bagOfWords
Bag-of-words模型
创建
描述
袋= bagOfWords
袋= bagOfWords (uniqueWords,计数)uniqueWords相应的频率计入计数.
输入参数
属性
对象的功能
编码 |
将文档编码为单词或n元计数矩阵 |
tfidf |
术语频率-反文档频率(tf-idf)矩阵 |
topkwords |
单词袋模型或LDA主题中最重要的单词 |
addDocument |
将文档添加到bag-of-words或bag-of-n-grams模型 |
removeDocument |
从单词袋或n-gram袋模型中删除文档 |
removeEmptyDocuments |
从标记化的文档数组、单词包模型或n-gram包模型中删除空文档 |
removeWords |
从文档或词袋模型中删除选定的词 |
removeInfrequentWords |
从单词袋模型中删除低计数的单词 |
加入 |
组合多个bag-of-words或bag-of-n-grams模型 |
wordcloud |
从文本、词袋模型、词袋-n-grams模型或LDA模型创建词云图 |
例子
创建Bag-of-Words模型
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
查看前10个单词和它们的总数。
台= topkwords(袋,10)
台=10×2表词数_______ _____ "你的" 281 "你" 234 "爱" 162 "你" 161 "做" 88 "我的" 63 "应该" 59 "眼睛" 56 "甜蜜" 55 "时间" 53
从独特的单词和计数创建袋词模型
创建一个词袋模型使用一个独特的词的字符串数组和一个词计数矩阵。
uniqueWords = [“一个”“一个”“另一个”“例子”“最终”“句子”“第三”];数量= (...1 2 0 1 0 1 0 0;0 0 3 1 0 4 0;1 0 0 5 0 3 1;1 0 0 1 7 0 0];袋= bagOfWords (uniqueWords计数)
bag = bagOfWords with properties: Counts: [4x7 double] Vocabulary: [1x7 string] NumWords: 7 NumDocuments: 4
使用文件数据存储从多个文件导入文本
如果您的文本数据包含在一个文件夹中的多个文件中,那么您可以使用文件数据存储将文本数据导入MATLAB。
为示例十四行诗文本文件创建文件数据存储。示例十四行诗有文件名"exampleSonnetN.txt”,N是十四行诗的编号。指定要读取的函数extractFileText.
readFcn = @extractFileText;fds = fileDatastore (“exampleSonnet * . txt”,“ReadFcn”readFcn)
/tp706790c2/textanalytics-ex73762432/exampleSonnet1.txt';“…/ tp706790c2 / textanalytics-ex73762432 / exampleSonnet2.txt”;“…/ tp706790c2 / textanalytics-ex73762432 / exampleSonnet3.txt”……{'/tmp/Bdoc21a_1606923_11597/tp706790c2/textanalytics-ex73762432'} UniformRead: 0 ReadMode: 'file' BlockSize: Inf PreviewFcn: @extractFileText SupportedOutputFormats: 金宝app[1x16 string] ReadFcn: @extractFileText AlternateFileSystemRoots: {}
创建一个空的单词袋模型。
袋= bagOfWords
bag = bagOfWords with properties: Counts: [] Vocabulary: [1x0 string] NumWords: 0 NumDocuments: 0
循环遍历数据存储中的文件并读取每个文件。标记每个文件中的文本并将文档添加到袋.
而Hasdata (fds) STR = read(fds);文档= tokenizedDocument (str);袋= addDocument(袋、文档);结束
查看更新的单词袋模型。
袋
bag = bagOfWords with properties: Counts: [4x276 double] Vocabulary: [1x276 string] NumWords: 276 NumDocuments: 4
从词袋模型中移除停止词
通过输入停止词列表来从词袋模型中删除停止词removeWords.停止词是像“a”、“the”和“in”这样的词,这些词在分析之前通常会从文本中删除。
文件= tokenizedDocument ([一个短句的例子第二个短句]);袋= bagOfWords(文件);stopWords newBag = removeWords(袋)
newBag = bagOfWords with properties: Counts: [2x4 double] Vocabulary: ["example" "short" "sentence" "second"] NumWords: 4 NumDocuments: 2
单词袋模型中最常见的单词
创建一个单词袋模型中最常用单词的表。
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
找出最常用的五个单词。
T = topkwords(袋);
在模型中找出前20个单词。
k = 20;T = topkwords(袋、k)
T =20×2表词数________ _____ "你" 281 "你" 234 "爱" 162 "你" 161 "做" 88 "我" 63 "将" 59 "眼睛" 56 "甜蜜" 55 "时间" 53 "美" 52 "或"艺术" 51 "但" 51 " "心" 50⋮
创建Tf-idf矩阵
从词汇袋模型创建术语频率-反文档频率(tf-idf)矩阵。
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
创建一个tf-idf矩阵。查看前10行和列。
M = tfidf(袋);完整的(M (1:10, 1:10))
ans =10×103.6507 4.3438 2.7344 3.6507 4.3438 2.2644 3.2452 3.8918 2.4720 2.5520 4.5287 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2.5520 2.2644 2.2644 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2.2644 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2.7344 2.2644 2.5520 0 0 0 0 0 0 0 0 0 0 0 0
从词汇袋模型创建词汇云
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
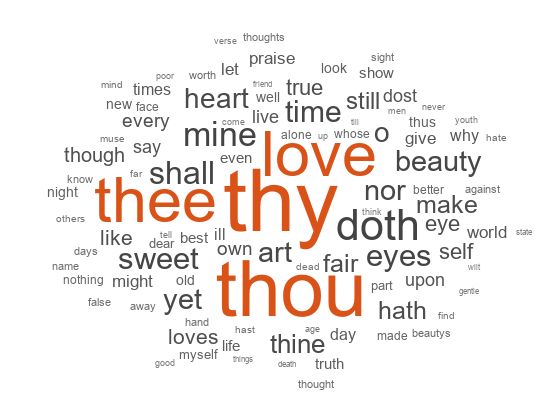
使用单词云可视化单词袋模型。
图wordcloud(袋);
并行创建词袋模型
如果您的文本数据包含在一个文件夹中的多个文件中,那么您可以导入文本数据并使用并行创建单词包模型parfor.如果您安装了并行计算工具箱™,则parfor循环以并行方式运行,否则,它以串行方式运行。使用加入将一组词汇袋模型组合成一个模型。
从文件集合创建单词袋模型。示例十四行诗有文件名"exampleSonnetN.txt”,N是十四行诗的编号。获取文件的列表和他们的位置使用dir.
fileLocation = fullfile (matlabroot,“例子”,“textanalytics”,“exampleSonnet * . txt”);fileInfo = dir (fileLocation)
fileInfo = 0x1带有字段的空结构数组:name folder date bytes isdir datenum
初始化一个空的单词包模型,然后循环遍历这些文件并创建一个单词包模型数组。
袋= bagOfWords;numFiles =元素个数(fileInfo);parfori = 1:numFiles f = fileInfo(i);文件名= fullfile (f.folder f.name);textData = extractFileText(文件名);文档= tokenizedDocument (textData);袋(我)= bagOfWords(文档);结束
结合单词袋模型使用加入.
袋=加入(袋)
bag = bagOfWords with properties: Counts: [] Vocabulary: [1x0 string] NumWords: 0 NumDocuments: 0
提示
如果您打算为您的工作使用一个保留的测试集,那么在使用之前对文本数据进行分区
bagOfWords.否则,词汇袋模型可能会使你的分析产生偏差。
另请参阅
addDocument|bagOfNgrams|编码|removeDocument|removeEmptyDocuments|removeInfrequentWords|removeWords|tfidf|tokenizedDocument|topkwords
你也可以从以下列表中选择一个网站:
