预测
描述
例子
预测类标签
载入人类活动数据集。
负载humanactivity
细节的数据集,输入描述在命令行中。
适合朴素贝叶斯分类模型对整个数据集。
actid TTMdl = fitcnb(专长)
TTMdl = ClassificationNaiveBayes ResponseName:‘Y’CategoricalPredictors::[]类名(1 2 3 4 5)ScoreTransform:“没有一个”NumObservations: 24075 DistributionNames: {1} x60细胞DistributionParameters: {5} x60细胞属性,方法
TTMdl是一个ClassificationNaiveBayes模型对象代表了一个传统的训练模式。
传统训练模型转换为一个朴素贝叶斯分类模型的增量学习。
IncrementalMdl = incrementalLearner (TTMdl)
IncrementalMdl = incrementalClassificationNaiveBayes IsWarm: 1指标:[1 x2表]一会:(1 2 3 4 5)ScoreTransform:“没有一个”DistributionNames: {1} x60细胞DistributionParameters: {5} x60细胞属性,方法
IncrementalMdl是一个incrementalClassificationNaiveBayes模型对象准备增量学习。
的incrementalLearner函数初始化增量学习者通过学习条件预测分布参数,以及其他信息TTMdl从训练数据。IncrementalMdl是温暖的IsWarm是1),这意味着可以开始跟踪性能指标增量学习功能。
增量学习者从转换创建一个传统训练模型可以生成预测没有进一步处理。
所有观测使用这两种模型预测类标签。
ttlabels =预测(TTMdl壮举);illables =预测(IncrementalMdl壮举);sameLabels =总和(ttlabels ~ = illables) = = 0
sameLabels =逻辑1
为每个观察两个模型预测相同的标签。
预测标签使用Chunk-Specific误分类代价
这个例子展示了如何应用错误分类标签的成本预测传入的数据块,同时保持一个平衡的误分类代价进行训练。
载入人类活动数据集。随机洗牌数据。
负载humanactivityn =元素个数(actid);rng (10);%的再现性idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
创建一个朴素贝叶斯分类模型的增量学习。指定类名。模型的准备预测通过拟合模型前10的观察。
Mdl = incrementalClassificationNaiveBayes(类名=惟一(Y));initobs = 10;Mdl =适合(Mdl X (1: initobs,:), Y (1: initobs));canPredict =大小(Mdl.DistributionParameters 1) = =元素个数(Mdl.ClassNames)
canPredict =逻辑1
考虑严重惩罚模型分类“运行”(第4类)。创建一个成本矩阵,应用100倍处罚分类分类相比其他类运行。行对应于真实的类,和列对应于预测类。
k =元素个数(Mdl.ClassNames);成本= 1 (k) -眼(k);成本(4:)=成本(4:)* 100;%的处罚分类“运行”成本
成本=5×50 1 1 1 1 1 0 1 1 1 1 1 0 1 1 100 100 100 0 100年1 1 1 1 0
模拟数据流,并执行以下行动在100年每个传入的观察。
调用
预测预测标签为每个传入的块的观察数据。调用
预测再一次,但是通过使用指定错误分类的成本成本论点。调用
适合以适应模型的一部分。覆盖前面的增量式模型与一个新安装的观察。
numObsPerChunk = 100;nchunk =装天花板((n - initobs) / numObsPerChunk);标签= 0 (n, 1);cslabels = 0 (n, 1);中科= 0 (n, 5);cscst = 0 (n, 5);%增量学习为j = 1: nchunk ibegin = min (n, numObsPerChunk * (j - 1) + 1 + initobs);iend = min (n, numObsPerChunk * j + initobs);idx = ibegin: iend;[标签(idx), ~,春秋国旅(idx:)] =预测(Mdl X (idx:));[cslabels idx), ~, cscst (idx:)] =预测(Mdl X (idx:),成本=成本);Mdl =适合(Mdl X (idx:), Y (idx));结束标签标签= ((initobs + 1):结束);cslabels = cslabels ((initobs + 1):结束);
比较预测类之间的分布预测方法通过绘制直方图。
图;直方图(标签);持有在直方图(cslabels);传奇([“违约成本预测”厂商“预测”])
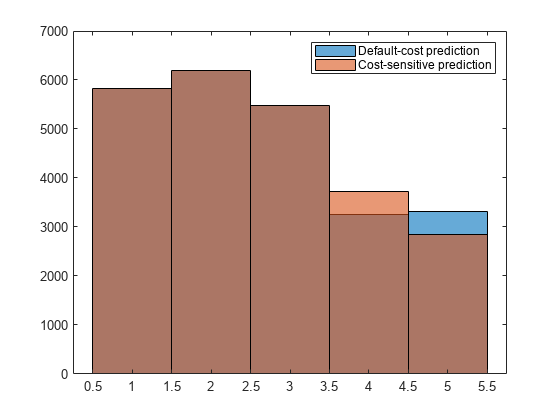
因为厂商预测方法惩罚将第4类划分那么严重,更多的预测到第4类结果相比,使用默认的预测方法,平衡的成本。
计算后验概率类
载入人类活动数据集。随机洗牌数据。
负载humanactivityn =元素个数(actid);rng (10)%的再现性idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
细节的数据集,输入描述在命令行中。
创建一个朴素贝叶斯分类模型的增量学习。指定类名。模型的准备预测通过拟合模型前10的观察。
Mdl = incrementalClassificationNaiveBayes (“类名”,独特的(Y));initobs = 10;Mdl =适合(Mdl X (1: initobs,:), Y (1: initobs));canPredict =大小(Mdl.DistributionParameters 1) = =元素个数(Mdl.ClassNames)
canPredict =逻辑1
Mdl是一个incrementalClassificationNaiveBayes模型。所有的属性是只读的。模型配置为生成预测。
模拟数据流,并执行以下行动在100年每个传入的观察。
调用
预测计算类的后验概率为每个传入的块的观察数据。调用
rocmetrics计算ROC曲线下的面积(AUC)使用类的后验概率,并存储AUC值,平均超过所有类。这AUC是一个增量测量的模型平均预测的活动。调用
适合以适应模型的一部分。覆盖前面的增量式模型与一个新安装的观察。
numObsPerChunk = 100;地板nchunk = ((n - initobs) / numObsPerChunk);auc = 0 (nchunk, 1);classauc = 5;%增量学习为j = 1: nchunk ibegin = min (n, numObsPerChunk * (j - 1) + 1 + initobs);iend = min (n, numObsPerChunk * j + initobs);idx = ibegin: iend;[~,后]=预测(Mdl X (idx:));mdlROC = rocmetrics (Y (idx)后,Mdl.ClassNames);[~,~,~,auc (j)] =平均(mdlROC,“微”);Mdl =适合(Mdl X (idx:), Y (idx));结束
现在,Mdl是一个incrementalClassificationNaiveBayes模型对象培训中的所有数据流。
情节的AUC值每个传入的数据块。
情节(auc) xlim ([0 nchunk]) ylabel (“AUC”)包含(“迭代”)
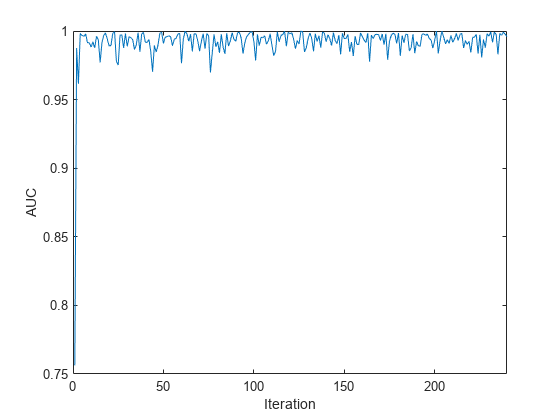
情节表明,该分类器预测在增量学习的活动。
输入参数
输出参数
更多关于
版本历史
介绍了R2021a