文本分析工具箱
分析和建模文本数据

文本分析工具箱™为预处理、分析和建模文本数据提供了算法和可视化。使用工具箱创建的模型可用于情感分析、预测维护和主题建模等应用程序。
文本分析工具箱包括用于处理来自设备日志、新闻源、调查、操作员报告和社交媒体等源的原始文本的工具。您可以从流行的文件格式中提取文本,预处理原始文本,提取单个单词,将文本转换为数字表示,并构建统计模型。
使用诸如LSA、LDA和word embeddings等机器学习技术,您可以从高维文本数据集中找到集群并创建特性。使用文本分析工具箱创建的特性可以与来自其他数据源的特性组合在一起,以构建利用文本、数字和其他类型数据的机器学习模型。
开始:

提取文本数据
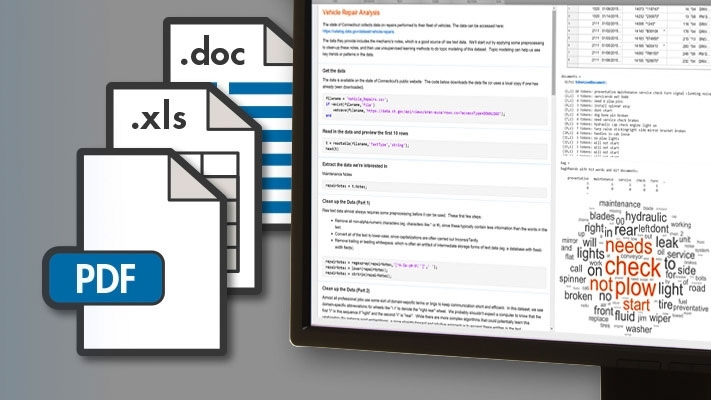
将文本数据导入MATLAB®从单个文件或大型文件集合,包括PDF、HTML和Microsoft®词®和Excel®文件。

从Microsoft Word文档集合中提取文本。

文本散点图显示使用字体大小和颜色的单词的相对频率。

清洁文本数据
应用高级过滤函数来删除无关的内容,如url、HTML标记、标点符号和正确的拼写。

简化原始文本(左)来处理最有意义的单词(右)。


财务图表和技术指标。

识别并可视化模型中最频繁出现的单词。
字嵌入和编码
训练单词嵌入模型,如word2vec连续单词包(CBOW)和跳跃图模型。进口预训练模型,包括fastText和手套。

使用单词嵌入在文本散点图中可视化集群。
主题建模
使用机器学习算法(如潜在的Dirichlet分配(LDA)和潜在语义分析(LSA))发现和可视化大组文本数据中的潜在模式、趋势和复杂关系。

确定风暴报告数据中的主题。

从文本中提取摘要。
利用文本数据进行深度学习
进行情绪分析和分类深度学习长短时记忆网络(LSTMs)等网络。

识别预测积极和消极情绪的词汇。
文本分类
使用单词嵌入对文本描述进行分类,可以通过深度学习识别文本的类别。

训练一个深度神经网络对文本数据进行分类。

使用简·奥斯汀的文本生成《傲慢与偏见》和一个深度学习的LSTM网络。
文档摘要
从文本中提取摘要
文档的重要性
使用TextRank、LexRank和最大边际相关性(MMR)评估文本的重要性
文档相似
使用BM25、余弦相似度、BLEU或ROUGE评分算法评估文本相似度
拼写校正
英语、德语和韩语文本的正确拼写
看到发布说明了解这些特性和相应功能的详细信息。

情绪分析与深度学习
分析实时Twitter数据的情绪,以理解如何理解给定的术语。

有问题吗?
联系Sohini Sarkar,文本分析工具箱技术专家