wordcloud
从文本、词袋模型、词袋-n-grams模型或LDA模型创建词云图
语法
描述
文本分析工具箱™扩展的功能wordcloud(MATLAB®)函数。它增加了对直接从金宝app字符串数组创建词云的支持,以及对从词袋模型、n-gram模型和LDA主题创建词云的支持。如果未安装文本分析工具箱,请参见wordcloud.
wordcloud (从类别数组的元素创建一个词云图C)C使用频率计数。
wordcloud (___,指定附加的名称,值)WordCloudChart属性使用一个或多个名称-值对参数。
wordcloud (在指定的图形、面板或制表符中创建字云父,___)父.
wc= wordcloud (___)WordCloudChart对象。使用wc在创建词云之后修改它的属性。有关属性列表,请参见WordCloudChart属性.
例子
从文本数据创建文字云
将文本从sonnets.txt使用extractFileText并展示第一首十四行诗的文本。
str = extractFileText (“sonnets.txt”);extractBefore (str,“二世”)
[诗歌]莎士比亚十四行诗一我们希望从最美丽的生灵身上生长,这样美丽的玫瑰就永远不会凋谢,但就像成熟的玫瑰随着时间的流逝而凋谢一样,他的娇嫩的继承人也可以记住他:可是你,只盯着自己明亮的眼睛,把自己的物质燃料填满你的火焰,把富足的地方变成饥荒,把你自己当作敌人,把你可爱的自己弄得太残酷:你现在是这世界的新鲜的装饰品,是这绚丽春天的唯一使者,把你的满足埋在你的花蕾里,温柔的粗人把你的吝啬浪费掉:可怜这世界吧,否则这个贪吃的人,要用坟墓和你来吃掉这世界的本分。”
将十四行诗中的单词显示在单词云中。
图wordcloud (str);
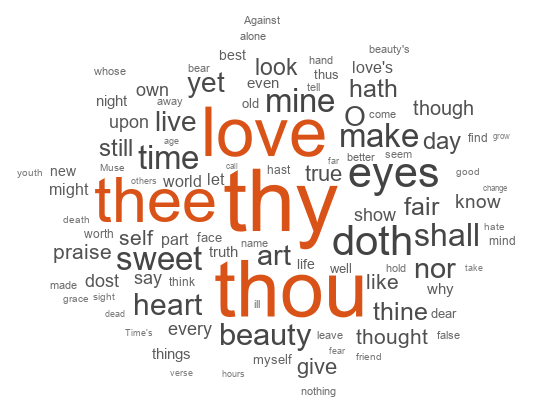
从令牌化文档创建词云
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
使用单词云可视化文档。
图wordcloud(文件);
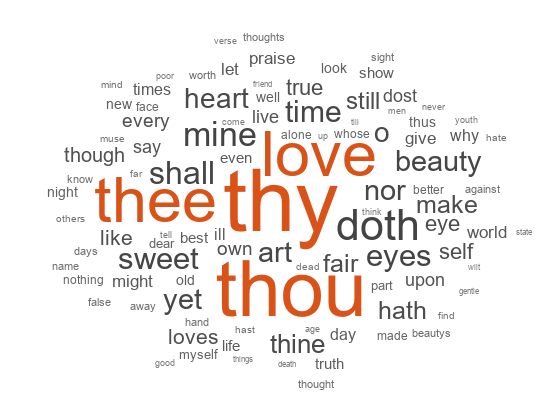
从词汇袋模型创建词汇云
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
使用单词云可视化单词袋模型。
图wordcloud(袋);
从表创建字云
加载示例数据sonnetsTable.表资源描述包含变量中的单词列表词,以及变量中相应的频率计数数.
负载sonnetsTable头(台)
ans =8×2表字数 ___________ _____ {''' 这‘}{“阿门”}1{“公平”}2{“反抗}{“自}1{“这种‘}2{“你}{“因此}1
使用wordcloud.属性指定单词和相应的单词大小词和数变量分别。
图wordcloud(资源描述,“词”,“数”);标题(“十四行诗词云”)

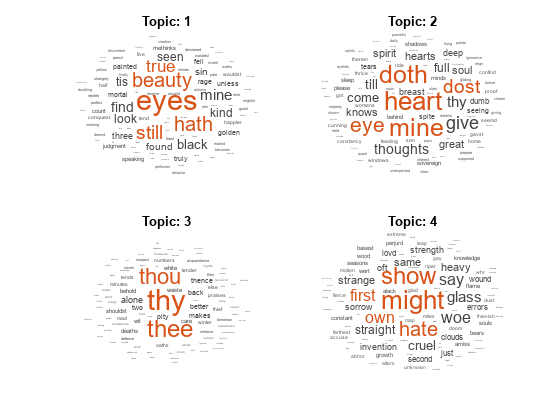
创建词云从LDA主题
要重现本例中的结果,请设置rng来“默认”.
rng (“默认”)
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
拟合具有20个主题的LDA模型。要抑制verbose输出,请设置“详细”为0。
20岁的mdl = fitlda(包“详细”, 0)
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopicprobability: [1x20 double] documenttopicprobability: [154x20 double] documenttopicprobability: [154x20 double] topicwordprobability: [3092x20 double]
使用词云将前四个主题形象化。
数字为topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx);标题(主题:“+ topicIdx)结束
输入参数
str- - - - - -输入文本
字符串数组|特征向量|字符向量的单元格数组
输入文本,指定为字符串数组、字符向量或字符向量的单元格数组。
对于字符串输入,wordcloud和wordCloudCounts函数使用英语、日语、德语和韩语标记化、停止单词删除和单词规范化。
例子:["一个短文档的例子";"第二个短文档"]
数据类型:字符串|字符|细胞
文档- - - - - -输入文档
tokenizedDocument数组
输入文档,指定为tokenizedDocument数组中。
wordVar- - - - - -表变量字数据
字符串标量|特征向量|数字索引|逻辑向量
字数据的表变量,指定为字符串标量、字符向量、数字索引或逻辑向量。
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64|逻辑|字符|字符串
sizeVar- - - - - -表变量大小数据
字符串标量|特征向量|数字索引|逻辑向量
用于大小数据的表变量,指定为字符串标量、字符向量、数字索引或逻辑向量。
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64|逻辑|字符|字符串
单词- - - - - -输入单词
字符串向量|字符向量的单元格数组
输入字,指定为字符串向量或字符向量的单元格数组。
数据类型:字符串|细胞
sizeData- - - - - -字大小数据
数值向量
字大小数据,指定为数字向量。
数据类型:单|双|int8|int16|int32|int64|uint8|uint16|uint32|uint64
C- - - - - -输入分类数据
分类数组
输入分类数据,指定为分类数组。函数绘制的每个唯一元素C大小对应于histcounts (C).
数据类型:分类
袋- - - - - -输入模型
bagOfWords对象|bagOfNgrams对象
输入bag-of-words或bag-of-n-grams模型,指定为bagOfWords对象或一个bagOfNgrams对象。如果袋是一个bagOfNgrams对象,则该函数将每个n-gram视为单个单词。
ldaMdl- - - - - -输入LDA模型
ldaModel对象
输入LDA模型,指定为ldaModel对象。
topicIdx- - - - - -LDA主题索引
非负整数
LDA主题索引,指定为非负整数。
父- - - - - -父
数字|面板|选项卡
指定为图形、面板或制表符的父级。
名称-值对的观点
指定可选的逗号分隔的对名称,值参数。的名字参数名和价值为对应值。的名字必须出现在引号内。可以以任意顺序指定多个名称和值对参数Name1, Value1,…,的家.
“HighlightColor”、“蓝”指定突出显示颜色为蓝色。
的WordCloudChart这里列出的属性只是一个子集。有关完整列表,请参见WordCloudChart属性.
“MaxDisplayWords”- - - - - -显示的最大字数
One hundred.(默认)|非负整数
要显示的最大字数,指定为非负整数。软件显示MaxDisplayWords最大的词。
“颜色”- - - - - -字的颜色
(0.2510 0.2510 0.2510)(默认)|RGB值|包含颜色名称的字符向量|矩阵
字颜色,指定为RGB三元组、包含颜色名称的字符向量或N3矩阵N为长度WordData.如果颜色是一个矩阵,那么每一行对应于一个RGB三元组,对应于WordData.
RGB三联体和十六进制颜色代码在指定自定义颜色时很有用。
RGB三元组是一个由三个元素组成的行向量,其元素指定颜色的红色、绿色和蓝色组件的强度。强度必须在这个范围内
[0, 1];例如,(0.4 0.6 0.7).十六进制颜色代码是以哈希符号开头的字符向量或字符串标量(
#),然后是3个或6个十六进制数字,其范围可以是0来F.这些值不区分大小写。因此,颜色是代码“# FF8800”,“# ff8800”,“# F80”,“# f80”是等价的。
或者,您可以通过名称指定一些常见的颜色。该表列出了已命名的颜色选项、等价的RGB三联体和十六进制颜色代码。
| 颜色名称 | 短名称 | RGB值 | 十六进制颜色代码 | 外观 |
|---|---|---|---|---|
“红色” |
“r” |
(1 0 0) |
“# FF0000” |
|
“绿色” |
‘g’ |
(0 1 0) |
“# 00 ff00” |
|
“蓝” |
“b” |
(0 0 1) |
“# 0000 ff” |
|
“青色” |
“c” |
(0 1 1) |
“# 00飞行符” |
|
“红色” |
“米” |
(1 0 1) |
“#就” |
|
“黄色” |
“y” |
(1 1 0) |
“# FFFF00” |
|
“黑” |
“k” |
(0 0 0) |
# 000000的 |
|
“白色” |
' w ' |
(1 1 1) |
“# FFFFFF” |
|
以下是MATLAB在许多类型的绘图中使用的默认颜色的RGB三联体和十六进制颜色代码。
| RGB值 | 十六进制颜色代码 | 外观 |
|---|---|---|
[0 0.4470 - 0.7410) |
“# 0072 bd” |
|
(0.8500 0.3250 0.0980) |
“# D95319” |
|
(0.9290 0.6940 0.1250) |
“# EDB120” |
|
(0.4940 0.1840 0.5560) |
“# 7 e2f8e” |
|
(0.4660 0.6740 0.1880) |
“# 77 ac30” |
|
(0.3010 0.7450 0.9330) |
“# 4 dbeee” |
|
(0.6350 0.0780 0.1840) |
“# A2142F” |
|
例子:“蓝”
例子:(0 0 1)
“HighlightColor”- - - - - -词高亮颜色
(0.8510 0.3255 0.0980)(默认)|RGB值|包含颜色名称的字符向量
字高亮颜色,指定为RGB三元组或包含颜色名称的字符向量。软件会用这种颜色突出最大的单词。
RGB三联体和十六进制颜色代码在指定自定义颜色时很有用。
RGB三元组是一个由三个元素组成的行向量,其元素指定颜色的红色、绿色和蓝色组件的强度。强度必须在这个范围内
[0, 1];例如,(0.4 0.6 0.7).十六进制颜色代码是以哈希符号开头的字符向量或字符串标量(
#),然后是3个或6个十六进制数字,其范围可以是0来F.这些值不区分大小写。因此,颜色是代码“# FF8800”,“# ff8800”,“# F80”,“# f80”是等价的。
或者,您可以通过名称指定一些常见的颜色。该表列出了已命名的颜色选项、等价的RGB三联体和十六进制颜色代码。
| 颜色名称 | 短名称 | RGB值 | 十六进制颜色代码 | 外观 |
|---|---|---|---|---|
“红色” |
“r” |
(1 0 0) |
“# FF0000” |
|
“绿色” |
‘g’ |
(0 1 0) |
“# 00 ff00” |
|
“蓝” |
“b” |
(0 0 1) |
“# 0000 ff” |
|
“青色” |
“c” |
(0 1 1) |
“# 00飞行符” |
|
“红色” |
“米” |
(1 0 1) |
“#就” |
|
“黄色” |
“y” |
(1 1 0) |
“# FFFF00” |
|
“黑” |
“k” |
(0 0 0) |
# 000000的 |
|
“白色” |
' w ' |
(1 1 1) |
“# FFFFFF” |
|
以下是MATLAB在许多类型的绘图中使用的默认颜色的RGB三联体和十六进制颜色代码。
| RGB值 | 十六进制颜色代码 | 外观 |
|---|---|---|
[0 0.4470 - 0.7410) |
“# 0072 bd” |
|
(0.8500 0.3250 0.0980) |
“# D95319” |
|
(0.9290 0.6940 0.1250) |
“# EDB120” |
|
(0.4940 0.1840 0.5560) |
“# 7 e2f8e” |
|
(0.4660 0.6740 0.1880) |
“# 77 ac30” |
|
(0.3010 0.7450 0.9330) |
“# 4 dbeee” |
|
(0.6350 0.0780 0.1840) |
“# A2142F” |
|
例子:“蓝”
例子:(0 0 1)
“形状”- - - - - -字云形状
“椭圆”(默认)|“矩形”
字云图的形状,指定为“椭圆”或“矩形”.
例子:“矩形”
输出参数
更多关于
你也可以从以下列表中选择一个网站:
