比较LDA求解器
此示例显示如何通过比较适合的良好和适合模型所需的时间来比较潜在的Dirichlet分配(LDA)求解器。
导入文本数据
使用Arxiv API导入来自数学论文的一组摘要和类别标签。使用使用的记录数指定要导入的记录数进口量变量。请注意,ARXIV API是限于在一次查询1000篇文章的速率,并且需要在请求之间等待。
Importsize = 50000;
导入第一组记录。
URL =.“https://export.arxiv.org/oai2?verb=listrecords”+......“&set = math”+......“&metadataprefix = Arxiv”;选项= weboptions('超时',160);代码= Webrabread(URL,选项);
解析返回的XML内容并创建一个数组htmltree.包含记录信息的对象。
树= htmltree(代码);子树= FindElement(树,“记录”);numel(子树)
在达到所需金额之前,迭代地导入更多的记录块,或者没有更多的记录。继续从剩余的位置导入记录,使用重新计算从上一个结果的属性。要遵循Arxiv API施加的速率限制,请使用每次查询之前添加20秒的延迟暂停功能。
而numel(子树)“恢复”);如果isempty(子转家救济)休息结束resumpathtToken = extracthtmltext(子转家索取);URL =.“https://export.arxiv.org/oai2?verb=listrecords”+......“&ResumpathtToken =”+ resumplateToken;暂停(20)代码= Webrabread(URL,选项);树= htmltree(代码);子树= [子学位;findelement(树,“记录”)];结束
提取和预处理文本数据
从解析的HTML树中提取摘要和标签。
找到“<摘要>”元素使用Fedelement.功能。
subtreabstract = htmltree(“);对于i = 1:数量(子树)子群(i)= findelement(子树(i),“摘要”);结束
使用包含摘要的子树中提取文本数据extracthtmltext.功能。
textdata = extracthtmltext(子树abstract);
随机留出30%的文件以进行验证。
numdocuments = numel(textdata);cvp = cvpartition(numfocuments,'持有',0.1);TextDataTrain = TextData(培训(CVP));TextDataValidation = TextData(测试(CVP));
使用该功能授权和预处理文本数据PreprocessText.在此示例结束时列出。
documentstrain = preprocesstext(textdataTrain);documentsvalidation = preprocesstext(textdatavalidation);
从培训文档创建一个单词袋式模型。删除总共出现超过两次的单词。删除包含没有单词的任何文件。
bag = bagofwords(DocumentStrain);袋= removeinfreqwinds(袋子,2);BAG = RoverimementyDocuments(袋);
对于验证数据,从验证文档创建一个单词袋式模型。您无需从valigaiton数据中删除任何单词,因为在拟合的LDA模型中出现的任何单词都会自动忽略。
ValidationData = BagofWords(DocumentSvalidation);
适合和比较模型
对于每个LDA求解器,适合具有40个主题的模型。为了在相同轴上绘制结果时区分求解器,针对每个求解器指定不同的线属性。
numtopics = 40;solvers = [“cgs”“avb”“cvb0”“Savb”];线条= [“+ - ”“* - ”“x-”“O-”];
使用每个求解器适合LDA模型。对于每个求解器,指定初始主题浓度1,以每次数据通过一次验证模型,并不适合主题集中参数。使用数据FitInfo.适合LDA模型的性能,绘制验证困惑和经过的时间。
默认情况下,随机求解器使用Mini-Batch大小为1000,并每10个迭代验证模型。对于此求解器,要每次数据通过一次模型,请将验证频率设置为CEIL(numobservations / 1000),在哪里numobservations.是培训数据中的文件数。对于其他求解器,将验证频率设置为1。
对于随机求解器不评估验证困惑的迭代,随机求解器报告南当FitInfo.财产。要绘制验证困惑,请从报告的值中删除NANS。
numobservations = bag.numdocuments;figure对于i = 1:磁性(求解器)求解器=溶剂(i);LinesPec = LinesPecs(i);如果Solver ==.“Savb”numitrationsperdatapass = ceil(numobservations / 1000);别的numiterationsperdatapass = 1;结束mdl = fitlda(袋子,numtopics,......'求解',解决者,......'initialtopicconcentration',1,......'fittopicconcordration',假,......'vightationdata',validationdata,......'验证职业',numiterationsperdatapass,......'verbose',0);历史= mdl.fitinfo.history;TimeElapped = History.TimesIncestart;ValidationPerplexity = History.ValidationPerpleity;%删除NANS。IDX = ISNAN(验证性分解);时态(IDX)= [];验证性分解性(IDX)= [];绘图(定期,验证分布,线路销料)保持上结束hold关闭Xlabel(“经过时间的时间”)ylabel(“验证困惑”)ylim([0 inf])传奇(求解器)
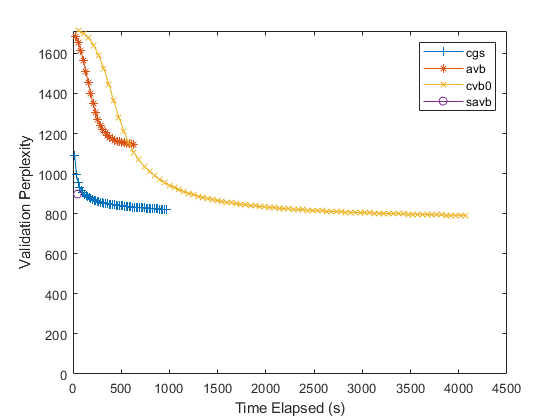
对于随机求解器,只有一个数据点。这是因为该求解器通过一次输入数据一次。要指定更多数据传递,请使用'datapasslimit'选项。对于批量溶剂(“cgs”那“avb”,和“cvb0”),要指定用于适合模型的迭代次数,请使用'iterationlimit'选项。
较低的验证困惑表明更好。通常,求解器“Savb”和“cgs”迅速收敛到良好的契合。求解器“cvb0”可能会收敛到更好的合适,但它可能需要更长的时间来融合。
对于FitInfo.财产,呢菲达函数估计从文档概率的验证困惑以每份文档主题概率的最大似然估计。这通常更快地计算,但不能比其他方法更准确。或者,使用该计算验证困惑logp.功能。此函数计算更准确的值,但运行可能需要更长时间。有关用于使用的示例来显示如何计算困惑logp.,看看从单词计数矩阵计算文档日志概率。
预处理功能
功能PreprocessText.执行以下步骤:
使用授权文本
令人畏缩的鳕文。使用的单词释放
正常化字。使用擦除标点符号
侵蚀。删除使用的停止单词列表(例如“和”,“和”和“该”)的列表
Removestopwords.。使用2或更少的字符删除单词
removeshortwords.。使用15个或更多字符删除单词
removelongwords.。
功能文档= preprocessText(TextData)%标记文本。文档= tokenizeddocument(textdata);%lemmatize单词。文档= addpartofspeechdetails(文件);文档= rangerizewords(文档,“风格”那'lemma');%擦除标点符号。文件=侵蚀(文件);%删除停止单词列表。文档= Removestopwords(文件);%用2个或更少的字符删除单词,以及15或更大的单词%字符。文档= RemoveShortwords(文件,2);文件= removelongwords(文件,15);结束
另请参阅
addpartofspeechdetails.|Bagofwords.|侵蚀|菲达|Ldamodel.|logp.|正常化字|删除程序|removeinfrequentwords.|removelongwords.|removeshortwords.|Removestopwords.|令人畏缩的鳕文|WordCloud.
相关主题
您还可以从以下列表中选择一个网站:
