适合
根据数据拟合曲线或曲面
语法
描述
例子
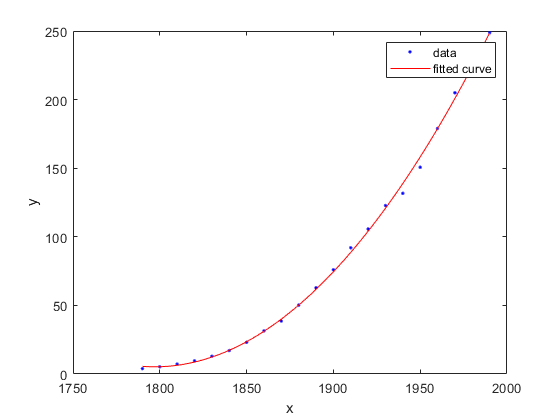
拟合二次曲线
加载一些数据,对变量拟合二次曲线cdate和流行,并绘制拟合和数据。
负载人口普查;f =适合(cdate、流行,“poly2”)
f =线性模型Poly2: f(x) = p1*x^2 + p2*x + p3系数(95%置信限):p1 = 0.006541 (0.006124, 0.006958) p2 = -23.51 (-25.09, -21.93) p3 = 2.113e+04 (1.964e+04, 2.262e+04)
情节(f cdate流行)
有关库模型名称列表,请参见fitType。
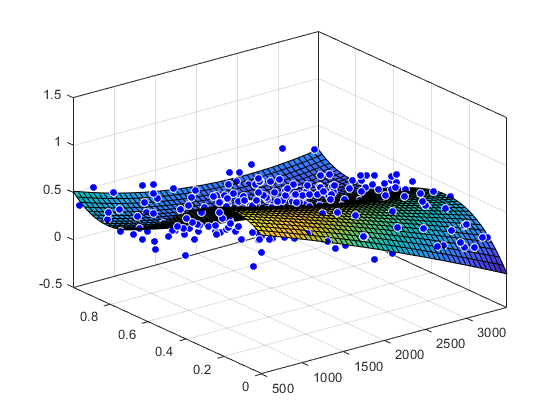
拟合多项式曲面
加载一些数据并拟合一个2次多项式曲面x和3度y。绘制拟合和数据。
负载因特网sf = fit([x, y],z,“poly23”)
线性模型Poly23:科幻小说(x, y) = p00 + p10 * x + p01 * y + p20 * x ^ 2 +侯* * y + p02 * y ^ 2 + p21 * x ^ 2 * y + p12 * x * y ^ 2 + 3 * y ^ 3系数(95%置信界限):p00 = 1.118 (0.9149, 1.321) p10 = -0.0002941 (-0.000502, -8.623 e-05) p01 = 1.533 (0.7032, 2.364) p20 = -1.966 e-08 (-7.084 e-08, 3.152 e-08)侯= 0.0003427 (-0.0001009,0.0007863)p02 p21 = -6.951 (-8.421, -5.481) = 9.563 e-08 (6.276 e-09, 1.85 e-07 p12) = -0.0004401 (-0.0007082, -0.0001721) 3 = 4.999 (4.082, 5.917)
情节(科幻,x, y, z)
使用MATLAB表中的变量拟合曲面
加载因特网数据并将其转换为MATLAB®表。
负载因特网T =表(x, y, z);
方法的输入指定表中的变量适合函数,并绘制拟合。
f = ((T。x, T。y),T.z,“linearinterp”);情节(f, [T。x, T。y),T.z )

创建适合的选项和适合类型之前,拟合
方法加载和绘制数据,创建适合的选项和适合的类型fittype和fitoptions函数,然后创建并绘制适合度。
加载并绘制数据census.mat。
负载人口普查情节(cdate、流行,“o”)

为自定义非线性模型创建一个fit选项对象和一个fit类型 ,在那里一个和b系数和n是一个问题相关的参数。
fo = fitoptions (“方法”,“NonlinearLeastSquares”,…“低”(0,0),…“上”(正无穷,max (cdate)),…曾经繁荣的[1]);英国《金融时报》= fittype (“*(取向)^ n”,“问题”,“n”,“选项”fo);
使用Fit选项和值来拟合数据n= 2。
[curve2, gof2] =适合(cdate、流行、英国《金融时报》,“问题”,2)
曲线2 =一般模型:曲线2(x) = a*(x-b)^n系数(95%置信限):a = 0.006092 (0.005743, 0.006441) b = 1789(1784, 1793)问题参数:n = 2
gof2 =结构体字段:上证综指:246.1543 rsquare: 0.9980 dfe: 19 adjrsquare: 0.9979 rmse: 3.5994
使用Fit选项和值来拟合数据n= 3。
[curve3, gof3] =适合(cdate、流行、英国《金融时报》,“问题”3)
曲线3 =一般模型:曲线3(x) = a*(x-b)^n系数(95%置信限):a = 1.359e-05 (1.245e-05, 1.474e-05) b = 1725(1718, 1731)问题参数:n = 3
gof3 =结构体字段:股票代码:232.0058平方码:0.9981 dfe: 19 adjrsquare: 0.9980 rmse: 3.4944
用数据绘制拟合结果。
持有在情节(curve2“米”)情节(curve3“c”)传说(“数据”,“n = 2”,“n = 3”)举行从

拟合一个三次多项式,指定规范化和鲁棒选项
加载一些数据,拟合并绘制一个有中心和尺度的三次多项式(正常化)和稳健的拟合选项。
负载人口普查;f =适合(cdate、流行,“poly3”,“正常化”,“上”,“稳健”,“Bisquare”)
f =线性模型Poly3: f(x) = p1*x^3 + p2*x^2 + p3*x + p4,其中x按均值1890归一化,std系数62.05(95%置信限):p1 = -0.4619 (-1.895, 0.9707), p2 = 25.01 (23.79, 26.22), p3 = 77.03 (74.37, 79.7), p4 = 62.81 (61.26, 64.37)
情节(f cdate流行)

拟合由文件定义的曲线
在文件中定义一个函数,并使用它创建适合类型和适合曲线。
在MATLAB中定义一个函数®文件。
函数y = piecewiseLine (x, a, b, c, d, k)由两部分组成的线那不是连续的。y = 0(大小(x));这个例子包括一个for循环和if语句纯粹用于举例目的。为i = 1:长度(x)如果x(i) < k, y(i) = a + b。* *(我);其他的y(i) = c + d。* *(我);结束结束结束
保存文件。
定义一些数据,创建一个指定函数的fit类型piecewiseLine,使用fit类型创建fit英国《金融时报》,并绘制结果。
x = [0.81; 0.91; 0.13; 0.91; 0.63; 0.098; 0.28; 0.55;…0.96;0.96;0.16;0.97;0.96);y = [0.17; 0.12; 0.16; 0.0035; 0.37; 0.082; 0.34; 0.56;…0.15;-0.046;0.17;-0.091;-0.071);英国《金融时报》= fittype ('piecewiseLine(x, a, b, c, d, k)'f = fit(x, y, ft,曾经繁荣的, [1, 0, 1, 0, 0.5]) plot(f, x, y)
排除拟合点
加载一些数据并拟合一个指定要排除的点的自定义方程。策划的结果。
加载数据并定义自定义方程和一些起始点。
[x, y] =钛;gaussEqn =(a * exp() -(取向/ c) ^ 2) + d '
gaussEqn = ' * exp(((取向)/ c) ^ 2) + d '
起始点= [1.5 900 10 0.6]
曾经繁荣=1×41.5000 900.0000 10.0000 0.6000
使用自定义方程和起始点创建两个fit,并使用索引向量和表达式定义两组不同的排除点。使用排除将异常值从您的fit中移除。
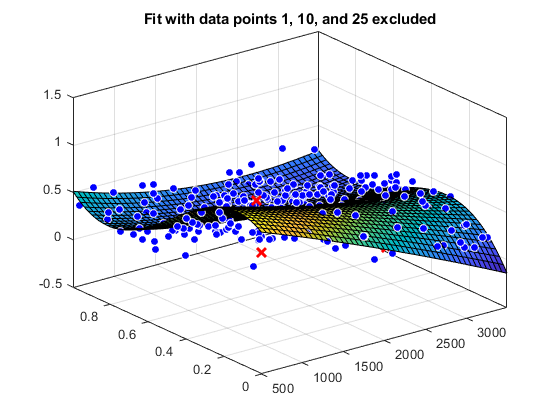
f1 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”, [1 10 25])
f1 =一般模型:f1 = a*exp(-(((x-b)/c)^2)+d系数(95%置信限):a = 1.493 (1.432, 1.554) b = 897.4 (896.5, 898.3) c = 27.9 (26.55, 29.25) d = 0.6519 (0.6367, 0.6672)
f2 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”, x < 800)
f2 =一般模型:f2(x) = a*exp(-((((x-b)/c)^2)+d系数(95%置信限):a = 1.494 (1.41, 1.578) b = 897.4 (896.2, 898.7) c = 28.15 (26.22, 30.09) d = 0.6466 (0.6169, 0.6764)
情节都适合。
情节(f1, x, y)标题(“与排除的数据点1、10和25匹配”)

图绘制(f2, x, y)标题(“不包括x < 800的数据点的拟合”)
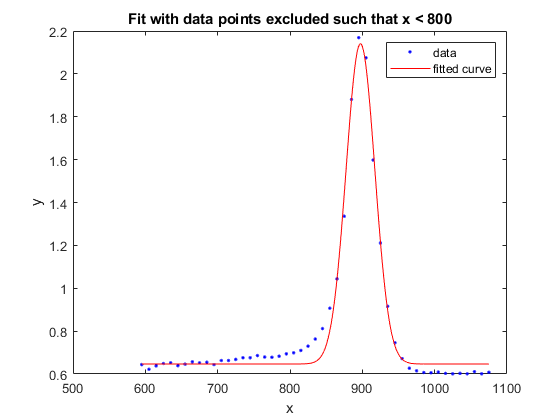
排除点和显示排除数据的图拟合
在将排除点作为输入提供给fit函数之前,可以将它们定义为变量。以下步骤将重新创建前一个示例中的适合度,并允许您绘制排除点以及数据和适合度。
加载数据并定义自定义方程和一些起始点。
[x, y] =钛;gaussEqn =(a * exp() -(取向/ c) ^ 2) + d '
gaussEqn = ' * exp(((取向)/ c) ^ 2) + d '
起始点= [1.5 900 10 0.6]
曾经繁荣=1×41.5000 900.0000 10.0000 0.6000
使用索引向量和表达式定义要排除的两组点。
exclude1 = [1 10 25];x < 800;
使用自定义等式startpoints和两个不同的排除点创建两个fit。
f1 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”,exclude1);f2 =适合(x, y, gaussEqn,“开始”曾经繁荣,“排除”,exclude2);
绘制适合并突出显示被排除的数据。
情节(f1, x, y, exclude1)标题(“与排除的数据点1、10和25匹配”)

图;情节(f2, x, y, exclude2)标题(“不包括x < 800的数据点的拟合”)

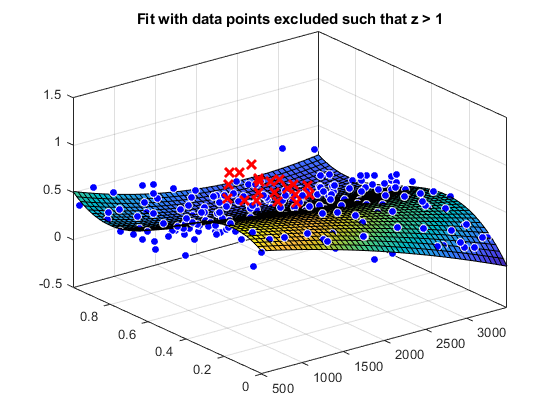
对于带有排除点的曲面拟合示例,加载一些曲面数据并创建和绘制指定排除数据的拟合。
负载因特网f1 = fit([x y],z,“poly23”,“排除”, [1 10 25]);f2 = fit([x y],z,“poly23”,“排除”, z > 1);图plot(f1, [x y], z,“排除”, [1 10 25]);标题(“与排除的数据点1、10和25匹配”)
图(f2, [x y], z,“排除”, z > 1);标题('拟合数据点排除这样的z > 1')
拟合平滑样条曲线并返回拟合信息的优度
加载一些数据,通过变量拟合平滑样条曲线月和压力,并返回拟合信息的优度和输出结构。根据数据绘制适合度和残差。
负载enso;[曲线,良品,产量]=拟合(月,压力,“smoothingspline”);情节(压力曲线、月);包含(“月”);ylabel (“压力”);

绘制x-data的残差(月)。
曲线,月份,压力,“残差”)包含(“月”)ylabel (“残差”)

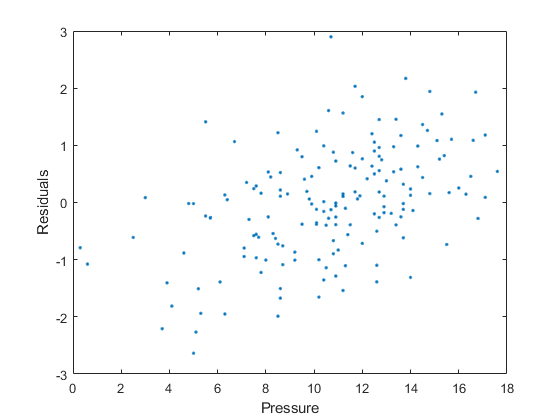
中的数据输出结构绘制残差与y数据的关系(压力)。
情节(压力、output.residuals、“。”)包含(“压力”)ylabel (“残差”)
拟合一个单项指数
生成具有指数趋势的数据,然后使用指数模型曲线拟合库中的第一个方程(单项指数)拟合数据。策划的结果。
x = (0:0.2:5)”;y = 2*exp(-0.2*x) + 0.5*randn(size(x));f =适合(x, y,“exp1”);情节(f, x, y)

使用匿名函数适合自定义模型
可以使用匿名函数更容易地将其他数据传递到适合函数。
加载数据和设置Emax来1在定义匿名函数之前:
数据= importdata (“OpioidHypnoticSynergy.txt”);异丙酚= data.data (: 1);Remifentanil = data.data (:, 2);痛觉计= data.data (: 3);Emax = 1;
将模型方程定义为匿名函数:
Effect = @(IC50A, IC50B, alpha, n, x, y)…Emax*(x/IC50A + y/IC50B + alpha*(x/IC50A)….* (y/IC50B))。^n ./((x/IC50A + y/IC50B +)…*(x/IC50A). *(y/IC50B))^ n + 1);
使用匿名函数效果作为输入适合函数,并绘制结果:
[丙泊酚,瑞芬太尼],海藻测定法,效果,…曾经繁荣的, [2, 10, 1, 0.8],…“低”, [-Inf, -Inf, -5, -Inf],…“稳健”,“守护神”)图(藻效测定法,[丙泊酚,瑞芬太尼],藻效测定法)
有关使用匿名函数和其他自定义模型进行拟合的更多示例,请参见fittype函数。
求系数顺序来设置起始点和边界
的属性上,较低的,曾经繁荣,你需要找到系数项的顺序。
创建一个合适的类型。
英国《金融时报》= fittype (" b * x ^ 2 + c * x +一个“);
得到系数的名称和顺序coeffnames函数。
coeffnames(英尺)
ans =3 x1细胞{a} {b} {' c '}
注意,这与用于创建的表达式中系数的顺序不同英国《金融时报》与fittype。
加载数据,创建一个适合并设置起点。
负载ensofit(月,压力,英国《金融时报》,曾经繁荣的,1、3、5)
ans =一般模型:ans(x) = b*x^2+c*x+a系数(95%置信区间):a = 10.94 (9.362, 12.52) b = 0.0001677 (-7.985e-05, 0.0004153) c = -0.0224 (-0.06559, 0.02079)
这赋予系数的初值如下:一个= 1,b = 3,c = 5。
或者,您可以获取fit选项并设置起点和下界,然后使用新选项进行重新设置。
选择= fitoptions(英尺)
option = Normalize: 'off' Exclude:[]权值:[]方法:'非线性最小二乘'鲁棒:'off'起始点:[1x0 double]下半部分:[1x0 double]上半部分:[1x0 double]算法:'Trust-Region' DiffMinChange: 1.0000e-08 DiffMaxChange: 0.1000 Display: 'Notify' MaxFunEvals: 600 MaxIter: 400 TolFun: 1.0000e-06 TolX: 1.0000e-06
选项。StartPoint = [10 1 3];选项。较低的=(0 -Inf 0]; fit(month,pressure,ft,options)
ans = General model: ans(x) = b*x^2+c*x+a系数(95%置信区间):a = 10.23 (9.448, 11.01) b = 4.335e-05 (-1.82e-05, 0.0001049) c = 5.523e-12(定界)
输入参数
输出参数
另请参阅
应用程序
功能
之前介绍过的R2006a
你也可以从以下列表中选择一个网站:
