主要内容
文本数据准备
将文本数据导入MATLAB®并对其进行预处理以进行分析
职能
话题
进口
这个例子展示了如何从文本、HTML、Microsoft®Word、PDF、CSV和Microsoft Excel®文件中提取文本数据,并将其导入MATLAB®进行分析。
此示例显示如何解析HTML代码并从特定元素中提取文本内容。
为各种文本分析任务发现数据集。
预处理
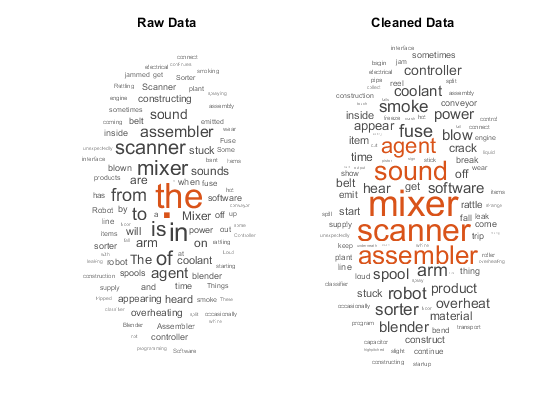
此示例显示如何创建清除和预处理文本数据进行分析的函数。
这个例子展示了如何分析包含表情符号的文本数据。
此示例显示如何使用HUNSPELL纠正文档中的拼写。
这个示例展示了如何创建一个Hunspell扩展字典来进行拼写校正。
此示例显示如何使用编辑距离搜索器和已知单词的词汇进行校正拼写。
语言支持金宝app
有关为其他语言使用文本分析工具箱功能的信息。
文本分析工具箱中日语支持的信息。金宝app
这个示例展示了如何使用主题模型导入、准备和分析日语文本数据。
关于文本分析工具箱中的德语支持的信息。金宝app
这个示例展示了如何使用主题模型导入、准备和分析德语文本数据。
特色例子


你也可以从以下列表中选择一个网站:
