主要内容
预测
预测文档的顶级LDA主题
语法
描述
例子
预测文档的顶级LDA主题
要重现本例中的结果,请设置rng来“默认”.
rng (“默认”)
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
单词:[" fairrest " "creatures" "desire"…NumWords: 3092 NumDocuments: 154
拟合具有20个主题的LDA模型。
numTopics = 20;numTopics mdl = fitlda(袋)
初始主题任务的采样时间为0.035863秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 0.02 | 5.000 | 1.159 e + 03 | | 0 | | 1 | 0.08 | 5.4884 e-02 e + 02 | 8.028 | 5.000 | 0 | | 2 | 0.06 | 4.7400 e 03 e + 02 | 7.778 | 5.000 | 0 | | 3 | 0.05 | 3.4597 e 03 e + 02 | 7.602 | 5.000 | 0 | | 4 | 0.05 | 3.4662 e 03 e + 02 | 7.430 | 5.000 | 0 | | 5 | 0.05 | 2.9259 e 03 e + 02 | 7.288 | 5.000 | 0 | | 6 | 0.06 | 6.4180 e-05 e + 02 | 7.291 | 5.000 | 0 |=====================================================================================
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopic概率:[0.0500 0.0500 0.0500 0.0500 0.0500…词汇:[“最公平的”“生物”…TopicOrder: 'initial-fit-probability'
预测新文档数组的顶级主题。
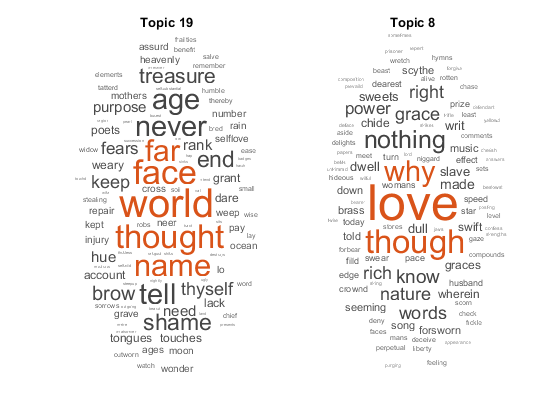
newDocuments = tokenizedDocument ([“名字有什么关系呢?”玫瑰不管叫什么名字都一样芳香。”“如果音乐是爱情的食粮,那就继续演奏吧。”]);newDocuments topicIdx =预测(mdl)
topicIdx =2×119日8
使用词云可视化预测的主题。
图次要情节(1、2、1)wordcloud (mdl, topicIdx (1));标题(“主题”+ topicIdx(1) subplot(1,2,2) wordcloud(mdl,topicIdx(2));标题(“主题”+ topicIdx (2))
预测词数矩阵的顶级LDA主题
加载示例数据。sonnetsCounts.mat包含一个单词计数矩阵和相应的词汇预处理版本的莎士比亚十四行诗。
负载sonnetsCounts.mat大小(数量)
ans =1×2154 3092
拟合具有20个主题的LDA模型。要重现本例中的结果,请设置rng来“默认”.
rng (“默认”) numTopics = 20;numTopics mdl = fitlda(计数)
初始主题分配的采样时间为0.177311秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 1.50 | 5.000 | 1.159 e + 03 | | 0 | | 1 | 0.04 | 5.4884 e-02 e + 02 | 8.028 | 5.000 | 0 | | 2 | 0.05 | 4.7400 e 03 e + 02 | 7.778 | 5.000 | 0 | | 3 | 0.03 | 3.4597 e 03 e + 02 | 7.602 | 5.000 | 0 | | 4 | 0.06 | 3.4662 e 03 e + 02 | 7.430 | 5.000 | 0 | | 5 | 0.05 | 2.9259 e 03 e + 02 | 7.288 | 5.000 | 0 | | 6 | 0.05 | 6.4180 e-05 e + 02 | 7.291 | 5.000 | 0 |=====================================================================================
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopic概率:[0.0500 0.0500 0.0500 0.0500 0.0500…词汇:["1" "2" "3" "4" "5"…TopicOrder: 'initial-fit-probability'
预测中前5个文档的顶级主题计数.
topicIdx =预测(mdl计数(1:5,:))
topicIdx =5×13 15 19 3 14
计算主题预测得分
要重现本例中的结果,请设置rng来“默认”.
rng (“默认”)
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
创建一个词袋模型使用bagOfWords.
袋= bagOfWords(文档)
单词:[" fairrest " "creatures" "desire"…NumWords: 3092 NumDocuments: 154
拟合具有20个主题的LDA模型。要抑制verbose输出,请设置“详细”为0。
numTopics = 20;mdl = fitlda(袋、numTopics、“详细”, 0);
预测新文档的顶级主题。指定迭代限制为200。
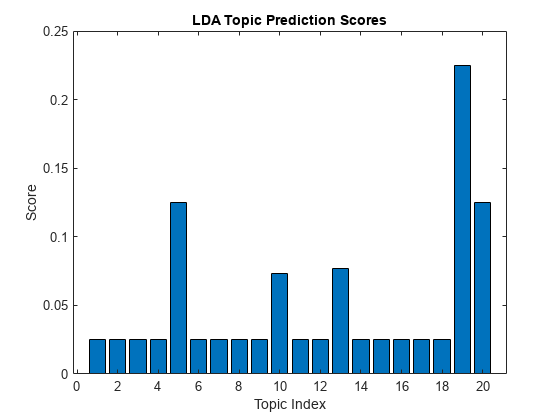
newDocument = tokenizedDocument (“名字有什么关系呢?”玫瑰不管叫什么名字都一样芳香。”);iterationLimit = 200;[topicIdx,分数]=预测(mdl newDocument,...“IterationLimit”iterationLimit)
topicIdx = 19
成绩=1×200.0250 0.0250 0.0250 0.0250 0.1250 0.0250 0.0250 0.0250 0.0250 0.0250 0.0730 0.0250 0.0250 0.0770 0.0250 0.0250 0.0250 0.0250 0.0250 0.2250 0.1250
在条形图中查看预测得分。
图酒吧(分数)标题(LDA主题预测评分)包含(“主题指数”) ylabel (“分数”)
输入参数
输出参数
介绍了R2017b
你也可以从以下列表中选择一个网站:
