欢迎来到深度学习信号和声音。我的名字是约翰娜Pingel从产品营销,我加入了Emelie Andersson从应用程序工程。今天我们将讨论何时和为什么你可以用深度学习信号和音频数据,当然,向您展示如何通过两个例子。
有不同种类的数据,工程师一起工作,当涉及到深刻的学习和机器学习。大部分的数据类型是一个三个表格数据,时间序列数据或图像数据。深度学习历来是用于图像数据,技术第一次起飞和很不错的效果。深度学习现在已经成为其他类型的数据的工具,。这次研讨会将集中在中间部分,深度学习信号和音频数据类型。
所以你有信号和/或音频数据。你应该使用深度学习,还是经典的机器学习?这个问题出现了很多。每个人的讨论深度学习,但这是很好的对于信号和音频数据,当我应该使用机器学习而不是深度学习?让我带30秒,回答这个问题之前定义的区别。我们定义深度学习作为机器学习的一个子集,并在机器学习经典的机器学习。在这两种情况下,我们有输入数据,我们需要一个算法来学会识别信号之间的独特品质。你有输入数据,你想要的算法来生成一个输出数据。
让我们先从经典的机器学习,你手动从数据中提取相关的特性。这些特性被添加到机器学习模型分类,然后产生一个输出。深度学习,你给原始数据直接转换为深层神经网络自动学习功能。深度学习通常是用神经网络实现的架构,我们将更详细地解释使用的例子。这是一个高水平的机器学习和深度学习的区别。但问题是,我应该使用哪一个?
答案是,这取决于。也许这是你的状况。我有很多数据,但不是什么数据需要尽可能多的知识。如果是这种情况,你应该尝试深度学习。模型自学习自有特色,你,作为工程师,不需要知道尽可能多的数据,和更多的数据可能意味着一个更好的模型。也许你有一个较小的数据集。你还可以用深度学习吗?答案是,当然,去试一试。但它可能是一个机器学习模型可能会给你更好的结果。在经典的机器学习,你可以利用你的知识数据,并提取的最佳特性和适量的他们。
你可能会问,我就不能尝试两种方法——深度学习和机器学习和比较结果?答案是,是的,你可以试试。的方法可以很容易地通过观察精度相比。可以呆在MATLAB环境中创建两个机器学习和深度学习模型。在这次研讨会,我们将只是谈论深度学习的方法。但在研讨会结束后,你会发现资源使用机器学习如何做类似的事情。MATLAB中最好的部分是,你不必成为一个信号处理工程师使用信号数据,你不需要一个数据科学家使用机器学习更深的学习,。
所以,让我们开始吧。不管你的特定的深度学习问题,你将最有可能受益于典型的深度学习后工作流程。首先,您需要访问您的音频和信号数据文件从无论他们在哪里,要么只是MP3文件,数据库中的历史数据,或流媒体数据。然后你需要很多带安全标签的数据。你需要输入数据给神经网络大量的例子,所以它可以学习和理解决策的特性。所有的数据使得网络的训练非常强烈的运算。能够做这些计算更快,你可以而且应该利用gpu,使训练速度显著提升。
训练模型后,你很可能想要合并成一个更大的系统,可以允许用户通过一个应用程序调用模型,或导出模型外部硬件。你可能会考虑针对嵌入式GPU, MATLAB提供产品自动生成CUDA代码从你的模型。下载188bet金宝搏正如你可能知道,深度学习是一个反复的过程,你最有可能需要去这些步骤之间来回很多次因为各种各样的原因,可能带来更多的数据来提高模型精度,或改变的参数在部署之前,您的模型。好消息是,MATLAB提供的所有工具之间来回走了这些步骤。
标准工作流程后,我们来看看两个演示今天,两者都将展示不同的深度学习技术,你可以试一试你的数据。第一个演示是音乐一代,它使用一个LSTM网络架构。Emelie将穿过设计一个网络,可以生成旋律,最后,通过一个简短的介绍叮当,网络将能够继续这首歌根据已打了。第二个演示是关于语音去噪与严重的背景噪音,将使用一个CNN的图像。我们将培训网络,它将能够消除或减少噪声的输入,留下一个干净的语音信号。
现在,我将把它交给Emelie,谁将带您通过例子。
谢谢您,汉娜。所以,让我们开始第一个演示,音乐的一代。我们必须训练网络的数据是一个数据集的古老的民歌旋律。我们将使用的网络类型叫做LSTMs。它代表长期短期记忆。顾名思义,网络有一个天生的记忆,与几乎所有其他类型的神经网络相比,没有记忆。火车网络将被称为folkNet。我们将使用folkNet玩短歌,,让它尾随。创建一个后续的旋律。
让我们仔细看看这些类型的网络是如何工作的。“我出生在瑞典。我说——“我知道丢失的单词是瑞典语,根据上下文。LSTMs是一种递归神经网络。和复发性神经网络在进行预测时考虑到以前的数据在时间。这些类型的网络特别适合信号,音频、文本和时间序列数据。可以保存的信息发送回网络,这些循环可以为简单的可视化展现。
让我们回到这个例子中,“我出生在瑞典,然后我们可以,比方说,五页的文本。还有瑞典的环境需要一个更大的内存比秩序。所以,长期短期记忆网络很擅长这个,因为他们携带一个存储单元在整个过程。在我的演示,我将向您展示是多么容易在MATLAB中创建这些类型的网络。
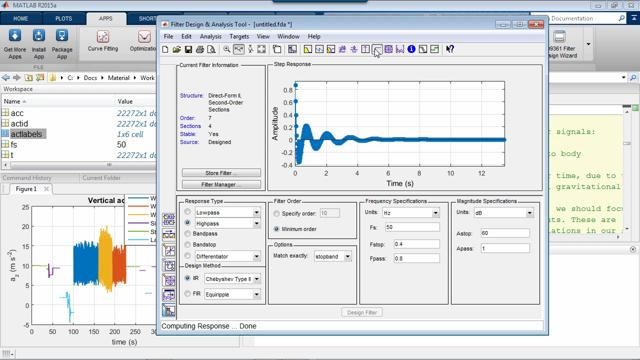
所以,我们先看看我们可以创建最终训练神经网络。在这里,我们有一架钢琴,看起来像这样。在MATLAB创建了这个程序,在这里,我可以记录一个曲子。这首曲子,旋律,将用于生成更长的随访的旋律。我可以改变温度。温度,在这种情况下,是一个技术术语,描述了类似的未来音乐将是我玩的笔记。所以温度较低意味着调整将类似于笔记,和更高的温度意味着调整会有所不同从原来的笔记。让我们把它在这。我将按矩形并开始播放“老麦克唐纳有一个农场。”
现在,我将按“让我一个曲调!”我们可以看到它开始生成一个神经的旋律。在y轴上,我们有,或注意。在x轴上,我们有时间在跳动。红色,我们有音乐,我们只是玩,和蓝色,我们有新生成的曲调。让我们玩。
我把它停在这里。所以一开始没有听起来像一个原因我们习惯是因为notes细长当我玩几个曲调。所以我打3 Gs在开始的时候,他们成为一个长音,而不是三个节拍。但很酷。在这里,我们有一个电脑的歌曲。
让我们看一看列车网络的脚本,用于生成音乐。在这个脚本中我们要做的是火车提前预测网络,这是一个网络,可以预测下一个注意当考虑到当前的注意。总之,网络将学习35种不同的笔记。我首先读的民歌旋律的数据文件夹。如果我去文件夹,我们可以看到,MIDI格式的数据。这是一个格式之间通信秩序和音乐。基本上,这些文件是数据。所以不是录制的声音。但是电脑可以使用数据笔记这首歌。
让我们玩一个MATLAB以外的旋律,让Windows媒体播放器MIDI数据转换为声音。
这些音调网络将在训练。你可能会认识到如何从这种音调听起来是我们看着中生成应用程序。
在下一节中,我们将一个旋律向量的每个数据矩阵,我们从媒体数据。我们也将摆脱文件包含和谐,和删除一些长歌。总之,我们从1034至985的旋律。所以,现在我们有旋律向量,但没有为模型预测或响应。
在本节中,我们将创建响应变量转换35 985年的每个不同的音符旋律范畴数据类型。我们将创建预测通过每个音符的哑变量,这也是一种处理分类数据,但保持它作为数值数据类型。在本节中,我们将添加一个叫做结束令牌响应数据结束的旋律。在这种情况下,我们将注意+ 1,最高就是89。这给了我们一个非常有趣的特性。现在,火车网络可以决定自己的,当它完成的时候生成一个曲调。通过添加结束每一块令牌,我们基本上是教学网络,当音乐结束了。
下一个部分分区中的数据预测和响应在训练和验证数据。我们这里的设置,我们预留10%的数据进行测试。所以训练数据将用于训练网络,和测试数据将被用来检查网络新数据的准确性。在这里,我们可以发现如果是过度拟合训练集的数据。
现在,我们终于来到了部分设计的体系结构这招LSTM预测。网络是一个序列中的第一层输入层。在这里,我们有数量35,我们有多少记录在我们的旋律。输入层后,我们将使用两个LSTM层与250隐藏的单位。这是一个相当随意的选择。然而,我们希望,通过包括两层LSTM中等数量的隐藏单元,网络能够学习足够复杂的行为学习音乐的关系。辍学层后,每个LSTM层提供一个防止过度拟合。
这些层后,我们有一个完全连接层,顾名思义,确保层有尽可能多的笔记类的数量。在这种情况下,我们这里有35数量,因为我们有35类笔记。这些softmax 35层——下一步——输出值,它确保有一个值在0和1之间。我们可以认为这是不同类别的概率分布。最后,我们有一个分类层,它只是输出概率最高的类。
在这在下一节中,我们将选择训练选项,我们将使用训练网络。1的亚当优化算法和梯度阈值选择稳定的训练过程。如果你不熟悉图层选项和训练选项,你可以学习所有关于层和MATLAB的培训方案文档。
现在我们已经到了最后一节,我们做网络的训练。我们需要添加x-train和y-train数据,连同我们设置的架构层和培训我们选择的选项。作为输出,我们将网络folkNet。在这里,我们可以看到网络培训进展,蓝色,我们有准确性,向上,幸运的是。下面的红色我们有叉multiclassification损失,这是向下。这也是好消息。我们希望损失接近0。在黑色中,我们验证数据的结果。使用这个,我们可以看到如果模型开始overfit训练数据。
所以你现在看到的这个培训已经被多次加速。需要更长的时间在现实运行。您可以看到,随着时间的推移训练集的性能改善。如果我们允许继续训练,可以获得更好的性能。但这并不能保证我们会得到一个网络生成好的音乐。相反,更有可能的是我们会有训练一个网络密切模仿训练集。
在20世纪,我们有一个验证准确性的转折点。我解释这是,网络是最普遍的,因此网络可以合理预见到看不见的作品的音乐性。在角落里,我们有一个步骤按钮。如果我按这个,我将网络权重作为他们在非常时刻,我停止训练。
这里是结果。它看起来不伟大的准确性,但在这种情况下,我们不介意。目标不是培养一个LSTM完美再现了训练数据。相反,我们的目标是培养一个LSTM生成合理的碎片。现在,我们已经完成了训练,这是网络已经放到我们music-generating钢琴应用。这里,我们看了一个例子,使用深度学习来生成新的数据通过领先一步预测。
接下来我们要做的是看看深度学习可以用来消除干扰一个已经存在的信号。而不是使用LSTMs在这个演示,我们将使用卷积神经网络,或者cnn,这正是如何训练一个网络图片。所以在这个例子中,我们有音频数据的人说话。每个序列的时间大约是一个句子的长度。训练一个降噪模型,我们将添加洗衣机噪声对纯净语音数据。语音数据干扰与噪声预测,和干净的语音数据,我们现在将响应。通过这些知识,网络将学习如何消除干扰干扰信号。
因此,正如我所说的,我们将使用一个网络类型构造图像输入数据。然而,现在,我们有音频数据。让我们用一个共同的技术创建的图像信号数据称为谱图。我们将干净数据和嘈杂的数据并将其转换成光谱图图像。色是一个傅里叶变换在短片段的数据,也称为短时傅里叶变换。这输出频率在一个轴,和时间。我们将每个光谱图的噪声音频和向后平移,所以我们最后八个连续谱图。我们将培训网络使用基于声音的图像。基本上,这些8 - - 129大小的图像只是八个频率向量连续八次。预测或估计,将基于最新的频率向量。
我们再次跳进MATLAB之前,让我们来看一个简短的cnn实际上是如何工作的。在一个非常高的水平,卷积神经网络图像中我们可以看到这里工作。我们有多个层,在许多的步骤,我们做卷积与不同大小的过滤器。第一层过滤器学会识别低级特征,如颜色和非常简单的形状。后来层将学会识别更高级的功能。
让我们跳回MATLAB。我先给你们一个例子我们可以得到最终的去噪网络。这是一个应用程序,我可以选择听上面的信号。让我们开始玩噪音信号。
这就是喧闹的信号听起来像。0分贝的信噪比,这是一个非常沉重的原始信号的失真。让我们听听去噪信号,记住我们要删除是洗衣机的噪音。
如果第二个蝴蝶结的红色落在绿色的第一,结果是给一个弓异常广泛,
这里发生了什么是噪声信号通过网络,在这里,我们有了网络的输出。我们可以听到洗衣机噪声几乎完全消失了。让我们玩清洁音频数据。
许多复杂的想法形成了彩虹。
这是最初的声音,我们将使用地面实况。我将搬到脚本,我们训练网络,执行该去噪。深度学习,我们需要一个相当大的数据集。在文件夹声音数据,我们有121000个MP3格式的声音文件。轻松地处理这些文件,我们将创建一个数据存储,这是一个对数据的指针。数据存储对象是非常小的,我们可以看到,只有8个字节。具体地说,这是一个音频数据存储,audio-specific功能。
接下来,我将选择数据的一个子集,也就是1000个文件。当然,更好的处理更大的数据集,但为了一次,我们将使用1000年。让我们读取的文件1000的数据存储,并命名为cleanAudio。
这些数据是在48千赫,但8赫兹会不够。我们创建一个采样率转换器对象,然后我会downsample清洁音频文件,以减少一些计算负载。这个信号我们将添加一些噪音。在这种情况下,它将洗衣机噪音。我们选择一个随机位置声音文件,然后我们计算噪声能力和演讲能力,嘈杂的声音会有0分贝的信噪比。正如我之前说的,这是一个相当沉重的原始信号的失真,以便清洁音频几乎是没有区别的。让我们听听这听起来像。
我会继续和策划两个信号的。我们可以看到这里的信号也有很大的不同。神经网络的目标是吵闹的音频输入和输出尽可能接近清洁音频。我提到的幻灯片,我们将使用一种称为短时傅里叶变换的技术,也被称为谱图,创建这些图像从音频信号。让我们定义参数需要做色。我们将使用256汉明窗的长度和一个重叠窗口长度的75%。在这之后,我们创建的短时傅里叶变换的谱图干净数据和使用所有嘈杂的数据我们刚才定义的参数。
我们还没有eight-segment频率矩阵。让我们创建。我展示的幻灯片,我们只创建8份我们转变一个谱图的谱图对每个时间步。这就是我们创建目标和预测。
即使我们创建了数据存储,我们仍然没有处理的所有数据。现在,让我们开始使用所有的1000个文件,我们决定保留它。这样做,我们将高数据存储到一个数组中。一系列高是多少?高行数组的数组,超过实际符合记忆——适合大数据集。当我执行一个命令集高阵列,他们仍未评价的,直到我叫收集功能。这延迟评价能使我们快速处理大型数据集。当我们最终请求的输出使用收集,MATLAB结合排队计算在可能的情况下,需要通过数据的最小数量。这也可以并行执行,如果你在你的计算机有多个核心。
在下一节中,我们将整个过程,我们做了一个文件,从阅读,获得目标和预测——所有在这个helper函数在一行。直到我们运行聚集函数实际上是运行命令。我们可以看到,MATLAB已经确定了,我们只需要做一个传递的数据能够做helper函数的计算。现在我们只是正常化预测和目标数据,在深度学习是相当标准的程序。之前,我们开始训练网络,让我们预留数据验证能够发现过度拟合。
所以,现在我们已经来到了网络体系结构。如前所述,我们将创建图像输入数据,这样我们可以利用网络类型可用于图像。让我们开始设计一个卷积神经网络。我可以把它写在代码中像我们这里,但是我也可以快速地设计应用程序称为深网络设计师。在这个程序中,我可以拖放层我感兴趣。我将开始一个图像输入层有以下尺寸,数量的特性,频率分辨率,129年段的数量和时间,这是8。之后,我抓住一个卷积层和添加一些过滤器设置,如过滤器过滤器的大小和数量。反对层是紧随其后的是归一化层,然后激活层。
con层的重复,我可以复制粘贴的应该是相同的。如果我数到最后,我们将总共有16层监狱。
我们会回归层。和计算half-mean平方误差损失。我可以按外范围,所以层排列整齐,然后我会媒体分析,在体系结构中是否存在任何错误。我得到了三个错误,他们说“输入缺失”和“失踪输出。”And I can see that they are right at the beginning of the network. So if I go back to the graph, I can see that I forgot to connect the very first layers. I connect them and I analyze again, and this time, everything is fine.
在这个网络总有48层。我使用这个架构设计,我会继续,按出口。与前面的示例中,我们将设置一些培训选项如何我们要训练该模型。我们设置了时代这三个通过数据,所以每一批包含128张图片。在这之后,我们只需要做培训。我会插入训练数据层和选项。因为它是一个回归的问题这一次,我们有蓝色的均方根误差下降而不是上升的准确性。我们可以看到,错误是稳步下降,然后压扁在略低于4一个错误。黑色的验证数据表明该模型过度拟合。
现在我们有一个培训网络,可以接触到新的数据。让我们读到一个新文件,添加一些噪声,并通过网络运行它。让我们画出干净的演讲,嘈杂的,去噪的演讲。我们可以看到,运用演讲的外观更接近清晰的演讲比吵闹的演讲。如果我们玩,我们可以听到,听起来就像在应用。
这是一个例子如何创建一个使用卷积神经网络去噪网络。这是为我做的一切。
我们希望你发现这个网络研讨会有用,有更多的例子来探索我们的网站。对信号数据深度学习的更多信息,并尝试的例子,你可以去我们的文档页面。你可以了解更多关于机器学习和深度学习解决方案在MATLAB以下链接。金宝搏官方网站谢谢你的倾听。