fitlda
拟合潜在狄利克雷分配(LDA)模型
描述
潜在的dirichlet分配(LDA)模型是一个主题模型,它在主题中集合的文件和Infers Word概率中的基础主题。如果模型适合使用袋式革袋模型,那么软件将N-GRAM视为单独的单词。
mdl= FITLDA(袋,numtopics.)numtopics.单词袋或n-gram袋模型的主题袋.
mdl= FITLDA(计数,numtopics.)
例子
符合LDA模型
要重现本例中的结果,请设置rng来'默认'.
RNG('默认')
加载示例数据。该文件sonnetspreprocessed.txt.txt.包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetspreprocessed.txt.txt.,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
使用袋式模型使用bagOfWords.
BAG = BAGOFWORDS(文件)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
适合具有四个主题的LDA模型。
numTopics = 4;numTopics mdl = fitlda(袋)
初始主题分配的采样时间为0.142331秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 0.41 | 1.000 | 1.215 e + 03 | | 0 | | 1 | 0.02 | 1.0482 e-02 e + 03 | 1.128 | 1.000 | 0 | | 2 | 0.02 | 1.7190 e 03 e + 03 | 1.115 | 1.000 | 0 | | 3 | 0.02 | 4.3796 e-04 e + 03 | 1.118 | 1.000 | 0 | | 4 | 0.01 | 9.4193 e-04 e + 03 | 1.111 | 1.000 | 0 | | 5 | 0.02 | 3.7079 e-04 e + 03 | 1.108 | 1.000 | 0 | | 6 | 0.01 | 9.5777 e-05 e + 03 | 1.107 | 1.000 | 0 |=====================================================================================
mdl = ldaModel with properties: 1 WordConcentration: 1 TopicConcentration: 1 corpustopicprobability: [0.2500 0.2500 0.2500 0.2500 0.2500] documenttopicprobability: [154x4 double] topicwordprobability: [3092x4 double]
使用Word云可视化主题。
数字为TopicIDX = 1:4子图(2,2,TopicIDX)WordCloud(MDL,TopicIDX);标题(“话题: ”+ topicidx)结束
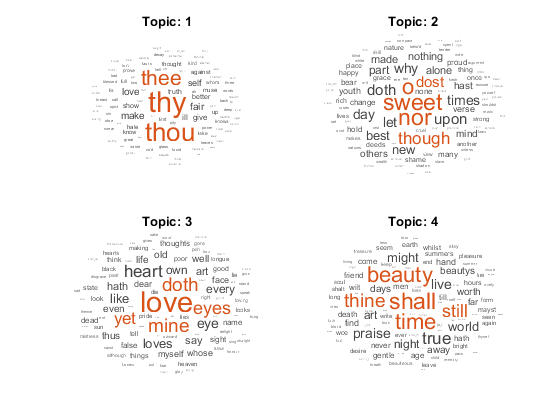
适合LDA模型到字数矩阵
将LDA模型适用于由单词计数矩阵表示的文档集合。
要重现此示例的结果,请设置rng来'默认'.
RNG('默认')
加载示例数据。sonnetsCounts.mat包含一个字数矩阵和Precosencesed版本的Shakespeare Sonnets的相应词汇。价值计数(i,j)对应的次数j词汇表中的单词出现在我文档。
负载sonnetsCounts.mat大小(数量)
ans =1×2154 3092
拟合7个主题的LDA模型。要抑制verbose输出,请设置'verbose'到0。
numTopics = 7;mdl = fitlda (numTopics计数,'verbose', 0);
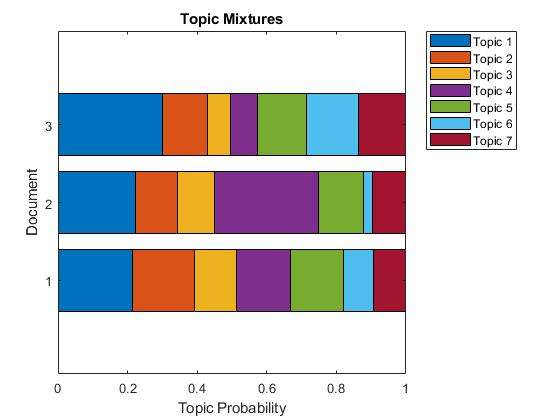
使用堆叠条形图可视化多个主题混合物。可视化前三个输入文档的主题混合。
主题xtures = transform(mdl,counts(1:3,:));图Barh(主题模拟,“堆叠”) xlim([0 1]) title(“主题混音”)包含(“主题概率”) ylabel (“文档”)传说(“主题”+字符串(1:numTopics),“位置”,“northeastoutside”)
预测文档的顶级LDA主题
要重现本例中的结果,请设置rng来'默认'.
RNG('默认')
加载示例数据。该文件sonnetspreprocessed.txt.txt.包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetspreprocessed.txt.txt.,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
使用袋式模型使用bagOfWords.
BAG = BAGOFWORDS(文件)
bag = bagOfWords with properties: Counts: [154x3092 double]词汇:[1x3092 string] NumWords: 3092 NumDocuments: 154
拟合具有20个主题的LDA模型。
numTopics = 20;numTopics mdl = fitlda(袋)
初始主题任务的采样时间为0.042481秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 0.01 | 5.000 | 1.159 e + 03 | | 0 | | 1 | 0.03 | 5.4884 e-02 e + 02 | 8.028 | 5.000 | 0 | | 2 | 0.03 | 4.7400 e 03 e + 02 | 7.778 | 5.000 | 0 | | 3 | 0.03 | 3.4597 e 03 e + 02 | 7.602 | 5.000 | 0 | | 4 | 0.03 | 3.4662 e 03 e + 02 | 7.430 | 5.000 | 0 | | 5 | 0.03 | 2.9259 e 03 e + 02 | 7.288 | 5.000 | 0 | | 6 | 0.03 | 6.4180 e-05 e + 02 | 7.291 | 5.000 | 0 |=====================================================================================
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopicprobability: [1x20 double] documenttopicprobability: [154x20 double] documenttopicprobability: [154x20 double] topicwordprobability: [3092x20 double]
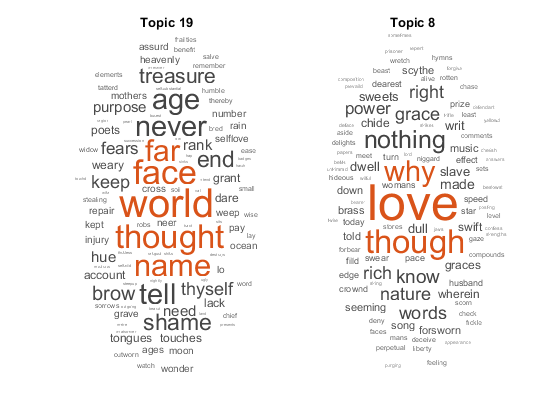
预测新文档数组的顶级主题。
newDocuments = tokenizedDocument ([“名字有什么关系呢?”玫瑰不管叫什么名字都一样芳香。”“如果音乐是爱情的食粮,那就继续演奏吧。”]);topicidx = predict(mdl,newdocuments)
topicIdx =2×119日8
使用Word云可视化预测主题。
图次要情节(1、2、1)wordcloud (mdl, topicIdx (1));标题(“主题”+ topicIdx(1) subplot(1,2,2) wordcloud(mdl,topicIdx(2));标题(“主题”+ topicIdx (2))
输入参数
输出参数
更多关于
潜在狄利克雷分配
一个潜在狄利克雷分配(LDA)模型是一个文档主题模型,在主题中发现文档和Infers Word概率集中的基础主题。LDA模型一系列D文档作为主题混合物 ,在K以单词概率向量为特征的主题 .该模型假设主题混合 ,主题 遵循具有浓度参数的Dirichlet分布 和 分别。
这个话题混合物
是长度的概率向量K, 在哪里K是主题的数量。条目
是主题的概率我中出现的d文档。主题混合对应的行DocumentTopicProbabilities财产的财产ldaModel对象。
的话题
是长度的概率向量V, 在哪里V是词汇表中的单词数。条目
对应的概率v中出现的单词我主题。的话题
对应的列TopicWordProbabilities财产的财产ldaModel对象。
考虑到主题 和Dirichlet之前 在主题混音上,LDA假定文档的以下生成过程:
尝试主题混合 .随机变量 是长度的概率向量吗K, 在哪里K是主题的数量。
对于文件中的每个单词:
示例主题索引 .随机变量z是从1到整数吗K, 在哪里K是主题的数量。
样本一个单词 .随机变量w是从1到整数吗V, 在哪里V为词汇表中单词的个数,表示词汇表中相应的单词。
在这一生成过程下,用词的文档的联合分配 ,与话题混合 ,并附有主题索引 是由
在哪里N为文档中的字数。求和联合分布z然后对 生成文件的边缘分布w:
下图说明了LDA模型作为概率图形模型。被观察到的阴影节点变量,未脉冲节点是潜在变量,没有轮廓的节点是模型参数。箭头突出显示随机变量之间的依赖性,并且板表示重复节点。

兼容性的考虑
参考
[1] Foulds,詹姆斯,Levi Boyles,Christopher Dubois,Padhraic Smyth和Max Welling。“随机折叠变分贝叶斯推论潜在的Dirichlet分配。”在第19届ACM SIGKDD知识发现和数据挖掘国际会议, 446 - 454页。ACM, 2013年。
[2] Hoffman, Matthew D., David M. Blei, Chong Wang和John Paisley。“随机变分推理”。机器学习研究杂志14,不。1(2013):1303-1347。
[3]格里菲斯,托马斯L.和马克斯泰尔弗斯。“寻找科学话题。”美国国家科学院学报101年,没有。增刊1(2004):5228-5235。
Asuncion, Arthur, Max Welling, Padhraic Smyth, and Yee Whye Teh。"关于主题模型的平滑和推理"在第25届人工智能不确定性会议论文集27-34页。AUAI出版社,2009年。
[5] Teh,Yee W.,David Newman,以及最大的好处。“潜伏的Dirichlet分配崩溃变分贝叶斯推理算法。”在神经信息处理系统的进展, 1353 - 1360页。2007.
你也可以从以下列表中选择一个网站:
