egcitest
Engle-Granger协整检验
句法
[h,pvalue,stat,cvalue,Reg1,Reg2] = Egcitest(Y)
[h, pValue,统计,cValue reg1, reg2] = egcitest (Y,名称,值)
描述
Engle-Granger测试评估时间序列中没有协整的无效假设y.考试难度Y (: 1)上Y(:, 2:结束)然后测试单位根的残差。
[对数据矩阵执行恩格尔-格兰杰检验H那pValue那统计那cValue那reg1那reg2) = egcitest (y)y.
[对数据矩阵执行恩格尔-格兰杰检验H那pValue那统计那cValue那reg1那reg2) = egcitest (y那名称,价值)y具有一个或多个指定的其他选项名称,价值对参数。
输入参数
|
numobs.——- - - - - -numdims.矩阵表示numobs.观察A.numdims.维时间序列y(T.)最后的观察结果是最近的。y不能有超过12列。意见包含 |
名称值对参数
指定可选的逗号分离对名称,价值参数。的名字是参数名称和价值是相应的价值。的名字必须出现在引号内。您可以以任何顺序指定多个名称和值对参数name1,value1,...,namen,valuen.
|
字符向量,如 y1=X一种+y2B.+ε.
默认: |
|
含有系数的载体或vectors的传染媒介或细胞传染媒介[一种;B.]固定在共同化回归中。长度一种0 1 2还是3,取决于什么 默认:完全未指定的协整载体(所有NAN值)。 |
|
字符向量,如 值是:
测试统计信息是通过调用计算的 默认: |
|
非负整数的标量或向量,表示残差回归中使用的滞后数。参数的含义取决于的值 默认: |
|
字符向量,如 值是:
参数的含义取决于的值 默认: |
|
测试的名义显著性水平的标量或向量。取值必须在0.001和0.999之间。 默认:0.05 |
将单元素参数值扩展为任意向量值的长度(测试数)。矢量值必须有相等的长度。如果任何值是行向量,则所有输出都是行向量。
输出参数
|
测试的布尔决策向量,长度等于测试数。价值 |
||||||||||||||||||||||||||||||||||||||||||||||||
|
向量的P.- 测试统计值,长度等于测试数量。P.-值是左尾概率。 |
||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
测试临界值的向量,其长度等于测试数。值表示左尾概率。由于残差是估计的而不是观察的,所以临界值不同于 |
||||||||||||||||||||||||||||||||||||||||||||||||
|
协整回归的回归统计结构。 |
||||||||||||||||||||||||||||||||||||||||||||||||
|
剩余回归的回归统计结构。 中记录的数量
*滞后和差异时间序列可降低样本大小。缺少任何预先值的值,如果y(T.)被定义为T.= 1:N,然后是滞后的系列y(T.−K.)被定义为T.=K.+ 1:N.差异减少了时间基础K.+ 2:N.与P.滞后的差异,常见的时间基础是P.+ 2:N和有效的样本大小是N- (P.+ 1). |
例子
测试多个时间序列进行协整使用egcitest
加载加拿大利率期限结构的数据。
加载DATA_CANADA.Y =数据(:,3:结束);名称=系列(3:结束);情节(日期、Y)传说(名称,'地点'那“西北”网格)上
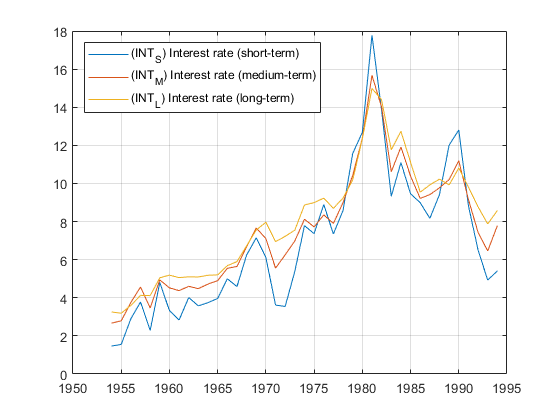
检验协整(并重现表II的第1行[3])。
[h,pvalue,stat,cvalue,reg] = Egcitest(y,“测试”那...{'t1'那't2'});h,pvalue.
h =1 x2逻辑阵列0 1
pvalue =1×20.0526 - 0.0202
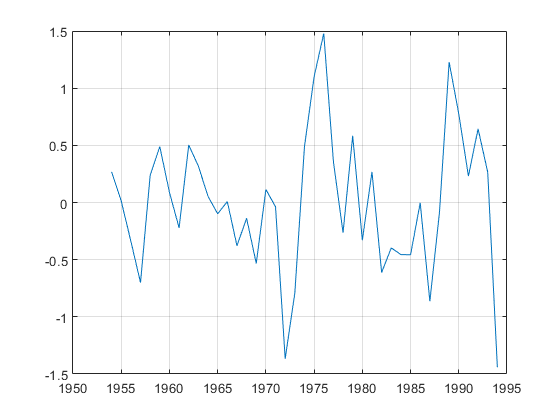
绘制估计的协整关系 .
a = reg(2).coeff(1);b = reg(2).coeff(2:3);绘图(日期,Y * [1; -B] -A)网格上
算法
适当的价值滞后必须确定才能从测试中汲取有效推论。看看关于的注意事项滞后文档中的参数安德斯特和PPTEST..
观测值小于20到40的样本(取决于数据的维数)可能产生不可靠的临界值,因此也会产生不可靠的推论。看到[3].
如果协整被推断,残差从reg1在VEC表示中,输出可作为错误校正项的数据y(T.).看到[1].然后可以进行自回归模型组件的估计估计,将残留系列视为外源性。
参考
恩格尔和c.w J.格兰杰。协整和误差校正:表示、估计和测试。费雪.第55节,1987年,第251-276页。
[2]汉密尔顿,J.D。时间序列分析.普林斯顿,新泽:普林斯顿大学出版社,1994年。
[3] Mackinnon,J.G。“单位根系和协整测试的数值分配函数。”应用经济学学报.第11卷,1996年,第601-618页。
您还可以从以下列表中选择一个网站:
