型。请限制在描述部分。
穆克什Jakhar(查看配置文件)
你好先生,
我再次感谢你的努力工作。
我面临一个问题
然后C_end显示数量少的情况下总commulative病例
Pushpendra辛格(查看配置文件)
米兰巴蒂斯塔(查看配置文件)
N是重复的问题。爵士模型是一个简单的模型,不讨论一个国家的人口,但混合人口由易感人群,感染,和删除个人。和易感人群的项目估计初始数量(= N)根据目前的感染数量(fitVirusCV19)或删除(fitVirusCV19R)。做一个修辞问题;所有公民在印度敏感吗?如果你的答案是肯定的,你怎么证明它。
岩石翻译(查看配置文件)
嗨,米兰!
首先,我必须感谢和祝贺你的代码。我有一个疑问关于先生的模型。正如你所说,先生的作品比物流模型和更健壮。我试着和你的先生模型。但是我发现困难理解总人口数量N,这似乎是非常小(约26000),分析印度。因为印度有巨大的人口(13.5亿),如何实现先生模型吗?你的评论将高度赞赏。期待你的回复。
最好的,
Shib G
Eric Okyere(查看配置文件)
Kusal Dhananjaya(查看配置文件)
亲爱的先生,这是模型有效斯里兰卡?
Yahyeh Souleiman(查看配置文件)
我可以在吉布提先生的图形模型
米兰巴蒂斯塔(查看配置文件)
不。fitVirusCV19对待日常情况下新感染,fitVirusCV19R对待日常案例作为删除案例。
董gretch(查看配置文件)
嗨,米兰。在新的更新,将日常情况下刚刚删除的情况下,而不是新感染病例。我们实际使用每天死亡的数据?
openbob(查看配置文件)
干得好!
米兰巴蒂斯塔(查看配置文件)
不。函数计算最低是Matlab fminsearch不提供任何系数的统计数据。
穆克什Jakhar(查看配置文件)
我们能找到的统计参数如标准错误,t-stat和
假定值对于每个系数。
米兰巴蒂斯塔(查看配置文件)
计算给RMSE。没有提供其他误差分析,因为计划是日常使用因此一些更复杂的误差分析有点用处。
穆克什Jakhar(查看配置文件)
你好先生,
我再次感谢你的努力工作。
我计算出区域但现在我想计算这个模型的误差分析。
请帮助爵士
米兰巴蒂斯塔(查看配置文件)
程序只适合数据。
ravib1996(查看配置文件)
体重因素值
Kursat(查看配置文件)
亲爱的米兰,谢谢你的有价值的工作。它可以创建不同的场景如悲观、乐观通过改变模型中的参数吗?
米兰巴蒂斯塔(查看配置文件)
我没有2013版所以我不能检查什么出错了。然而,你需要fminsearc函数优化工具箱。
布拉德Haddin(查看配置文件)
@milan巴蒂斯塔谢谢你的代码。但我不能够运行2013年MATLAB代码。我能改变编码工作在我的版本?
Suttipan Sittirak(查看配置文件)
米兰巴蒂斯塔(查看配置文件)
的数据和数量的天数必须相同。
edklindemann(查看配置文件)
嗨,米兰,实际上dRMSE可以实现在Rt AnalysisCV19的情节吗?
也有可能检查的样本60 +的观察,在45天内(6周)?
欢呼和保持良好的工作
米兰巴蒂斯塔(查看配置文件)
在回归RMSE没有作用。后计算参数估计。
Jan Tyrychtr(查看配置文件)
穆克什Jakhar(查看配置文件)
你好先生,
我很欣赏你的努力工作。
我看了你所有的评论,我从那里得到的答案
但是我有一个querry:——有一些角色的RMSE结果的准确性? ?
米兰巴蒂斯塔(查看配置文件)
RMSE作为额外的信息。
米兰巴蒂斯塔(查看配置文件)
昨天ourworldindata数据为墨西哥的程序为:R = 1.3430, R0 = 1.7393,β= 0.2270,γ= 0.1305,N = 103574, I0 = 36.52。真正的价值是什么?
迭戈Fdz(查看配置文件)
美好的一天,先生,
目前我们有一个团队致力于这一过程的迁移到python。我们已经成功执行,使用的数据来自墨西哥。然而,我们发现,目前的估计,而低于实际价值。
为我们的参数得到N = 150756.910087开始,I0 = 52.94789661090745和R = 1.4018025212627043。有没有一种方法,我们可以验证这个结果吗?
米兰巴蒂斯塔(查看配置文件)
我没有意见的博客。
穆克什Jakhar(查看配置文件)
你好先生,
我很欣赏你的努力工作。
我看了你所有的评论,我从那里得到的答案
但是我有一个querry:——有一些角色的RMSE结果的准确性。或者我们显示RMSE的原因。
Ramy Oraby(查看配置文件)
米兰,看一看,告诉我你是怎么想的:https://johnhcochrane.blogspot.com/2020/05/an-sir-model-with-behavior.html
米兰巴蒂斯塔(查看配置文件)
我没有任何额外的文档。你应该咨询的Matlab人工语法。
Sambath Narayanan(查看配置文件)
我看到我以前的消息没有重复
你有多少颂歌方程解决吗?
你为优化目标函数是什么?
我不明白你下面的符号用在代码中
如果c2 > 0
f2 =规范((dC - diff (Csol)));
f1 =规范((C - Csol));
diff,直流,C (Csol) Csol吗?
如果你能分享一些documenetaation升值
Sambath Narayanan(查看配置文件)
同时,
你是如何得到的表达式dCdt吗?
米兰巴蒂斯塔(查看配置文件)
我不熟悉Python,但如果我是你,然后我试着翻译现有的Matlab代码到Python,至少计算部分。
Sambath Narayanan(查看配置文件)
嗨,米兰
我在几个州和城市在印度。正如我提到的,我没有MATLAB。所有实验使用Python。我有工作对IVP ode求解器。这给了我,我和R提供模型参数。
现在我有两个数据集。1).Actual数据下载。2).Another从爵士模型组。我也有工作fminsearch Python代码。
对不起,我的无知。
请指导我应该如何进行:回归+最小化+物流近似。
米兰巴蒂斯塔(查看配置文件)
不。模型参数N,钱数,β,γ决心从爵士模型方程通过LSQM最小化fminsearch函数使用。物流近似仅用于计算初始猜测。
米兰巴蒂斯塔(查看配置文件)
w1和w2回归加权总病例和每天的新病例。举个例子,如果你想把所有重量占总病例使用fitVirusCV19 (…, w1, 1)(见fitVirusCV19标题描述)。默认情况下,fitVirusCV19计算三种情况:1)w1 = 1, w2 = 0, 2) w1 = 0, w2 = 1;3 w1 = w2 = 0.5。解决方案中选择一个给最小的N。
Sambath Narayanan(查看配置文件)
我明白先生模型和参数合理。这是我的愚蠢的问题。你使用任何ML / stat。技术
逻辑回归等准确估计模型参数γ爵士,β,钱数,…?
Diegus马丁内斯(查看配置文件)
Sambath Narayanan(查看配置文件)
Diegus马丁内斯(查看配置文件)
我想问你一个问题。权重如何w1和w2的不同吗?我们应该如何修改?的影响是什么?
米兰巴蒂斯塔(查看配置文件)
对于那些只对实现流行病模型感兴趣而不是参数化,即。实际数据,我写了一个示例实现经典的确定性模型,先生,先生们,西,西珥:
//www.tatmou.com/matlabcentral/fileexchange/75321-seirs-epidemic-model
米兰巴蒂斯塔(查看配置文件)
如果N是易感人群人口规模,。然后S0 = N-I0即S0 = 312163 - 27所示。不要把国家人口人口的易感人群。
舜天雪(查看配置文件)
嗨,先生。
谢谢你的工作。有一个问题,当我试图阴谋先生在中国模型估计参数。
我不太熟悉matlab。我做错什么了?如下的代码。
t1 = 1.631;
t2 = 1.406;
N = 312163;
一个= (t1 / N);
b = t2;
S0 = 1393000000;
I0 = 27个;
R0 = 0;
f = @ (t, x)——* x (1) * (2); * x (1) * (2) - b * x (2); b * x (2)];
(t, xa) =数值(f, 112年[0],[27 1393000000 0]);
情节(t, xa (: 1))
抓住
情节(t, xa (:, 2),“k”)
情节(t, xa (:, 3),“r”)
推迟
巴勃罗·里奥斯(查看配置文件)
非常感谢米兰调查疫情的每日预计结束日期发表https://ddi.sutd.edu.sg/。
米兰巴蒂斯塔(查看配置文件)
我不能改变N,因为它是计算。但是人们总是可以的官方数据规模她/他应该是正确的数量和运行仿真。然而,在我的国家,我们执行随机测试日报报道数据的人口和原来很好的估计。
请注意。如果你运行先生与固定数据,说N = 210和R0 = 2,你可能会得到一个非常不切实际的天启的结果。
穆克什Jakhar(查看配置文件)
你好先生,
我很欣赏你的努力工作。
我看了你所有的评论,我从那里得到的答案,
现在我想为我做这个计算区域,所以,我只需要更改数据(datafunction)和命令行让我们必须做一些改变的图形或N和nmax价值。人口呢? ?
谢谢提前
Gesil塞贡多(查看配置文件)
谢谢你的回答。我的观点是,通过这样做,我们可以传播的影响缺乏测试。“非正常死亡”的数量(averge相比前几年)不系与covid-19和其他方法给出了估计约10倍比聚乙烯更受感染的报道。这地方已经感染的数量远高于520 k。我知道你不能使用数据以外的其他官员。我们也不,我们immplicitly做出假设这些数字是与真正的进化成正比。这里的动态显示,我们远离峰值,至少几周,如果不是更多。我对你courious结果与N = 210。亲切的问候。
Md Humayun Kabir(查看配置文件)
谢谢你,现在它的工作. .谢谢你的帮助@milan巴蒂斯塔
米兰巴蒂斯塔(查看配置文件)
今天我运行这个数据:
%计算R0 -联系电话/ 5天的平均水平
关闭所有
清除所有
res (1) = calcR0 (@getDataBangladesh);
% res (1) = calcR0 (@getDataAustria);
% res (2) = calcR0 (@getDataChina);
% res (3) = calcR0 (@getDataFrance);
% res (4) = calcR0 (@getDataGermany);
% res (5) = calcR0 (@getDataItaly);
% res (6) = calcR0 (@getDataSlovenia);
% res (7) = calcR0 (@getDataSpain);
% res (8) = calcR0 (@getDataUK);
% res (9) = calcR0 (@getDataUSA);
流(' % 12 s % 7 s % 7 s % 12 s % 12 s % 12 s \ n”,…
“国家”、“R0’,‘stdR0’,‘N’,‘标准化’,‘nday’);
长度为n = 1: (res)
rr = res (n);
流(' % 12 s % 7.3 f % 7.3 f % 12 d % 12 d % 4 d \ n”,…
rr.country、rr.R0 rr.stdR0,修复(rr.N),修复(rr.stdN),修复(rr.nday));
结束
最后得到这个
国家R0 stdR0 N标准化nday
孟加拉国14 1.739 - 0.809 203205 738152
Md Humayun Kabir(查看配置文件)
孟加拉国
米兰巴蒂斯塔(查看配置文件)
在哪个国家你运行这个程序吗?
Md Humayun Kabir(查看配置文件)
当我运行这个runcalcR0。m文件,它显示了以下错误
错误fitVirusCV19(第483行)
res.tp1 = datestr(地板(tp1));
错误calcR0(34)行
res = fitVirusCV19 (getData,‘天’,n,“plt”,“关闭”);
谁能帮助我?
此外,我使用Matlab 2018 b版本。
谢谢提前
米兰巴蒂斯塔(查看配置文件)
爵士模型有两个内在参数β和γ,从初始条件和两个参数:初始易感人群S0和初始感染I0的数量。因为假定常数人口爵士S0 = N-I0。你可以假设N是全国人口,I0也感染的最初报道数量和比计算γ和β的回归。但事实证明,最好是假设N和I0也是未知数,所以他们通过使用实际数据回归计算。
因为这是程序是用于日常评估,N的变化与新数据和最后的流行,我们估计N是多大。在我看来,一般来说,不能确定实际N经验甚至疫情结束后,因为爵士(模型)只总病例数可观测。
Gesil塞贡多(查看配置文件)
请让我解释我的问题。其他先生,西珥,SEIHURD(等)的努力我看过用整个国家的人口随着N,由于这样的事实,没有特殊限制年龄,种族,性别的感染和传播。这里没有人工锁定到位的过程也会限制易感人群(如发生在中国),这是至关重要的预测过程的结束。什么是模型的基础限制N巴西人口的1/400吗?
米兰巴蒂斯塔(查看配置文件)
页面上的一个引用https://ddi.sutd.edu.sg/表明这个项目,即fitVirusCV19是用于计算。
仓鼠了(查看配置文件)
新手问题。预测是使用Matlab编写脚本吗?
米兰巴蒂斯塔(查看配置文件)
在https://ddi.sutd.edu.sg/每日预计结束日期流行给出的不同的国家。我能算出估计日期计算如下。97%:C (t) = 0.97 * Cend, 99%: C (t) = 0.99 * Cend和结束日期(100%)是一样的一个fitVirusCV19报道1例。
米兰巴蒂斯塔(查看配置文件)
西珥的参数化和SIRS模型不是一项容易的任务作为一个复杂的算法或大量的经验和深入的知识问题的需要估计初始5 +参数值。
米兰巴蒂斯塔(查看配置文件)
我不熟悉Excel即。VB编程和我不知道VB包含一些类似于Matlab的fminsearch函数。
Ziaur拉赫曼(查看配置文件)
米兰巴蒂斯塔,你能请重写代码使用西珥和SIRS模型?我需要为我的学术目的。
谢谢。
塞萨尔外耳奥尔金市中心(查看配置文件)
嗨,我如何在Excel中复制这种模式?我不能下载你的软件在iPad上。
米兰巴蒂斯塔(查看配置文件)
fitVirusCV19计算估计的C (t) = Cend-1流行的条件,即当只有一个感染(使用“打印”,“上”打印此信息)。fitVirusCV19是专为日常流行的评价参数,而非长期预后。我不知道怎样的主人https://ddi.sutd.edu.sg/计算理论结束日期,但是我强烈怀疑这些日期是最后。一个有趣的概率的估计这些日期是有效的。
巴勃罗·里奥斯(查看配置文件)
嗨,米兰,发表在预测的图表曲线https://ddi.sutd.edu.sg/显示了97%、99%和理论结束日期;我怎样才能将它们添加到相同的图表生成这个页面的MATLAB源代码吗?他们可以参数化在某种程度上也显示这三个日期吗?如果不是,你能分享一个代码片段?
鲁本Ruiloba(查看配置文件)
谢谢你的这个工作。我新MATLAB和这是一个伟大的方式来让自己沉浸在它。
米兰巴蒂斯塔(查看配置文件)
xxxx是哪个国家?@getDataxxxxx将产生一个错误。使用例如@getDataFinland芬兰等。
Diegus马丁内斯(查看配置文件)
帅哥,需要一些帮助:
当我运行文件打烊
fitVirusCV19 (@getDataxxxxx‘打印’,‘上’,‘nmax’, 55 e6)
它解决了说:
错误使用圆
太多的输入参数。
错误fitVirusCV19(第590行)
tx2 = sprintf (' % s % g % s % g % s % g % s % g % s % g % s % g % s % g % s % g’,……
有人能帮助我吗?
谢谢提前
米兰巴蒂斯塔(查看配置文件)
日班现在纠正(由于Burak)
米兰巴蒂斯塔(查看配置文件)
从27日的数据。4月,巴西的项目估计N是大约0.52绪。
Gesil塞贡多(查看配置文件)
你怎么在大约052万估计易感人群在巴西吗?
Burak(查看配置文件)
您好,感谢这个伟大的工作!
我没有经验在MATLAB但是我添加新的数据和运行模式。我有一个问题关于图表。如果我没有错,我意识到每天的新病例的数量和每日生长因子值似乎一天之前的病例总数值。总病例数天(t),但新病例数和生长因子的值(t - 1)。
例如,
总病例数4月28日(天):100000
总病例数在4月29日(天):102000
新病例4月29日:2000(但我想模型定义这个值为4月28日)
生长因子4月29日:% 2(新病例一样,这个值在图4月28日)
例如,在本例中,有2000例新病例,4月29日,新病例总数102000年4月29日(日)结束。然而,在图表,病例总数值是4月29日,但新病例数(2000)和生长因子(% 2)值似乎4月28日。我也认为他们应该在同一天总数的情况下,在本例中是4月29日(因为在这一天发现新病例)。
总结:今天当我添加的总病例数的国家和运行模型,我看到今天的新病例数和生长因子在昨天在图表:)
我认为有不同的方法。你会请通知吗?有机会来解决吗?
再次感谢你,
致以最亲切的问候。
米兰巴蒂斯塔(查看配置文件)
你需要MATLAB。你所有的其他问题都回答下面的评论。
Sambath Narayanan(查看配置文件)
伟大的工作。
抱歉问基本问题
我需要MATLAB运行您的包吗?我该如何去如果我要使用这个州在一个国家吗?我看到这个参数称为“人口模型假定一个常数”。这个国家的人口总数吗?如果我运行先生模型——我可以做一个类似的分析吗?需要什么额外的功能?你有文档吗?谢谢你!
米兰巴蒂斯塔(查看配置文件)
β是接触频率,γ是去除频率,1 /γ是去除时间。看到先生的细节模型http://www.maths.usyd.edu.au/u/marym/populations/hethcote.pdf和https://en.wikipedia.org/wiki/Compartmental_models_in_epidemiology
董gretch(查看配置文件)
米兰再次嗨。如果伽马是孤立的平均感染__days后感染。如何解释β?
非常感谢你的答案
米兰巴蒂斯塔(查看配置文件)
实际值是离散值。先生是一个连续的模型,所以不能峰值,但只有一个连续近似模型的实际评估疫情。
Saurabh沙玛(查看配置文件)
谢谢你回答我们所有的查询管理。基本澄清请——基础实绩并预测自动调整。请看到我们激增或中国(武汉例underdeclared之前)。欣赏
米兰巴蒂斯塔(查看配置文件)
回归的结果是总情况下预测曲线C = C (t), t是时间,预测Cend即总病例数。5和1代表5和1例左,即报告的日期是方程的解C (t5) = Cend-5 = > t5和C (t1) = Cend-1 = > t1。
米兰巴蒂斯塔(查看配置文件)
N代表最初的易感人群。N是通过回归分析估计。
董gretch(查看配置文件)
嗨,米兰。是什么意思的结果5例和1例如下面吗?
流行年底截止2020年6月22日(5例)
流行(1例)09年年底- 7 - 2020
旧金山埃斯特拉达(查看配置文件)
感谢分享米兰。我不熟悉mathlab´,但COVID-19估计是一个主要的问题在我的国家和你的估计被用作参考政策制定者在我的国家(危地马拉)。
我有一个非常重要的问题。例子,N,´s在图的顶部相比是非常小的每个国家的总人口,这是为什么呢?N代表什么?如何计算?
你的•皮亚杰将帮助我很多。
对不起为我的蹩脚的英语,我并不想´,粗鲁的声音与我的问题。
米兰巴蒂斯塔(查看配置文件)
爵士人口模型初始人口的易感人群,是回归变量。它不是这个国家的人口。“nmax”选项是使用只有例如易感人群数量计算。比这个国家的人口。当前数据,易感人群对巴西的估计数量约为052万。
丹尼尔CARNEIRO席尔瓦(查看配置文件)
我在使用一个模拟的巴西,但人口,在fitVirusCV19 (@getDataBrazil nmax, 2.1 e10)不更新,我上交所的结果。可能你helpe我吗?谢谢。
米兰巴蒂斯塔(查看配置文件)
改变变量tp0第387行(fitVirusCV19)你的开始日期。
proffsg(查看配置文件)
我们如何调整图形的开始日期,说我们想开始日期从3月5日。
米兰巴蒂斯塔(查看配置文件)
不。这是实际数据的拟合与底层先生模型。
nntun03(查看配置文件)
从一个新手……这是钟形曲线的拟合,并假设右边尾端是大流行的假设结束. . ?谢谢你!
米兰巴蒂斯塔(查看配置文件)
如上所述在免责声明本程序只是用于教学和日常评估和设计不明确的长期预测(没有可信区间的预测曲线和无模型参数统计)。毫无疑问,有更好的模型流行的爵士模型但他们需要各种类型的数据,很难甚至不可能获得。另一个固有的问题是流行病模型非线性所以需要复杂的算法和大量的知识和经验来获得一个合理的估计模型参数。
现在,比较先生和西珥模型让寻找西班牙。今天大约有2.3 e5总病例。模型与数据31.3爵士。预测约1.4 e5情况下4月底,而西珥模型相同的数据预测约4.8 e5病例4月底。https://www.medrxiv.org/content/10.1101/2020.03.27.20045005v3.full.pdf,图10)。先生的预测模型是因此低约60%,而西珥模型的预测高出100%。这种比较是然而不是声称先生比西只有一个警告,我们应该测试各种模型,即。,没有最好或首选的模型。
米兰巴蒂斯塔(查看配置文件)
先生我,维基百科,不加批判地使用R进行恢复。这是误导。实际上,R代表应该删除(https://web.stanford.edu/ jhj1 / teachingdocs / Jones-on-R0.pdf)即类的人民不再传播感染(即他们是孤立的,直到复苏)。因此γ与恢复时间无关。例如,γ= 0.25意味着平均感染后被孤立1/0.25 = 4天左右后感染。
米兰巴蒂斯塔(查看配置文件)
爵士模型只需要一种数据,因为它可以减少到只有一个方程,对R(删除)或C(总病例)。
在爵士模型R代表删除(没有恢复)即可以不再传播疾病感染。为了考虑这些数据,感染人应该知道每天有多少人住院或孤立。
Ahmad Oweis(查看配置文件)
谢谢你的代码。一个问题:我相信代码只使用当前的总情况下作为输入。会更准确,如果我们包括每日恢复情况下假设可以得到这些数据?
米兰巴蒂斯塔(查看配置文件)
使用一个特定国家的函数应该修改runMe。m函数。为例。菲律宾函数变化
fitVirusCV19 (@getDataAustria) fitVirusCV19 (@getDataPhilippines);为阿富汗改变它运行它
fitVirusCV19 (@getDataAfghanistan)。获取当前数据importTotalCases运行。
Saurabh沙玛(查看配置文件)
谢谢非常gud开始,考虑到这是最好的信任模型,可以摄取粒状城市水平的数据。问题像印度这样的大国是其测试的变化,影响。一些城市。孟买人口像纽约几个国家。源数据在github上发现的https://www.covid19india.org/。是nube github所以可能只是复制,我可以使用开发人员在其他论坛使用吗?
Saurabh沙玛(查看配置文件)
滨男(查看配置文件)
谢谢你的有趣的工作!我的问题是这样的。
预测新病例数下降是由于增加了恢复个人因为你的模型是基于一个爵士模型。但在现实世界中,恢复人的数量非常小,几乎可以忽略不计。先生的“R”模型几乎没有工作。在现实世界中,小说病例的减少是由于减少基本再生数R0,是由于锁定和其他努力。R0模型是恒定的。我怀疑它是否适合于模拟基本再生数R0的改变增加了恢复甚至个人有限的单程流行病。
Ramy Oraby(查看配置文件)
有方法指导模型使用伽马数据在0.03 - 0.07之间,这反映的平均报道恢复期COVID-19(14-35天)。对许多国家来说,模型产生高伽马(恢复期较低)。谢谢。
Houssein AYOUB(查看配置文件)
谢谢你分享这个艰苦的工作。我担心使用“先生”模型。首先,我认为COVID-19应该与西珥模型建模而不是先生,有一个潜在的阶段(感染者没有足够的病毒载量检测)。第二,这里使用的SIR模型不考虑年龄结构非常流行的重要推动力。最近的证据表明,感染的易感性是依赖于年龄的。第三,使用的数据诊断病例,但有更多的感染者,他们不是诊断。我认为这是一个严重的限制的估计,因为它影响的预计结束时间为每个国家流行。
我希望作者可以回答这些问题。
非常感谢,
proffsg(查看配置文件)
我试着运行一个特定的国家,菲律宾,但是我有一些错误。我们有一组代码具体的国家?或行代码在运行前需要编辑的文件文件?还需要哪些文件的运行?
伊斯兰教赛义德(查看配置文件)
亲爱的米兰,
你能帮助和发展一个阿富汗吗?
米兰巴蒂斯塔(查看配置文件)
对不起,输入错误:没有非零但负的。
米兰巴蒂斯塔(查看配置文件)
那时我只关注流行尺寸参数。我看着典型值,但我不能找到它或有一个广泛的价值。参数经验和我所知唯一的要求就是零。例如,对于covid19,平均R0的范围从1.5到6.5 (https://academic.oup.com/jtm/article/27/2/taaa021/5735319)。如果平均感染时间大约是3天那么β(接触频率)范围从0.5到2.1现在,爵士模型是非线性的很多解决方案是可行的,和所有给一个“合理”的结果即他们数据吻合。金宝搏官方网站fitVirusCV19函数是寻找一个解决方案,希望为伽马值最低。
Teguh Prasetyo(查看配置文件)
嗨,你能描述可能的α和β大于1你的论文”的最终大小估计冠状病毒流行的爵士模式”表1 ?可能的值,参数大于1 ?不是基于计算,而是基于一个流行的理论。伟大的工作。
米兰巴蒂斯塔(查看配置文件)
γ和β的确切值可以得到函数的结果。例如:res = fitVirusCV19 (@getDataIceland),然后res.gamma res.beta是准确值。倍增时间只有在疫情爆发和计算的指数增长模型(或物流模型)。当流行通过峰值然后倍增时间失去了它的意义。
fitVirusCV19cs的变异函数提供的基督教希弗图轴datetime值变化。
流行的计算结束时(即预计模型只有1感染)不是图上的报道只有打印。图,轴的上限日期作为高峰日期+ 2 x流行加速度时间或者刨丝器,当前日期。
在我看来,模型参数变化,直到满足模型的假设,即我们没有任何新的地方outbrakes易感人群的人口保持不变。
董gretch(查看配置文件)
嗨米兰,有可能有确切值的增长率和感染率在命令窗口。除了最初的倍增时间,当前翻倍也可以计算或另一个图?
谢谢
Ramy Oraby(查看配置文件)
伟大的工作!我有三个笔记。
1)之间的区别是什么‘fitVirusCV19cs’和‘fitVirusCV19’吗?这是什么“CS”
2)结束日期在命令窗口的结束日期不符合图。
3)你如何解释不稳定R0和参数波动(β和γ)?
edklindemann(查看配置文件)
祝贺5.0.0和5.0.1版本。这是杰出的,现在可以比较R_n和R_0(1),感染易感(2)β和γ(3)每天在同一轴上,加上在正态分布增加了利润评估和打1%的障碍!聪明的……加上w1和w2的统计性能,添加R2和dR2。辉煌! ! !
米兰巴蒂斯塔(查看配置文件)
的结果计算k(第356行)可以与虚部一个复数0我。这并不会影响后续的计算。现在,为了防止警告,真正把k = (k);在第356行。
基督教施罗德(查看配置文件)
我得到以下警告现在5.0.0 analyseCV19运行时:
> > analyseCV19 (@getDataIceland);
警告:结肠操作数必须是真正的标量。
在fitVirusCV19 >(第386行)
在analyseCV19(43行)
像往常一样,在这顺便说一句谢谢你继续工作。非常感激!
李之(查看配置文件)
非常感谢!
本的长袍(查看配置文件)
谢谢你的澄清
米兰巴蒂斯塔(查看配置文件)
有数据集之间的差异。例子中使用的数据https://ourworldindata.org/coronavirus-source-data。美国有787752例2020年- 4月21日,22日和825041例- 4月- 2020。因此增加37289例。
米兰巴蒂斯塔(查看配置文件)
基于维基百科的数据可以从预测
https://www.fpp.uni-lj.si/en/research/researh-laboratories-and-the-programme-team/research-programme-team/
本的长袍(查看配置文件)
你是美国号码为4-22-20是不正确的。病例的数量应该是29743 /天(https://en.wikipedia.org/wiki/2020_coronavirus_pandemic_in_the_United_States)。你有病例在37000左右。
优素福Kursat Tuncel(查看配置文件)
伟大的工作!
两个笔记:
1)不需要xlsx转换,MATLAB可以直接读到csv文件,我测试工作。
2)我只是一个更新函数用于数据提示,显示正确的日期和价值。
函数txt = updatefunc (src、事件)
pos =(事件,“位置”);
txt ={['日期:' datestr (pos (1),“dd.mm.yyyy”)],…
['值:' num2str (pos (2), % .f)]};
结束
保存这个updatefunc。目录下的m CV19和调用它
dcm = datacursormode (gcf);
扩张型心肌病。使= '在';
扩张型心肌病。UpdateFcn = @updatefunc;
在任何“datetick”功能。这应该工作。
米兰巴蒂斯塔(查看配置文件)
乐天,创建你的getData函数或填补现有的数据。然后运行runMe。m函数通过函数名可以改变你的函数名。为例。现在在runMe。m是res = fitVirusCV19 (@getDataAustria,“打印”,“上”);。如果你的函数,例如,getDataSwedenA,然后取代res = fitVirusCV19 (@getDataSwedenA,“打印”,“上”);。注意,回归取决于数据和可能失败。
乐天威德纳(查看配置文件)
你好!
我很熟悉这种类型的应用数学和编程,但是我试着运行一个爵士模拟基于数据从两个区域在瑞典,而不是整个国家。也许有可能手动输入数据运行仿真的基础上,而不是国家数据?
谢谢你!
米兰巴蒂斯塔(查看配置文件)
小c先生模型成为物流模型。
SDDI(查看配置文件)
你是怎么做的初始猜测关键参数需要退化?在代码中,我发现下面的线。看起来像爵士的初始猜测参数相关的物流模型?提前感谢你如果你能详细说明如何设置初始值的钱数,N,γ和β~ !
%……对数曲线参数
K0 = b0 (1);
r = b0 (2);
一个= b0 (3);
C0 = K0 / (+ 1);
%……最初的猜测
I0 = C0;
N = 2 * K0;
γ= 2 * r;
β= 1.5 *伽马;
米兰巴蒂斯塔(查看配置文件)
只是运行importTotalCases importData_ourworldindata阿曼也和你会得到数据。然后运行runMe_ow,但在此之前做以下改变= fitVirusCV19 (@ow_getDataOman,“打印”,“上”,“不高兴”,3)。但不要期望太多。在我看来,阿曼的流行是在早期阶段回归,如果它成功了,也许很可疑。
fayeza r(查看配置文件)
谢谢你米兰先生
我希望找到更新阿曼
米兰巴蒂斯塔(查看配置文件)
可能在你们国家流行不能先生所描述的模型。例如,可能发生如果你有新疫情或散射随机数据。也可以,你的流行的原因是接近上限。在这种情况下,名义预报几乎是不可能的,因为实际值位于回归误差。
董gretch(查看配置文件)
你好,米兰,我能问发生了什么在我的结果,因为流行的大小(k)和最终的病例数低于实际的确诊病例?
米兰巴蒂斯塔(查看配置文件)
爵士模型可以减少到1方程。fitVirusCV19总情况下使用C =我+ R C因为数据可用。可以计算年代,我,R先生通过模拟使用最初的三个方程模型和N,β,γ,I0 fitVirusCV19计算函数。另外,年代,ir可由下列公式计算:
S = c, R =γ* N /β*日志(S0 / S), I = c - R, S0 = N-I0;
感染率是根据定义时放慢速度图是被夷为平地。
董gretch(查看配置文件)
嗨,米兰。感染率图可以用来解释曲线是否已经被夷为平地?
阿卜杜Alqahtani(查看配置文件)
非常感谢Mr.Milan。你说描述的模型是爵士模型但我看不到显式方程的年代,我和r . fitVirusCV19 & analyseCV19搜查,但没有发现它。在您的模型中提到你的论文,你说这些方程显然和我跑这个模型成功但结果不是辞职好一样在这个模型。你能让我知道你把这些方程。
米兰巴蒂斯塔(查看配置文件)
快速的解决方案,我建议你把“nmax”选项在analyseCV19两个fitViruseCV18调用函数。举个例子:
res = fitVirusCV19 (plt的getData,‘了’,‘nmax’, 2 e4);
res = fitVirusCV19 (getData,‘天’,n,‘plt’,‘了’,‘nmax’, 2 e4);
基督教施罗德(查看配置文件)
你能添加支持nmax参数an金宝appalyseCV19()吗?分析数据,我的家乡流行大小(Cend)估计,超过其人口40倍一些天,这打破了图表。谢谢!
米兰巴蒂斯塔(查看配置文件)
这几天日本可能是指数增长阶段拟合是可疑的。然而,在今天的数据,拟合很好。我修剪20. 3月的数据。
Hiroshi汤川(查看配置文件)
嗨,米兰先生。我试图跑日本的数量数据2020年4月10日,但它不能得到合适的阴谋。(γ-)的计算
但是在你的网站上herehttps: / /www.fpp.uni-lj.si / en /研究/ researh-laboratories-and-the-programme-team / research-programme-team /
看来你成功获得合适的情节。你能告诉我你怎么得到的情节与2020年4月10日本数据?
罗伯特·Zenteno(查看配置文件)
感谢帮助!这是墨西哥的数据,问候!
//www.tatmou.com/matlabcentral/fileexchange/74992-getdatamex
Bamaarouf奥马尔(查看配置文件)
谢谢文澜先生,
我成功运行您的模型
大卫·弗朗哥(查看配置文件)
谢谢你!
米兰巴蒂斯塔(查看配置文件)
摩洛哥工作正常的数据。
米兰巴蒂斯塔(查看配置文件)
你应该runMeFirst运行。这个函数添加必要的路径。
Bamaarouf奥马尔(查看配置文件)
嗨,我插入一个getdata摩洛哥的函数,如果你感兴趣的人
//www.tatmou.com/matlabcentral/fileexchange/74978-getdatamorocco
Bamaarouf奥马尔(查看配置文件)
谢谢你先生米兰巴蒂斯塔。
很好的工作,但是我有一个问题,当我运行代码”RunMe。m”,它给了我这个错误:
错误使用圆
太多的输入参数。
错误fitVirusCV19(第407行)
res.Ce =圆(Ce ', 0);
我进入getDataMorocco函数在文件夹“数据”。
当我写“> > fitVirusCV19 (@getDataMorocco);“在命令窗口,我得到这个错误:
太多的输入参数。
错误fitVirusCV19(第535行)
tx2 = sprintf (' % s % g % s % g % s % g % s % g % s
% g % s % g % s % g % s % g’,……
谢谢你的帮助
董gretch(查看配置文件)
阿德里亚诺Zanfei(查看配置文件)
你好米兰,我稍微修改了意大利地区的导入功能,和工作好了!我也想加入卡尔曼滤波器进行短期预测。谢谢你的工作!
Hiroshi汤川(查看配置文件)
谢谢你,米兰巴蒂斯塔先生。
我用‘keeplimits datetickik和它工作得很好。
韩国的其他事情,我检查数据,我认为有一个misstype一些数据,但我固定它。
非常感谢。
米兰巴蒂斯塔(查看配置文件)
没有特殊原因,我遵循H.W.的术语Hethcote的文章传染病的数学。
对于那些感兴趣的主要是当前的预测,我们开始新的web页面
https://www.fpp.uni-lj.si/en/research/researh-laboratories-and-the-programme-team/research-programme-team/
维卡斯•沙玛(查看配置文件)
米兰先生你好。请你评论,为什么繁殖数量更改联系电话。Tc的意义,Tr /β和γ。谢谢提前
米兰巴蒂斯塔(查看配置文件)
先生的模型,因为它是众所周知的,可以减少为C =我+ R一个方程。和C(总感染病例)只是所需数据。
董gretch(查看配置文件)
我可以问先生是如何计算的,因为只有被感染的病例输入?
米兰巴蒂斯塔(查看配置文件)
写在描述,该模型是数据驱动的,是一个简单的流行。它对于国家的流行是由检疫即假设模型的实现。它不工作或不工作等都在的情况下延迟爆发(斯洛文尼亚、丹麦、…)或散射数据。有时数据,因此回归,在几天内稳定,有时不是。
轴由函数datetickik控制数据选择“keepticks”。如果你改变这个“keeplimits”你会得到整个数据集。
Hiroshi汤川(查看配置文件)
嗨,Mr.Milan。
很抱歉打扰你了。我成功的结果对日本5.4.2020数据,但是我怀疑这个结果,因为C_end的数量比3.4.2020 increaisng 10倍数据分析结果。你有什么想法?和中国的结果是好的,但日期轴不是显示最新的日期。
我也试图获得阿联酋(迪拜)的情节,但是,曲线不符合实际数据(rmse =南)。你能给我指导来解决这个问题?
谢谢你的进一步援助。
Hiroshi汤川(查看配置文件)
在5.4.2020日本的电话号码是3271。我与包括5.4.2020成功运行它,不过我不让情节。
错误显示,伽马值是负的。我可能会错过一些东西。
米兰巴蒂斯塔(查看配置文件)
注意getDataJapan对日本的数据是不完整的(其28.3.2020结束)。我认为,问题是,你有两个延迟爆发。如果你修剪数据29.2.2020你会得到解决方案。
米兰巴蒂斯塔(查看配置文件)
从一开始调整数据。(数据4.4.2020没问题)。5.4.2020的电话号码是什么?
Hiroshi汤川(查看配置文件)
嗨,米兰。
谢谢你的更新。
我成功运行模型,但如果我包括日本的5 - 4月- 2020年数据,未能获得情节。
我猜,因为γ的值是-。你知道怎么解决这个问题?
谢谢你!
米兰巴蒂斯塔(查看配置文件)
你应该下载total_cases。csv数据
https://covid.ourworldindata.org/data/ecdc/total_cases.csv
戴尔Groutage(查看配置文件)
嗨,米兰,
你做了一个很棒的工作,这个项目在COVID-19 !
我试图运行您的代码的一部分,得到的数据https://ourworldindata.org/coronavirus-source-data
我从——下载csv文件的数据
https://ourworldindata.org/coronavirus-source-data
我然后导入EXCEL作为XLS文件保存到文件夹中
importData_ourworldindata。然后我importData运行。然后我得到错误信息:
错误使用importData(19)行
无法连接表变量“天”和“countriesAndTerritories”,因为他们的类型和细胞的两倍
什么是我做错了吗?
米兰巴蒂斯塔(查看配置文件)
它需要fminsearch函数从优化或统计工具箱。象征性Tbx是可选的,因为fitVirusCV19 lambertw计算函数。
安德里亚Mazzoleni(查看配置文件)
有谁能够运行它在八度?我似乎被困在数值()和它从未终止。
无论如何,对Matlab需要优化,符号和统计工具箱
米兰巴蒂斯塔(查看配置文件)
不,N不是该国的人口。N是一个人口组成的易感人群,感染(I)和恢复(R)。图中的情况是我+ R。它假定N = S +我+ R =常数。所以N约等于易感者的初始大小,因为最初的感染数量很小。当然,这是一个未知的模型(否则我们可以收集易感人群,并将它们放入到检疫)。当没有检疫N可以增加每天(你可能会有一个新的本地疫情插入之外,因此N增加),与检疫检疫它逐步成为一个常数即模型的假设模型更满足,从而变得更适合预测(你每天获得相同的曲线)。
Manthos Vogiatzoglou(查看配置文件)
亲爱的米兰
伟大的工作!不过,有一些我在这里失踪。N是人口的国家,对吗?在所有的例子中N是远远低于实际的人口。这是为什么呢?提前谢谢。
米兰巴蒂斯塔(查看配置文件)
重量不表示“状态”策划(这些只是两个数字)。打印你可以看到它们的值,或者你可以设定readMe中描述他们的价值。在文件夹CV19。
edklindemann(查看配置文件)
嘿,米兰
你能请描述或者如何绘制权重(w1和w2)用于每个仿真?
谢谢
董gretch(查看配置文件)
谢谢你的解释。将考虑调整
米兰巴蒂斯塔(查看配置文件)
在描述说,回归可以失败,特别是在早期阶段的或者有更多的暴发流行。这种情况下的模型是不足够的。有时修剪的初始数据改善回归条件但有时不是。
不同国家的更新数据在上面列出的链接。
董gretch(查看配置文件)
嗨。我得到这个错误在我更新了ow_getDataPhilippines菲律宾。它说
未能获得菲律宾参数。
ini:β= 1.02974γ= 0.686495 N = 5333.72 I0 = 1.78765
钙:β= 0.00876042γ= -0.267236 N = 44594.5 I0 = 83.4033
董gretch(查看配置文件)
菲律宾的更新得到数据吗?
edklindemann(查看配置文件)
https://drive.matlab.com/sharing/5fdab84f a73f - 4 fa5 - 90 - ef - 5 - cc7e8f6ca60
董gretch(查看配置文件)
嗨,它说“无法获取参数对印尼“如何正确的请
Ayad mhamed(查看配置文件)
Ayad mhamed(查看配置文件)
谢谢倒的贡献?
edklindemann(查看配置文件)
嗨,米兰
很棒的工作! ! !
葡萄牙:更新数据(所有学分你:))
//www.tatmou.com/matlabcentral/fileexchange/74802-getdataportugal
//www.tatmou.com/matlabcentral/fileexchange/74803-dc_getdataportugal
//www.tatmou.com/matlabcentral/fileexchange/74804-ow_getdataportugal
Turlough休斯(查看配置文件)
谢谢你!
米兰巴蒂斯塔(查看配置文件)
只是删除它。这是Matlab出口报告……女士的词。
淡水河谷(查看配置文件)
我不能打开´报告命名为“~ portAll200327.docx美元”
Hiroshi汤川(查看配置文件)
谢谢你,米兰先生巴蒂斯塔更新日本。apreciated。
如果不是麻烦你,我希望你这样更新大洋洲的国家我们澳大利亚、新加坡等东南亚,东亚等台湾。
抱歉问你这么多。
希望你健康。
帕特里克•安德森(查看配置文件)
很好的工作,包括广泛的检索功能列表!
我建议增加明确的限制,以及一些图形和演示项目,并将与作者沟通这些建议。
米兰巴蒂斯塔(查看配置文件)
我添加为那些没有SMTbx lamberw函数。请测试程序。我也添加importData函数生成输入函数从ourworldindata total_cases文件。(保存csv xlsx第一!)这些数据首先ow_getDataXXXX功能。
乔奎姆路易斯(查看配置文件)
嗨,它也需要“lambertw需要符号数学工具箱。”
穆罕默德优素福(查看配置文件)
Dwina(查看配置文件)
谢谢你米兰先生
我希望找到更新对印尼
Dwina(查看配置文件)
穆罕默德优素福(查看配置文件)
谢谢你的更新,米兰先生。
我想知道你也可以添加埃及数据
米兰巴蒂斯塔(查看配置文件)
正式宣布疫情流行的和流行病的爆发表明,程序彼此无关。数据时程序报告开始日期足以计算初始近似值。
第二个条形图不是一个累积而是每天增加感染。使用的数据大多是来自维基百科。
维卡斯•沙玛(查看配置文件)
先生,你能指导为什么初始日期你的一些分析选择不同,例如在getDataIndia (),
然而COVID-19 2020/03/03模型开始日期,开始在印度2020年- 1月30日。
第二个查询关于不连续累积情况列。病例发生在不同的日期,但是同样不是反映在getData文件。请您指导和评论呢?
维卡斯•沙玛(查看配置文件)
伟大的工作。
Giacinto Gelli(查看配置文件)
Hiroshi汤川(查看配置文件)
谢谢你的更新,米兰先生。
我想知道你可以添加日本、澳大利亚、新西兰的新数据。
maldiku servinu(查看配置文件)
谢谢你的更新,Mr.Milan。非常感谢
maldiku servinu(查看配置文件)
非常感谢youuu Mr.Milan印尼的数据。高度赞赏。非常感谢你这么多。我每天都将遵循数据。请保持更新(因为我不懂编程和计算机)谢谢你,我期待每天下载你的最新数据。保持良好的工作和保持健康,Mr.Milan。上帝保佑
米兰巴蒂斯塔(查看配置文件)
加拿大的新升级包含数据(多亏了雷米Boisse)、印度尼西亚(由于Maldiku Servinu)和塞尔维亚。
maldiku servinu(查看配置文件)
非常感谢米兰的帮助。我真的新matlab程序。首先,我必须下载应用程序和安装matlab对我的电脑吗?
抱歉问这么一个非常基本的问题,我只是想帮助我身边的人获得的洞察力
雷米Boisse(查看配置文件)
很好的计划,我做了一个加拿大getData函数如果你感兴趣。
https://drive.matlab.com/sharing/d37a7946 bb2f - 4 - ee5 a7b9 f7c3814——01527
米兰巴蒂斯塔(查看配置文件)
Maldiku。只是对印尼的输入数据
https://en.wikipedia.org/wiki/2020_coronavirus_pandemic_in_Indonesia
在一些getData功能和运行程序。
米兰巴蒂斯塔(查看配置文件)
有一个选项(参见函数头)来增加迭代的数量如果输出代码为0,但如果图是好的我就别管这个选项。即错误条件1可以得到增加。的迭代或者我们增加解决方案的宽容。随着迭代次数的增加,解决方案可能会分道扬镳。
maldiku servinu(查看配置文件)
你好,米兰,这是非常有趣的,我真的很感激你所做的事。真正帮助我们估计或预测这次大流行。
你介意让我的国家印度尼西亚,好吗?会非常感激。谢谢
基督教施罗德(查看配置文件)
打印结果,这个输出“退出条件(1 =好)”;应该是“0 =好吧”?
米兰巴蒂斯塔(查看配置文件)
好的我明白了,你没有我的代码运行但约书亚麦基版本的代码。
Suksan Suwanarat(查看配置文件)
出色的工作,但当我运行代码给我这个错误:
无法识别的属性“PreserveVariableNames”类
“matlab.io.text.DelimitedTextImportOptions”。
错误fitVirusCV19v3(第132行)
选择。PreserveVariableNames = true;
基督教施罗德(查看配置文件)